Если посмотреть на семейство x86 процессоров в целом, то можно заметить, что оно не сильно изменилось за 40 лет. Было много дополнений, но оригинальный дизайн, как и почти весь набор команд, в основном остались нетронутыми и до сих пор прослеживаются в современных процессорах.
И иногда, когда наши приложения много работают с процессором — можно пользоваться тем, что мы знаем. как процессоры устроены внутри.
Что же мы сделаем сегодня?
- Ускорим подсчеты суммы элементов массива в 25 раз — благодаря independent chain и загрузке всех суммирующих юнитов в процессоре.
- Ускорим выборку из коллекции в 10 раз благодаря знанию о branch prediction. А потом ещё вдвое — благодаря тем же independent chain.
- Пощупаем магию Reciprocal throughput благодаря коду на C#.
- Чуть-чуть поговорим про историю развития процессоров.
История 1. Средняя цена
Скажем, у нас есть биржа с десятками тысяч инструментов (акции, ETF, валюты, криптовалюты) и десятками тысяч заявок на покупку и продажу каждого инструмента. Заявки могут добавляться, удаляться или менять цену, при этом на главной странице всегда отображен объём стоимости всех заявок на покупку и продажу по инструментам.
Узнать сумму просто. Кажется, это простая задача. У нас даже уже есть массив заявок по каждому инструменту:
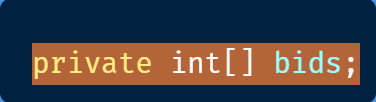
И спасибо LINQ, мы можем просто решить эту задачу:
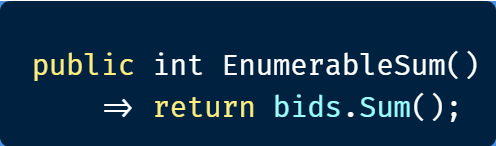
Но мы ведь хотим делать это быстрее потому что заявки меняются постоянно, а историчности в нашем массиве нет. Поэтому давайте оптимизировать этот алгоритм шаг за шагом чтобы в самом конце прийти к тому, из чего именно наше ускорение состоит.
Отказываемя от LINQ
Все слышали, что LINQ очень далёк от «производительности». Поэтому давайте перепишем код без него:
Сравним эти две реализации, чтобы убедиться, что идём мы в верном направлении. Для этого проще всего воспользоваться BenchmarkDotNet, который как раз и нужен для измерения производительности.
Установим пакет BenchmarkDotNet:
Теперь просто добавим к нашим методам атрибут [Benchmark]:
Настроим запуск. В пакете есть несколько готовых настроек для разных ситуаций, но чтобы быстро получить примерный результат, я добавлю к классу IntegerSumCalculator запуск небольшого количества прогонов с помощью атрибута [ShortRunJob]. Заодно можно посмотреть на размер получившегося в бенчмарке кода и задать дополнительные колонки в результатах, это тоже настраивается с помощью атрибута.
Осталось добавить в наше приложение запуск бенчмарков:
Запускаем, собирая в Release и ждём результатов выполнения.
Всё верно, LINQ медленный, ещё и объектами в хипе намусорил. И код раздул своими итераторами и прочим. Кажется, мы уже достигли хорошего результата. Но можно ли лучше?
Отказываемся от safety checks
Давайте подумаем, что в реализации метода SumNaive может мешать нам посчитать сумму очень быстро? Если заглянуть в asm-код, то легко заметить, что из-за того, что это массив, мы на каждое обращение к каждому элементу массива по индексу проверяем, а не вышли ли мы за границы массива. Для просмотра ASM-кода будем пользоваться сайтом https://sharplab.io/. Интересен нам будет только сам цикл:
Если писать код на unsafe, то этой валидации не будет. Для этого нам нужно пометить метод как unsafe и воспользоваться указателями:
Если посмотреть в ASM-код, то цикл превратится вот в это:
Такой ASM код уже гораздо лучше. Он не делает ничего лишнего. Забенчмаркаем и увидим, что это существенно помогло:
Ускорение в полтора раза! Отлично. Дальше код будет только unsafe. Но самое главное — в таком ASM коде не осталось никакого мусора. Кажется, что цель достигнута. Но можно сделать ещё лучше.
Добавляем трюки
А теперь давайте добавим немного безумия. Как вам вот такая реализация?
