Вот простой пример того, как вы можете использовать BeautifulSoup для извлечения данных из HTML-страницы:
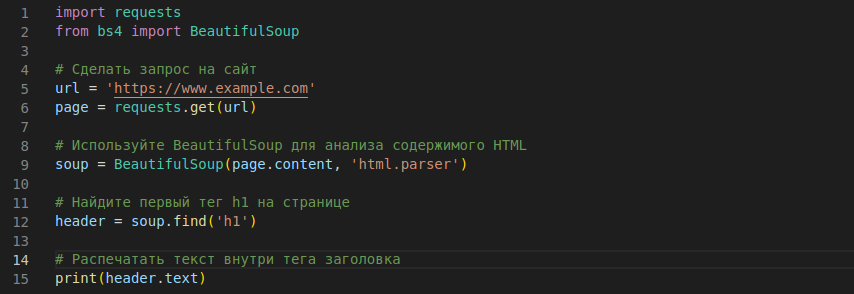
В этом примере мы сначала делаем запрос к веб-сайту с помощью requestsбиблиотеки, а затем используем BeautifulSoup для анализа HTML-содержимого страницы. Наконец, мы находим первый h1 тег на странице с помощью findметода и печатаем его текстовое содержимое.
BeautifulSoup — это популярная библиотека Python для просмотра веб-страниц, которая помогает извлекать данные из файлов HTML и XML. Он предоставляет простой в использовании интерфейс для извлечения данных из этих файлов, позволяя разработчикам сосредоточиться на важных данных, которые они пытаются извлечь, вместо того, чтобы увязнуть в тонкостях разбора HTML и XML.
Вот как это работает:
Загрузите файл HTML или XML: вы можете загрузить файл HTML или XML с помощью BeautifulSoupконструктора и передать содержимое файла и тип анализатора, который вы хотите использовать. Например, чтобы загрузить файл HTML с помощью встроенного html.parser, вы должны написать следующий код:

Навигация по дереву синтаксического анализа: после того, как вы загрузили файл, BeautifulSoup проанализирует его и создаст древовидную структуру, по которой вы сможете перемещаться. Вы можете использовать различные методы, такие как find, find_all, select, и другие, для поиска определенных тегов и элементов в дереве синтаксического анализа.
Например, чтобы найти все pтеги в файле, вы можете написать:
Извлечение данных: как только вы нашли интересующие вас элементы, вы можете извлечь нужные данные. Например, чтобы извлечь текст внутри тега, вы можете получить доступ к text атрибуту:
В этом примере header.textбудет содержать текст внутри первого h1тега в файле.
Это основные шаги использования BeautifulSoup для извлечения данных из файлов HTML и XML. Используя эти простые методы и идиомы Pythonic, BeautifulSoup упрощает извлечение и обработку данных из этих типов файлов, и это отличный инструмент для парсинга веб-страниц.