Уважаемый читатель Дзен-канала "Думай, Человек"!
В этой статье я продолжаю серию публикаций о том, что же такое "вероятностное мышление". Как правило, у нас взрослые и вполне образованные люди больше знакомы с логическим мышлением, в котором выводы строго и однозначно вытекают из логических посылок. А вот вероятностному мышлению не учат ни в школе, ни в большинстве вузов.
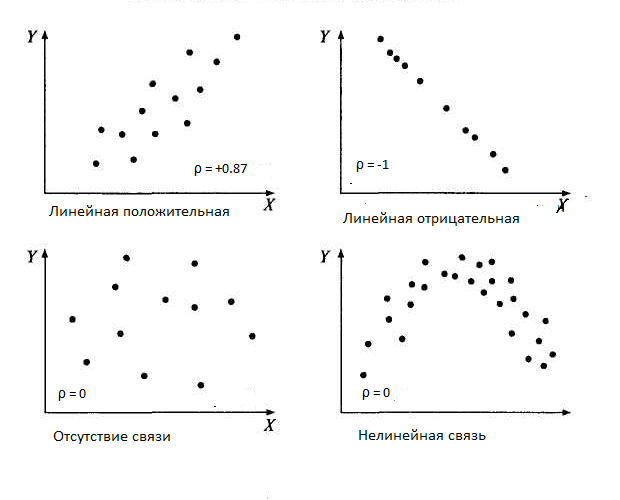
ЧЕМ ВЕРОЯТНОСТНОЕ МЫШЛЕНИЕ ОТЛИЧАЕТСЯ ОТ ОДНОЗНАЧНОЙ ЛОГИКИ?
А что же такое вероятностное мышление? - А это особый тип мышления, когда выводы следуют лишь с определенной долей вероятности, причем несколько разных выводов с разной вероятностью. В этом смысле эти выводы правильней называть даже не термином "выводы", а термином - "вероятностные гипотезы". Поэтому вероятностно-статистическое мышление - это работа с альтернативными гипотезами, с их принятием и отвержением на определенном уровне вероятностной надежности (или вероятности ошибки). Понятно, что правильней брать в качестве "рабочей" гипотезы (основной) ту, которая имеет наибольшую вероятность оказаться истиной, то есть это и будет "вероятностно-оптимальное решение".
Ниже в этой статье я делюсь своим опытом преподавателя - тем, как
я преподавал азы математической статистики студентам гуманитарного профиля. Им необходимы были числовые примеры, чтобы осмыслить хотя бы на самом приближенном уровне абстрактные понятия.
КОРРЕЛЯЦИЯ
Одно из ключевых понятий математической статистики - это понятие статистической связи, или корреляции. Некоторым кажется, что они вполне понимают, что это такое, но как только коснемся реальных проблемных ситуаций, тут же выясняется, что понимание оказывается слишком поверхностным и неточным. Некоторые путают корреляционную связь с причинно-следственной связью, отождествляют эти два разных понятия. Другие, наоборот, противопоставляют корреляционную связь и причинно-следственную. На самом деле истина лежит ни на одном, ни на другом полюсе.
Каких только критических аргументов против коэффициентов парной корреляции не наслышались люди, далекие от реальной статистической аналитической работы. Они почти наверняка слышали, что на основе сильного коэффициента (который приближается к 1) еще нельзя сказать, какая из двух переменных является причиной, а какая следствием, что причиной может вообще не быть ни одна из двух переменных, а какая-то третья, наслышались и о том, что бывают "ложные корреляции" (следствие ошибок при формировании выборки). А уж если коэффициент оказывается низким (ниже 0,5, то есть ближе к 0, чем к 1), то тут некоторые горячие головы делают категоричный вывод: такой низкий коэффициент БЕСПОЛЕЗЕН, ибо слишком много ошибок возникает в ходе прогнозирования событий на основе такого низкого коэффициента (!)
На самом-то деле, если рассуждать трезво и не поддаваться ни на какие эмоции и провокации (со стороны людей, желающих оправдать свое нежелание работать со статистикой), то статистически значимый коэффициент (отличный от нуля неслучайным образом) является НЕОБХОДИМЫМ свидетельством наличия какой-то причинной связи. Необходимым, но не достаточным для выбора одной из нескольких вероятностно-статистических гипотез:
1) причиной может быть переменная А;
2) причиной может быть переменная В;
3) причиной может быть третья переменная С, которая влияет на А и на В одновременно.
Как видим, возникает целый веер возможностей и не стоит пренебрегать этим сужением поиска. Ведь в отсутствие корреляции этот веер возможных гипотез вообще НЕ возникает (!). Да, значимый КК - это недостаточное условие для вывода о той или иной причинно-следственной связи, но отсутствие КК - это важная информация о том, что в этом поле - в поле двух переменных - не надо вообще искать уже никакой связи (!).
А что же такое поле переменных? Это метафора или можно его себе представить и построить геометрически? - Оказывается можно!
Сегодня мы оставим в стороне острые эпидемиологические примеры, подобные тому, которые рассматривали в прошлом году о "корреляционном поле", в котором точками обозначали разные страны, а по осям отражались значения двух переменных: "количество заболевших ковидом" и "количество прививок". Оказалось, что чем больше прививок, тем больше заболевших, то есть имеем статистический парадокс, от которого нельзя просто отмахнуться. А сегодня... рассмотрим более нейтральный и спокойный пример корреляционного поля на параметрах РОСТ и ВЕС.