Вы, наверное, уже видите, что этот алгоритм не работает. Да, если длина массива не делится на 4, мы посчитаем сумму чисел неверно (или словим AccessViolation). Нужно отдельно обработать последние элементы в конце массива. Такая обработка занимает константное время для любой длины массива, но сильно раздувает код, поэтому давайте пока всегда работать с массивом длины кратной 4 чтобы код был более компактным.
У нас такое же число сложений, но меньше инкрементов указателя, а доступ с контсатным сдвигом на самом деле занимает столько же времени, сколько и доступ непосредственно по указателю. Это просто та самая размотка цикла, которая уже давно известна как метод оптимизации. На сколько она эффективна?
Размотанный цикл выполняется ещё на 35% быстрее. При этом размер кода логично немного вырос. Давайте посмотрим, что происходит в ASM-коде:
Сложений выполнится столько же, сколько и в предыдущем примере, а вот перемещение указателя, CMP и JNE будет выполнено вчетверо меньше, чем в предыдущем коде, поэтому итоговая производительность и растёт.
Компиялтор мог бы и самсделать подобную оптимизацию или вообще размотать весь цикл в последовательнность из N сложений. Но это раздувает размер кода, а в общем случае задача компилятора это получить наиболее компактное представление кода. Неоторые компиляторы всё-таки делают подобную оптимизацию и при определенных условиях, но в .net у нас пока что не так.
Всё? Нет, но мы как раз подошли к самому интересному.
Добавляем знание архитектуры процессора
Давайте вначале просто поменяем код таким образом:
Теперь мы складываем не в одну переменную, а в четыре. И в конце суммируем их между собой. Число сложений внутри цикла осталось прежним, число сравнений и прыжков тоже не изменилось, зато добавились константное число дополнительных операций перед возвратом результата из метода. Производительность должна или не измениться или вырасти на едва заметную для массивов большого размера величину. Запустим бенчмарк:
Время выполнения уменьшилось больше, чем в полтора раза! Но число операций осталось (почти) прежним! То есть, одну и ту же последовательность операций (отличающихся только регистрами) процессор в этих случаях выполнил с разной скоростью. Как такое вообще может быть?
Попробуем разобраться с помощью ASM-кода:
Код почти не отличается от предыдущего, кроме того, что теперь мы складываем всё не в один регистр EAX, а в 4 — EAX, EDX, ESI, EDI. Но почему это быстрее?
И именно здесь в дело вступает внутреннее устройство процессоров.
Небольшая экскурсия в историю вычислительного конвейера процессора
8086 процессор имел 14 регистров. Четыре регистра общего назначения – AX, BX, CX и DX. Четыре сегментных регистра, которые используют для облегчения работы с указателями – CS (Code Segment), DS (Data Segment), ES (Extra Segment) и SS (Stack Segment). Четыре индексных регистра, которые указывают на различные адреса в памяти – SI (Source Index), DI (Destination Index), BP (Base Pointer) и SP (Stack Pointer). Один регистр содержит битовые флаги. И самый интересный для нас сегодня регистр – IP (Instruction Pointer), который указывает на следующую инструкцию, которая должна быть исполнена.
Как это работает внутри:
- Сначала переходим по указателю на инструкцию и декодируем команду по этому адресу.
- Выполняем инструкцию (читаем память, записываем память, сравниваем и прочее).
- Производим этап остановки (retire stage) и IP начинает указывать на следующую инструкцию, которую нужно исполнить.
Каждый новый чип в семействе добавлял новую функциональность. Большинство добавляло новые инструкции, некоторые добавляли новые регистры.
В 1982 был введён кэш инструкций. Вместо обращения к памяти на каждой команде, процессор читал на несколько байт дальше текущего IP. Кэш инструкций был всего несколько байт в размере, достаточным для хранения лишь нескольких команд, но ощутимо увеличивал производительность, исключая постоянные обращения к памяти каждые несколько тактов.
В 1985 в 386 процессор был добавлен кэш данных и увеличен размер кэша инструкций. Этот шаг позволил увеличить производительность за счет чтения на несколько байт дальше запроса на данные.
В 1989 i486 процессор перешел на 5-уровневый конвейер. Вместо наличия одной инструкции во всем процессоре, теперь каждый уровень конвейера мог иметь по инструкции. Это нововведение позволило увеличить производительность более чем в два раза по сравнению с 386 процессором на той частоте.
