Если бы не было статистики, мы бы даже не подозревали о многом, как говорится, в том числе о том, как хорошо мы работаем.
Статистика сегодня охватывает все области деятельности и знаний, не обошла она стороной и биомед, где она также позволяет анализировать данные, проверять достоверность и делать прогнозы.
Сразу оговоримся о пересечении терминов статистики и теории вероятностей и из взаимосвязи. Связь математической статистики с теорией вероятностей имеет в разных случаях различный характер. Теория вероятностей изучает не любые массовые явления, а явления случайные и именно «вероятностно случайные», т. е. такие, для которых имеет смысл говорить о соответствующих им распределениях вероятностей. Тем не менее, теория вероятностей играет определенную роль и при статистическом изучении массовых явлений любой природы, которые могут не относиться к категории вероятностно случайных. Это осуществляется через основанные на теории вероятностей теорию выборочного метода и теорию ошибок. В этих случаях вероятностным закономерностям подчинены не сами изучаемые явления, а приемы их исследования.
Более важную роль играет теория вероятностей при статистическом исследовании вероятностно случайных явлений. Здесь в полной мере находят применение такие основанные на теории вероятностей разделы математической статистики, как проверка статистических гипотез, статистическое оценивание распределений вероятностей и входящих в них параметров и т. д. Область же применения этих более глубоких статистических методов значительно уже, т. к. здесь требуется, чтобы сами изучаемые явления были подчинены достаточно определенным вероятностным закономерностям. Например, статистическое изучение режима турбулентных водных потоков или флуктуаций в радиоприемных устройствах производится на основе теории стационарных случайных процессов. Однако применение той же теории к анализу экономических временных рядов может привести к грубым ошибкам в виду того, что входящее в определение стационарного процесса допущение наличия сохраняющихся в течении длительного времени неизменных распределений вероятностей в этом случае, как правило, совершенно неприемлемо.
Вероятностные закономерности получают статистическое выражение (вероятности осуществляются приближенно в виде частот, а математические ожидания – в виде средних) в силу закона больших чисел.
Основные термины и понятия
Статистический показатель - это, фактически, количественная оценка любого процесса и явления, и с.п. бывают, соответственно, аналитические и учётно-оценочные.
Рассмотрим меры центральной тенденции:
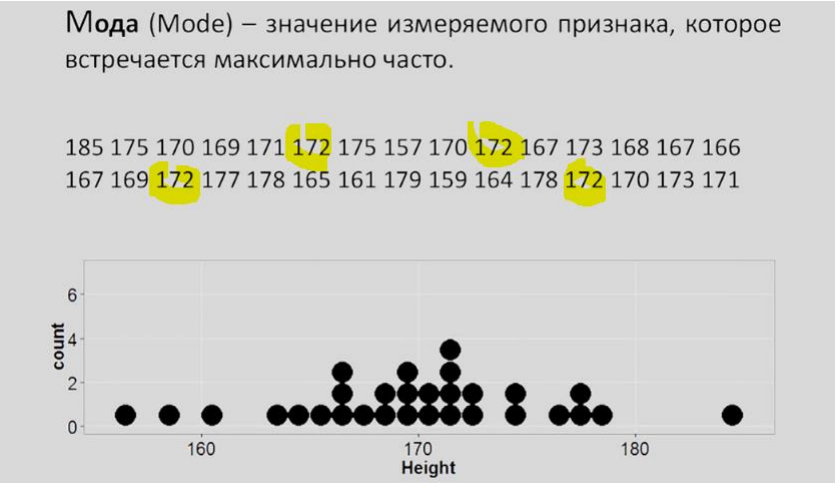

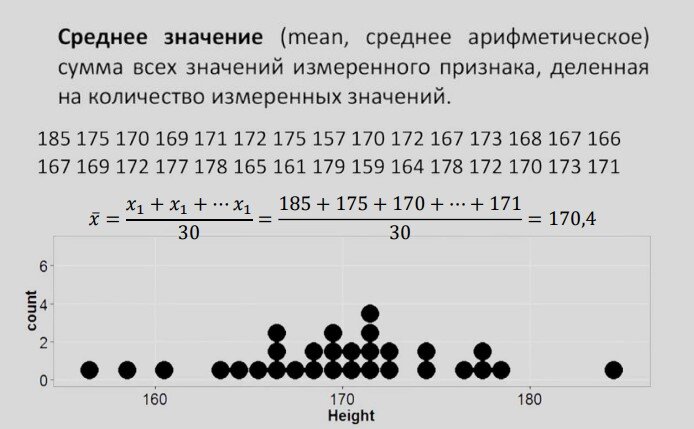
Рассмотрим также меры изменчивости:
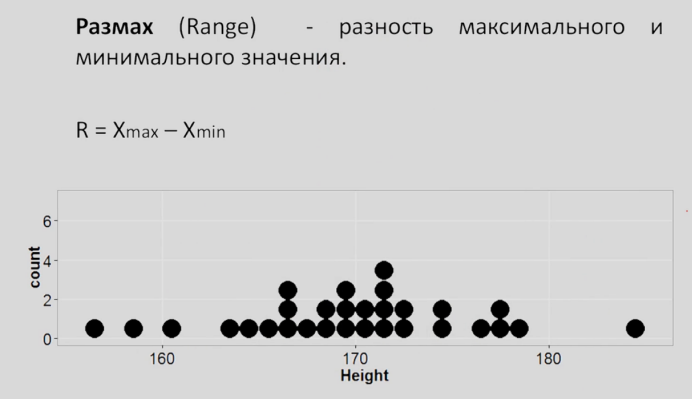
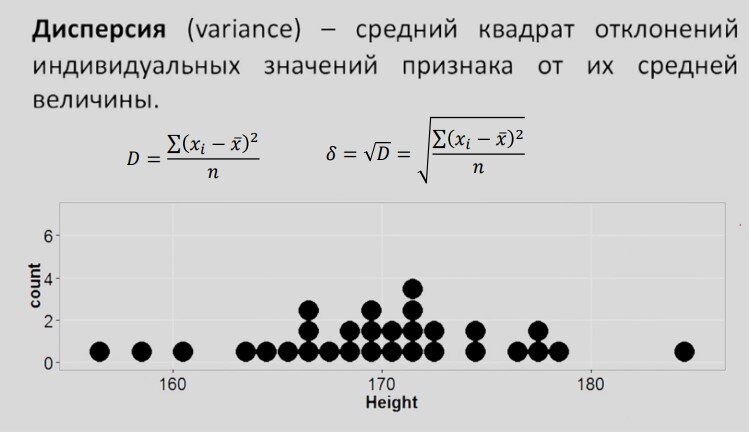
Это такие приятные термины, которые все слышали.
С математическим ожиданием связано нормальное распределение. Математическим ожиданием дискретной случайной величины называ-ется сумма произведений ее возможных значений на соответствующие им вероятности:
М(Х) = х1р1 + х2р2 + … + хпрп .
Если число возможных значений случайной величины бесконечно, то , если полученный ряд сходится абсолютно.
