
Гетероскедастичность – допущение о "неодинаковости" Дисперсии (Variance) переменной:
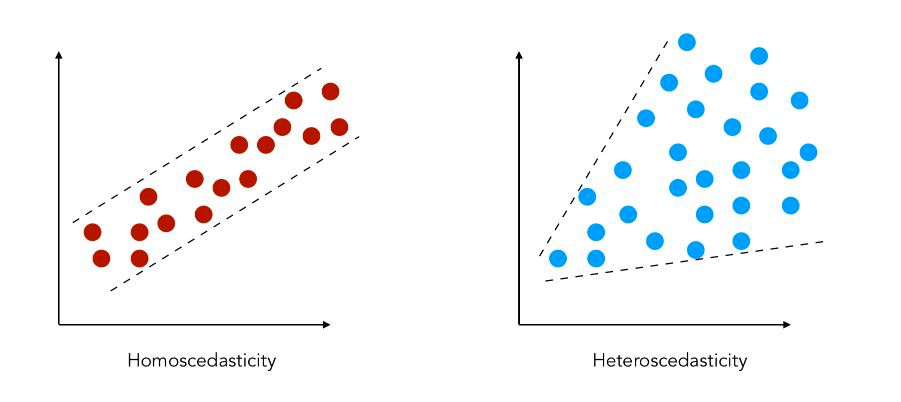
Иными словами, разность между реальным и предсказанным значениями Y, скажем, Линейной регрессии (Linear Regresion) не остается в определенном известном диапазоне. Такой "разброс" не позволяет в принципе использовать такую Модель (Model). Это проблема, потому нарушается базовое предположение о линейной регрессии: все ошибки должны иметь одинаковую дисперсию.
Самый простой способ узнать, присутствует ли гетероскедастичность, – построить график остатков (подробнее здесь):
Если наблюдения располагаются на графике остатков неравномерно (часто конусообразно), то гетероскедастичность есть.
Типичные причины гетероскедастичности:
- Большая дисперсия в переменной. Другими словами, когда наименьшее и наибольшее значения в переменной слишком экстремальны. Это также могут быть Выбросы (Outlier) – наблюдения, сильно удаленные от других.
- Неверный выбор модели: если вы подгоните модель линейной регрессии к нелинейным данным, это приведет к гетероскедастичности.
- Когда данные неправильно преобразованы
Чистая и нечистая гетероскедастичность
Теперь, по вышеуказанным причинам, гетероскедастичность может быть чистой или нечистой. Когда мы подбираем правильную модель (линейную или нелинейную) и если еще есть видимая закономерность в остатках, это называется чистой гетероскедастичностью.
Однако, если мы подбираем неправильную модель, а затем наблюдаем закономерность в остатках, то это случай нечистой гетероскедастичности. В зависимости от типа гетероскедастичности необходимо принимать меры по ее преодолению. На этот процесс влияет область, в котором мы работаем.
Эффекты гетероскедастичности в машинном обучении
Как мы обсуждали ранее, модель линейной регрессии делает предположение о наличии в данных Гомоскедастичности (Homoscedascicity), т.е. равномерно распределенных остатков. Если это предположение будет нарушено, мы не сможем доверять полученным результатам.
Если присутствует гетероскедастичность, то экземпляры с высокой дисперсией будут иметь большее влияние на прогноз.
Наличие гетероскедастичности делает коэффициенты менее точными, и, следовательно, правильные коэффициенты находятся дальше от значения генеральной совокупности.
Как лечить гетероскедастичность?
Если мы обнаружим наличие гетероскедастичности, то есть несколько способов справиться с ней. Во-первых, давайте рассмотрим пример, в котором у нас есть 2 переменные: население города и количество заражений COVID-19.
Будет огромная разница в количестве инфекций в крупных мегаполисах по сравнению с небольшими городами. Теперь первым шагом будет выявление источника гетероскедастичности. В нашем случае это переменная с большой дисперсией.
Существует несколько способов борьбы с гетероскедастичностью, но мы рассмотрим три:
- Манипуляции с переменными: мы можем внести некоторые изменения в переменные, чтобы уменьшить влияние большой дисперсии на прогнозы. Один из способов – привести значения к процентам, то есть нормализовать. В нашем случае, изменим признак «Количество заражений» на «Долю заражений». Это поможет уменьшить дисперсию, так как совершенно очевидно, что количество инфекций в городах с большим населением будет большим.
- Взвешенная регрессия — модификация обычной регрессии, при которой точкам присваиваются определенные Веса (Weights) в соответствии с их дисперсией. Те, у которых большая дисперсия, получают маленькие веса, а те, у которых меньше дисперсии, получают большие веса.
- Преобразование данных – последнее средство, так как при этом мы теряем интерпретируемость и не можем легко объяснить, что показывает эта переменная. Яркий пример – Логарифмирование (Log Transformation) – действие, обратное возведению в степень. Логарифм числа x по основанию а это показатель степени, в которую нужно возвести а, чтобы получить x.
Автор оригинальной статьи: Pavan Vadapalli
Подари чашку кофе дата-сайентисту ↑