Этапы обработки инструкций в i486 – загрузка (Fetch), основное декодирование (D1), вторичное декодирование или трансляция (D2), выполнение (EX), запись результата в регистры и память (WB). Каждый этап конвейера мог содержать по инструкции.
Инструкции в конвейер всё равно заходят последовательно. Но у конвейера в общем случае есть одна проблема. Например, у нас есть код обмена значениями двух переменных:
Что происходит внутри конвейера процессора?
- Первая инструкция входит в этап загрузки, на этом первый шаг закончен.
- Следующий шаг – первая инструкция входит в D1 этап, вторая инструкция помещается в этап загрузки.
- Третий шаг – первая инструкция двигается в D2 этап, вторая в D1 и третья загружается в Fetch.
- На следующем шагу что-то идет не так – первая инструкция переходит в EX..., но остальные остаются на месте. Декодер останавливается, потому что вторая XOR команда требует результат первой. Переменная «a» должна быть использована во второй инструкции, но в неё не будет произведена запись, пока не выполнилась первая инструкция. Поэтому команды в конвейере ждут, пока первая команда не пройдет EX и WB этапы. Только после этого вторая инструкция может продолжить свой путь по конвейеру. Третья команда аналогично застрянет в ожидании выполнения второй команды.
Суммирование и вычислительный конвейер
В случае с подсчетом суммы эффект похожий — чтобы произвести операцию нам всё равно нужно значение в регистре EAX. А в случае с 4 переменными эти операции более независимы. Но всё даже более интересно. Кроме конвейера процессору нужно как-то выполнять инструкции. И для этого у него есть свои микромодули — вычислители. Они умеют делать определенное действие за известное заранее число циклов.
В общем случае этап выполнения может занимать разное число операций потому что есть инструкции, на обработку которых процессор тратит несколько циклов. При этом ему всё ещё не обязательно ждать, пока такая инструкция завершится целиком, чтобы начать обрабатывать следующую инструкцию.
Есть, например, инструкция MUL, умножение. Её latency = 3. То есть, чтобы выполнить умножение, нужно затратить 3 цикла процессора. Но давайте представим, что мы умножаем три раза 6 совершенно независимых чисел. A = A*B, C = C*D,E = E*F.
- На первом цикле начнется выполнение A*B.
- На втором цикле начнется выполнение C*D, а A*B будет на втором шаге.
- На третьем цикле начнется выполнение E*F, C*D будет на втором шаге, а A*B будет на завершающем третьем.
- На четвертом цикле E*F будет на втором шаге умножения, C*D на завершающем.
- На пятом цикле E*F будет на завершающем шаге.
Итого, мы на 3 умножения потратили не 9 циклов, а всего 5. Потому что все 3 операции были в цепочке независимых инструкций или independent chain. Но как только мы свяжем их друг с другом через какую-нибудь переменную (регистр), так возможность pipelining'а мгновенно исчезает. Но как только мы свяжем их друг с другом через какую-нибудь переменную (регистр), так возможность pipelining'а мгновенно исчезает.
Но как только мы свяжем их друг с другом через какую-нибудь переменную (регистр), так возможность pipelining'а мгновенно исчезает.
Вернёмся к нашим сложениям. Они чуть интереснее. Если для умножения у каждого ядра есть свой единственный mul-capable unit, то для сложения их, обычно, четыре! А latency одного сложения = 1. Это значит, что если все 4 сложения независимы и образуют independent chain, то все 4 сложения могут выполниться одновременно за 1 цикл.
Именно потому наш первый вариант с реализацией четырех сложений подряд оказался медленнее, чем второй. Потому что в первом варианте мы всё складывали в одну и ту же переменную. И в ASM коде соответственно было также — мы складывали всё в один регистр EAX. А значит на 4 последовательных сложения потратили 4 процессорных цикла. А во втором варианте 4 сложения делались в разные переменные. И в ASM коде 4 сложения делались в 4 разных регистра соответственно. И все 4 сложения выполнились за 1 цикл.
Поэтому, если даже мы думаем, что написали последовательную, «однопоточную» (если можно так выразиться) программу, процессор так не думает — сложения выполняются одновременно.
Но почему же производительность выросла всего в полтора раза, а не в 4? Короткий ответ — потому что этап выполнения не единственный и с учетом других накладных расходов прирост параллельного сложения именно такой.