Обозначается через E [X] (например, от англ. Expected value или нем. Erwartungswert); в русскоязычной литературе также встречается обозначение M[X] (возможно, от англ. Mean value или нем. Mittelwert, а возможно от «Математическое ожидание»). В статистике часто используют обозначение mu.
Распределение
Эмпирическая функция распределения
Корреля́ция - статистическая взаимосвязь двух или более случайных величин. Математической мерой корреляции является коэффициент корреляции, он изменяется от -1 (отрицательная корреляция) до +1 (положительная корреляция). Если он равен 0, то это говорит об отсутствии корреляционных связей между переменными.
Случайная величина — переменная, значения которой представляют собой численные исходы некоторого случайного феномена или эксперимента. Другими словами, это численное выражение результата случайного события.
Корреляционный анализ — метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными. Корреляционный анализ тесно связан с регрессионным анализом (также часто встречается термин «корреляционно-регрессионный анализ», который является более общим статистическим понятием), с его помощью определяют необходимость включения тех или иных факторов в уравнение множественной регрессии, а также оценивают полученное уравнение регрессии на соответствие выявленным связям (используя коэффициент детерминации).
Регрессио́нный анализ — набор статистических методов исследования влияния одной или нескольких независимых переменных X1,X2,...,Xp (независимая переменная намеренно манипулируется или выбирается с целью выяснить её влияние на зависимую) на зависимую переменную Y (Зависимая переменная — в научном эксперименте измеряемая переменная, изменения которой связывают с изменениями независимой переменной).
Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными или регрессантами. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных, а не причинно-следственные отношения. Наиболее распространённый вид регрессионного анализа — линейная регрессия, когда находят линейную функцию, которая, согласно определённым математическим критериям, наиболее соответствует данным. Например, в методе наименьших квадратов вычисляется прямая(или гиперплоскость), сумма квадратов между которой и данными минимальна.
Распределение вероятностей — это закон, описывающий область значений случайной величины и соответствующие вероятности появления этих значений.
Распределения:
Цитата: "Практически, куда ни плюнь – там гауссово распределение. И это, между прочим, не метафора! Если начать куда-нибудь плевать, то плевки будут распределяться именно по Гауссу. Поэтому не будет преувеличением сказать, что куда ни плюнь – там гауссово распределение."
Распределение Гаусса (Gaussian distribution) − плотность распределения вероятностей случайной величины n. Это непрерывное распределение с пиком в центре и симметричными боковыми сторонами, которое в одномерном случае задаётся функцией плотности вероятности, совпадающей с функцией Гаусса:
В сети встречается несколько видов записи формулы, однако после преобразований, всегда можно получить единый вид.
