
Источник: Nuances of Programming
Стандартный Apple Notes, более продвинутый Google Docs, Microsoft Word и Medium — всё это редакторы, которые позволяют фиксировать наши важные мысли и информацию, тем самым помогая рассказывать истории самыми увлекательными способами.
Но вы когда-нибудь задумывались о том, как они работают изнутри? Каждый раз при нажатии на клавишу происходит выполнение сотен строк кода, чтобы на странице ожил ваш любимый персонаж. Казалось бы, такие несложные действия, как перетаскивание выделенного фрагмента текста или превращение текста в заголовок, на самом деле запускают множество изменений в системе, лежащей в основе программы.
В то время, пока вы спокойно работает в текстовом редакторе и не задумаетесь о коде, запускающем все редакционные маневры, моя команда в The New York Times думает об этом постоянно. Наша главная задача — создать текстовый редактор, максимально настроенный под потребности службы новостей. Помимо основных функций набора и отображения текста, новый редактор должен объединить улучшенные возможности Google Docs с понятным дизайном Medium и включить множество дополнительных функций с учетом специфики работы службы новостей.
В течение нескольких лет служба новостей The Times использовала устаревший текстовой редактор, который не отвечал многим ее требованиям в полной мере. Хотя старый редактор максимально адаптирован к процессу продакшена новостной службы, его UI оставляет желать лучшего: он сильно дробит рабочий процесс, разбивая различные фрагменты статьи (текст, фото, соцмедиа и художественно-техническое редактирование) в абсолютно отдельные части приложения. Таким образом, выпуск статьи в этом редакторе превращается в долгий утомительный процесс навигации по непонятным и непривлекательным вкладкам.
Но раздробленность рабочего процесса — это только часть проблемы: устаревший редактор доставляет много головной боли в инженерно-технической части. Он базируется на прямом управлении элементами DOM для отображения любого материала в редакторе, добавляя всевозможные HTML тэги для обозначения различий между удаленным текстом, новым текстом и комментариями. Это означает, что инженеры других команд должны постараться и очистить статью от тэгов перед ее публикацией и отображением на веб-сайте. Надо сказать, процесс довольно времязатратный и не исключает ошибок.
С развитием службы новостей мы мечтаем о новом текстовом редакторе, способном визуально встраивать разные компоненты статьи в один поток, чтобы журналисты и редакторы могли иметь представление о том, как будет выглядеть статья еще до публикации. Кроме того, в идеале новый подход будет более понятным и гибким в отношении выполнения кода и позволит избежать многих проблем, вызываемых старым редактором.
Руководствуясь этими двумя целями, моя команда приступила к созданию нового редактора, получившего название Oak. После многочисленных исследований и месяцев разработок прототипов мы решили создать его на основе ProseMirror, мощного инструментария с открытым исходным кодом JavaScript, отвечающего нашим целям. В отличие от старого редактора, ProseMirror применяет совсем другой подход и представляет документ, используя свою собственную древовидную структуру данных, основанную не на HTML и описывающую структуру текста в терминах абзацев, заголовков, списков, ссылок и прочего.
Вывод текстового редактора, основанного на ProseMirror, в отличие от старого редактора, может отображаться как дерево DOM, текст Markdown или в виде других форматов, которые могут выражать кодируемое ими содержимое, делать его универсальным и решать многие проблемы, с которыми мы сталкивались при работе с устаревшим редактором.
Итак, как же работает ProseMirror? Приступим к изучению внутренней технологии его работы.
Узел — это наше всё
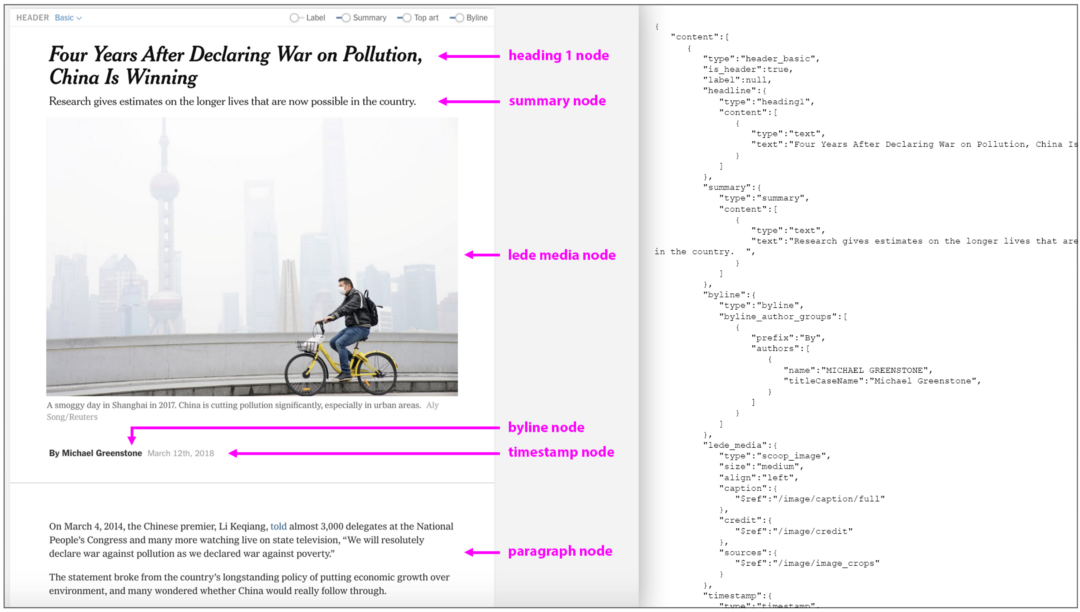
ProseMirror структурирует свои основные элементы, а именно абзацы, заголовки, списки, изображения и т. д., как узлы. Многие узлы имеют дочерние узлы, например, узел heading_basic включает такие узлы, как heading1, byline, timestamp и image. Это приводит к созданию древовидной структуры, как уже ранее упоминалось.