А можно ещё быстрее? И на сколько этот эффект сопоставим с размоткой цикла, какой из трюков даёт больше эффекта?
Эксперементируем с числом переменных и размоткой цикла
Наши текущие знания говорят, что 2 переменных дадут меньший эффект, чем 4 переменных, а большая размотка цикла даст больший эффект, при этом число переменных >4 не будет играть значения. Чтобы проверить все эти эффекты, можно дописать ещё несколько реализаций:
- 2 перменных и смещение в цикле на 2 элемента должно быть медленнее оригинала.
- 2 переменных и смещение в цикле на 16 элементов может быть как медленнее за счет уменьшения параллельности, так и быстрее за счет размотки цикла.
- 8 переменных и смещение в цикле на 8 элементов может ускориться только за счет размотки цикла.
Данные бенчмарков:
Дальнейшая размотка цикла действительно даёт эффект и незначительный прирост производительности, а вот уменьшение числа переменных и параллелизма явно негативно влияет на производительность на столько, что даже размотка цикла не компенсирует этого.
А можно ли ещё быстрее?
На самом деле нужно. Потому что в 2011 году в процессорах на микроархитектуре Sandy Bridge от Intel и Bulldozer от AMD были представлены векторые инструкции (и векторные регистры для работы с ними) — встроенный механизм параллельных вычислений по принципу SIMD. В .net есть поддержка векторных вычислений:
Результаты бенчмарка:
Векторные операции больше, чем в 2 раза быстрее размотанного цикла с independent chain, поэтому для молотилок чисел они подходят больше.
Литература а вообще знать про магию обработки инструкций в конвейере и микрооптимизации основанные на этом? Во-первых, потому что это просто офигенно. Во-вторых, в процессоре есть много разных инструкций с разным latency и числом логических блоков для их выполнения, поэтому полезно знать, где можно быстро подхачить код без значительных изменений под векторизацию или понять, как работает микрооптимизация в этом конкретном месте. Есть даже прекрасный документ от Angner Fog с таблицами параллелируемости разных типов инструкций на разных поколениях процессоров.
Branch prediction
Конвейер в процессоре — отличная штука, которая трудится чтобы увеличить производительность нашей программы. Но всё ломается, когда появляются они — JMP. Они же ветвления. Они же переходы, которые меняют последовательность выполнения программы. Именно поэтому начиная с i486 в процессорах появился предсказатель переходов.
Как это работает. Поскольку конвейер может начать загружать следующие инструкции ещё до завершения текущих, то в случае переходов какие-то инструкции считаются предсказанными и начинают загружаться в конвейер заранее. Если переход не случается, то конвейер сбрасывает текущеее состояние и начинает обработку нужных инструкций заново.
В 486-х реализовывал Static branch prediction. Это когда какие-то ветки всегда считаются предсказанными. Например, в случае ветвления блок IF всчитался предсказанным и загружался в конвейер. В циклах с постусловием, когда идет переход на младшие адреса — в конвейер загружаются инструкции, расположенные по адресу перехода.
В процессорах Pentium предсказатель переходов стал динамическим — в этой схеме делается предсказание для инструкции ветвления, находящейся в данный момент в конвейере. Предсказание будет либо выполнено (истино), либо нет (ложно). Если предсказание истинно, то конвейер не будет очищен и не будет потеряно ни одного такта. Если предсказание ложно, то конвейер промывается и начинается заново с текущей инструкции.
Это реализовано с помощью 4-х стороннего ассоциированного кэша с 256 записями. Он называется целевым буфером ветвления (Branch Target Buffer, BTB). Запись каталога для каждой строки состоит из:
- Бит Valid: Указывает, является ли запись действительной или нет.
- Бит истории: Отслеживает, как часто принимался бит.
Благодаря этому можно отслеживать паттерны, по которым ветвления исполняются или не исполняются, поэтому предсказатель переходов работает более точно. И даже на абсолютно случайных последовательностях переходов такой предсказатель переходов в зависимости от распределения числа взятых и невзятых переходов может давать результаты выше 50% за счет повторения более часто встречающихся сценариев:
История 2. Парадокс чётности
Есть гипотеза, что для инструментов, где заявок с чётной ценой больше, изменение средней стоимости почти всегда будет идти вверх, то есть следующая опубликованная заявка будет с ценой выше средней. И хорошо бы эту гипотезу мониторить в реальном времени. К счастью, подсчитывать число чётных элементов в массиве очень просто.