И тут стоит вспомнить о математическом ожидании (expected value also called expectation, expectancy, mathematical expectation, mean, average, or first moment). На практике математическое ожидание обычно оценивается как среднее арифметическое наблюдаемых значений случайной величины (выборочное среднее, среднее по выборке). Доказано, что при соблюдении определенных слабых условий (в частности, если выборка является случайной, то есть наблюдения являются независимыми) выборочное среднее стремится к истинному значению математического ожидания случайной величины при стремлении объема выборки (количества наблюдений, испытаний, измерений) к бесконечности.
Для случайной величины, принимающей значения только 0 или 1 математическое ожидание равно p — вероятности «единицы». Математическое ожидание суммы таких случайных величин равно np, где n — количество таких случайных величин.
Некоторые случайные величины не имеют математического ожидания, например, случайные величины, имеющие распределение Коши.
Статистика - это наука, она не терпит приблизительности.
Поэтому заглянем в вику:
Другие распределения могут выглядеть на такими равномерными, бывают непрерывные и дискретные распределения, но не будем вдаваться.
Кривая нормального распределения имеет следующие свойства:
- колоколообразна (унимодальна);
- симметрична относительно среднего;
- сдвигается вправо, если среднее увеличивается, и влево, если среднее уменьшается (при постоянной дисперсии).
Среднее арифметическое, мода и медиана при нормальном распределении равны и соответствуют вершине распределения:
Однако, если какой-либо фактор играет преобладающую роль, то распределение не будет подчиняться Гауссову закону. Например, при исследовании показателя сахара крови для больных сахарным диабетом кривая распределения, имеющая симметричную форму для совокупности здоровых пациентов, станет несимметричной, и ее максимум сместится вправо (левостороннее асимметричное распределение).
При асимметричном распределении данных наиболее полезной мерой центральной тенденции становится медиана. Это связано с тем, что на простую среднюю арифметическую сильно влияют экстремальные (очень высокие или очень низкие) значения, из-за чего она может стать причиной неверной интерпретации результатов. Медиана же менее подвержена влиянию экстремальных величин.
Обратное расположение имеет место при левосторонней асимметрии графика. При этом, чем больше асимметричен график, тем больше расстояние между его средними точками.
Проиллюстрируем важность выбора медианы, а не среднего арифметического значения на следующем примере. График заработной платы для жителей России имеет правостороннее асимметричное распределение (большинство людей имеет небольшую заработную плату). В силу того, что разброс минимальной и максимальной величин заработной платы очень велик, экстремальные значения сильно сказываются на значении среднего арифметического М (на рисунке обозначено как ). В связи с этим М сильно сдвигается в сторону «хвоста» распределения (вправо) и не может характеризовать заработную плату, соответствующую большей части населения.
Бимодальное (двугорбое) распределение наблюдается тогда, когда исследуемый признак анализируется вне однородной совокупности и, следовательно, необходимо учитывать два средних значения признака для достоверного анализа. Пример: при оценке физического развития детей подростков распределение роста будет иметь две моды (соответствующие девочкам и мальчикам).
Альтернативное распределение наблюдается в том случае, когда значения исследуемого признака распределяются по принципу: «да/нет», т.е. взаимоисключают друг друга. Подобное распределение характерно для описания качественных признаков (пример: мужской, женский пол).
Использование средних величин в медицине и здравоохранении:
а) для оценки состояния здоровья — например, параметров физического развития (средний рост, средний вес, средний объем жизненной емкости легких и др.), соматических показателей (средний уровень сахара в крови, средний пульс, средняя СОЭ и др.);
б) для оценки организации работы лечебно-профилактических и санитарно-противоэпидемических учреждений, а также деятельности отдельных врачей и других медицинских работников (средняя длительность пребывания больного на койке, среднее число посещений за 1 ч. приема в поликлинике и др.);
в) для оценки состояния окружающей среды.
В медицинских исследованиях из средних величин наиболее часто используется среднее арифметическое. В то же время, у больных людей значения многих физиологических параметров имеют асимметричное распределение, ввиду того, что изменяются в сторону увеличения или уменьшения под влиянием заболевания. Поэтому для характеристики центральной тенденции их распределения, во многих случаях, более обоснованным является как раз использование медианы, а не средней арифметической.
!Attention! Квартет Энскомба
Квартет Энскомба — четыре набора числовых данных, у которых простые статистические свойства идентичны, но их графики существенно отличаются.
Каждый набор состоит из 11 пар чисел. Квартет был составлен в 1973г. английским математиком Энскомбом для иллюстрации важности применения графиков для статистического анализа и влияния выбросов значений на свойства всего набора данных.
Сами последовательности приведены ниже.
Что говорит, несомненно о том, что нужно смотреть не только на графики, но и заглядывать в данные иногда.