КОРРЕЛЯЦИОННОЕ ПОЛЕ В ПРОСТРАНСТВЕ "РОСТ-ВЕС"
Итак, в течение 40 лет работы со студентами-психологами в МГУ (а также в ходе множества семинаров-вебинаров по повышению квалификации взрослых "эйчаров-оценщиков") мне не раз приходилось убеждаться, что трудности понимания вероятностной-статистической логики уходят корнями в забытые (или даже никогда не освоенные) представления из программы 6-го класса средней школы - о декартовой системе координат X и Y. Не освоено всего на всего понимание того, что означает расположение точки в том или ином координатном углу этого пространства (!). Не освоено понимание того, что такое вообще точка, что именно она обозначает. Не освоено, как местоположение точки задано ортогональными (перпендикулярными) проекциями на оси.
А ведь точка в тестологии - это обозначение ... человека, точней - обследованного (протестированного) по нескольким параметрам (!).
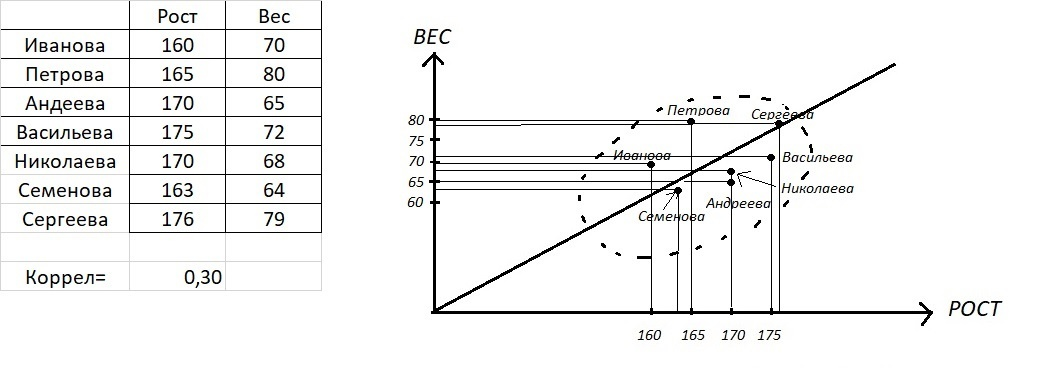
Представим для наглядности всем известные простейшие параметры "рост" и "вес". На рисунке точка, которая обозначает обследованную условную женщину Петрову, лежит выше идеальной прямой Вес = Рост -100, так как у Петровой явно имеется лишний вес - лишних 15 кг, так как при росте в 165 см она должна была бы весить 65 кг, а весит 80.
Точно также определено местоположение остальных 6 обследованных женщин в этом пространстве "рост - вес". Все эти 7 точек образуют так называемое "корреляционное поле", или "эллипсоид рассеяния". Эллипсоид, как видим, вытянут вдоль линии, обозначающей функциональную зависимость веса от роста. Чем сильней сплющен этот эллипсоид, тем выше корреляционная зависимость. В предельном случае эллипсоид вырождается в прямую линию и тогда достигается максимальное значение коэффициента корреляции, равное 1. А в данном числовом примере корреляция равна 0,3. Можете сами вставить приведенную таблицу в Эксель и посчитать функцию "коррел" для двух столбцов, и получите тогда сами 0,3.
Полезное упражнение: исключите случай "Петрова" из таблицы и посчитайте корреляцию по оставшимся в таблице 6 парам значений. Тогда получите другое значение коэффициента! Какое? - Вот и постарайтесь спрогнозировать (см. опрос). Эксель позволяет выдвигать прогнозы и тут же проверять, верными ли эти прогнозы оказались. Если Вы можете предсказывать изменение значений какой-то формулы при изменении входных данных,то значит Вы начали понимать, как работает формула и что она обозначает. В данном случае именно так проще всего достичь понимания того, что означает КОРРЕЛЯЦИЯ (!).
ПРИЧИННЫЕ ГИПОТЕЗЫ НА ОСНОВЕ КОРРЕЛЯЦИИ
А вот теперь попробуйте самостоятельно взвесить, какая из двух причинных гипотез является более вероятной:
а) Рост влияет на вес,
б) Вес влияет на рост.
Вам не кажется, что в данном случае выбор одной из двух гипотез - это нетрудная задача? Главное - это тот факт, что мы получили и доказали наличие корреляции, хоть и не равной 1 и даже меньше, чем 0,5, но этого достаточно, чтобы понять, какая из двух переменных является причиной.
Кстати, если возвращаться к указанному выше статистическом парадоксу из области эпидемиологии, то может быть, все дело в том, что прививок больше делают в той стране, где обнаруживается больше больных? То есть "количество больных" является причиной: там, где больше больных, там делают больше прививок.
Но... о том, как более обоснованно выбирать причину мы поговорим в следующий раз. Будем говорить о том, как в этом вопросе помогают так называемые "лонгитюдные данные" - несколько измерений двух переменных в разные моменты времени.
* * *
В нашей ДПМШ (Дистанционной ПсихоМетрической Школе) мы даем удобную интерактивную онлайн-программу, которая позволяет перемещать точки в пространстве двух координат, скучивать их в каком-то координатном углу и тут же смотреть, как компьютер пересчитывает коэффициент корреляции и сколько точек попадает в 4 координатных угла, которым соответствуют клеточки ЧТС - четырехклеточной таблицы сопряженности.
Запись на наш летний курс ДПМШ уже идет. См. в комментарии гиперссылку.