Но мы ведь уже помним, что LINQ очень медленный, поэтому первым делом избавимся от него.
Добавим бенчмарк с [ShortRunJob] чтобы померять производительность. А ещё в BenchmarkDotNet есть прекрасная фича, где можно для тестов выводить HardwareCounter, и для предсказателя переходов как раз есть счетчики числа переходов и числа неверных предсказаний. Добавить их можно с помощью атрибутов:
Результаты бенчамрка:
Распределение угаданных переходов тут будет как раз стремиться к 50/50, но предсказатель всё равно постарался и выполнил только часть ошибочных переходов. А что, если помочь предсказателю переходов и предварительно просто отсортировать тот же массив чисел по критерию чётности, и выполнить точно такой же код?
Да, в рамках задачи «посчитать число четных чисел» достаточно глупо сортировать массив по критерию четности. Но мы не решаем эту задачу, мы пытаемся нащупать предсказатель переходов!
Результат бенчмарка:
Супер! Получается, что один и тот же метод, который гарантированно потрогает каждый элемент и выполнит абсолютно одинаковую работу вне зависимости от порядка элементов в массиве, внезапно оказался в 4,5 раза, когда элементы (те же, что и в прошлом примере) не отсортированы.
Но несколько ошибочных ветвлений конвейер успел выполнить. Связано это с тем, что вначале предсказатель переходов понял паттерн, когда все переходы осуществляются, потом один раз сломался в момент смены четных чисел на нечетные и снова перестроился на новый паттерн, где переход всегда не выполняется:
"TTTTTTT....TTTFFF...FFFFFFF"
Давайте попробуем сделать так чтобы предсказатель переходов вообще всегда угадывал, для этого можно сделать паттерн, который будет всегда одинаковым на протяжении всего массива. Например, четные и нечетные элементы будут всегда чередоваться друг с другом:
"TFTFTFT....FTFTFT...FTFTFTF"
Тут нужно хитро построить массив чтобы он был отсортирован таким образом. Я для этого сделал метод, возвращающий псевдослучайное число с заданным параметром чётности:
Результат:
Ошибки предсказаний исчезли совсем и метод стал ещё чуть-чуть быстрее! И, кажется, это лучший результат, который можно получить с предсказателем переходов.
Но мы ведь не можем на самом деле сортировать массив просто для подсчета количества четных значений. Логично задаться вопросом, а можно ли извлекать практическую пользу из знания о существовании предсказателя переходов и его проблем с ветвлениями в коде? О да, и ещё как!
Например, как на счёт того, чтобы не писать if'ы там, где мы можем так сделать? Чаще всего такое возможно где-то вокруг арифметики и работы с числами. Например, наш с вами код про четные числа можно переписать таким образом.
Давайте запустим бенчмарк и сравним новую и старую версию кода на отсортированном и неотсортированном массиве:
Отлично видно, что версия кода без if'ов работает одинаково и на отсортированном, и на не отсортированном массиве. В случае, когда мы не контролируем источник данных, когда элементы в массиве не отсортированы, версия кода без if'ов 3.5 раз быстрее! И это не потому, что сам if медленный, а XOR быстрый. Как видно на отсортированных массивах, реализация без if всё-таки чуть-чуть медленнее, чем с if'ами. Это ещё одно подтверждение, на сколько необходим и как крут branch prediction!
Но мы ведь узнали ещё кое что о конвейере обработки, паралельном выполнении на вычислителях и размотке циклов! Давайте сделаем ещё одну версию — без проверки выхода за пределы массива, отдельными перменными и размоткой цикла.
Запускаем бенчмарк:
Бамс! Сочетание нескольких оптимизаций даёт эффект даже больше, чем полностью угадывающий переходы предсказатель переходов.
Вместо выводов
- Уважайте конвейер и его труды!
- Branch prediction работает вне зависимости от вашего языка программирования. Хоть на ассемблере пишите, работать будет одинаково!
- Знайте, как работают ЭВМ и извлекайте из этих знаний пользу. Ну или хотя бы удовольствие!
- Даже если отдельная оптимизация даёт незначительный эффект, микрооптимизации в сочетании могут давать значительный эффект.
Литература
- Статьи Саши Денисова во внутреннем блоге Контура