Интересным исключением из этой древовидной структуры является способ, каким узлы абзацев переводят свой текст в код. Рассмотрим абзац, состоящий из предложения “Это жирный текст с выделением”.
DOM зашифрует это предложение в виде такого дерева:
Однако в ProseMirror содержимое абзаца представлено в виде линейной последовательности встраиваемых элементов, у каждого из которых свой набор стилей:
Преимуществом подобной линейной структуры абзацев является то, что ProseMirror отслеживает каждый узел через его численную позицию. Так как ProseMirror распознает выделенное курсивом и полужирным шрифтом слово “выделение” как собственный автономный узел, то он может представлять позицию узла не как место на дереве, а как место в ряду чисел. Текстовый редактор, например, может знать, что слово “выделение” находится в документе в позиции 63, что, в свою очередь, облегчает его поиск, отбор и работу с ним.
Все эти узлы (узлы абзацев, заголовков, изображений) обладают определенными возможностями, связанными с ними, включая размеры, плейсхолдеры и функцию перетаскивания. Некоторые узлы, например, изображений или видео, должны также содержать ID для обнаружения медиафайлов в крупной среде CMS. Как Oak узнает обо всех этих возможностях узлов?
Чтобы сообщить Oak, что из себя представляет каждый отдельный узел, мы создали класс “спецификация узла”, определяющий те настраиваемые модели поведения и методы, которые текстовый редактор должен понимать для корректной работы с узлом. Затем мы установили схему всех узлов в редакторе, в которой каждый из них может быть помещен в общий документ. (Например, мы бы не хотели, чтобы пользователи размещали встроенные твиты в заголовок, поэтому в схеме это действие отклоняется). В схеме приводится список всех узлов, существующих в Oak, и способов их взаимодействия друг с другом.
пираясь на данный список, ProseMirror создает модель документа в любое время. Эта модель является объектом, очень похожим на JSON (его вы можете увидеть рядом с примером статьи Oak в самой верхней иллюстрации). По мере того, как пользователь редактирует статью, этот объект постоянно замещается новым объектом, включающем все поправки, вследствие чего ProseMirror всегда в курсе того, что включает документ и что отображать на странице.
Кстати говоря, ранее упоминалось, что ProseMirror осведомлен о том, как узлы согласуются друг с другом в дереве, но откуда он узнает, как выглядят эти узлы и как отображать их на странице? Для отображения состояния ProseMirror в DOM у каждого узла по умолчанию есть простой метод toDOM(), который преобразует узел в основной тэг DOM. Например, метод узла абзацев toDOM() преобразовывает его в тэг <p> , а метод узла изображений toDOM() — в тэг <img>. Но так как редактору Oak нужны разработанные под пользователя узлы, выполняющие весьма конкретные действия, наша команда оптимизировала функцию NodeView в ProseMirror для проектирования настраиваемого компонента React, отображающего узлы конкретными способами.
(Примечание: ProseMirror не привязан к какому-либо конкретному фреймворку, поэтому NodeView можно создать, используя любой фронтэнд-фреймворк или вполне обходясь без него. Наша команда выбрала React).
Отслеживание стиля текста
Теперь нам известно, что при создании узла ему придается конкретный визуальный вид, который ProseMirror извлекает из NodeView. Но как же работают дополнительные пользовательские стили, такие как полужирный шрифт и курсив? А для этого существуют метки (marks), и вы, возможно, заметили их в схеме блока кода, приведенной выше.
Продвигаясь по блоку кода, где мы объявляем все узлы в схеме, мы определяем типы меток, которые может иметь каждый код. Oak поддерживает определенные метки для некоторых узлов, но не для всех. Например, курсив и гиперссылки допускаются только для небольших узлов заголовков. Затем метки для определенного узла хранятся в его объекте в состоянии текущего документа ProseMirror. Мы также используем метки для настраиваемой функции комментариев, о которой речь пойдет дальше.
Принцип работы правок
Чтобы отображать точную версию документа в любое время и отслеживать его историю, крайне важно фиксировать практически все изменения, которые пользователь вносит в документ, например нажатие буквы “с”, клавиши “ввод”, или вставка картинки. В ProseMirror каждое мельчайшее изменение называется шагом.
Для того чтобы обеспечивать синхронную работу всех частей приложения и показывать самые последние данные, состояние документа остается неизменным, т. е. обновления состояния не происходят путем простого редактирования существующего объекта данных. Вместо этого ProseMirror берет старый объект, объединяет его с объектом, полученным на новом этапе редактирования, и достигает совершенно нового состояния. (Для тех, кто сталкивался с принципами работы Flux, этот принцип должен показаться знакомым).
Этот поток способствует созданию более чистого кода, а также оставляет след обновлений, позволяющий реализовывать некоторые из важнейших возможностей редактора, например сравнение версий. Мы прослеживаем эти шаги и их порядок в хранилище Redux и тем самым помогаем пользователю прокручивать изменения, чтобы переключаться с одной версии на другую и видеть правки, внесенные другими пользователями:
Крутые возможности редактора Oak
Библиотека The ProseMirror является модульной и расширяемой, вследствие чего она требует основательной настройки для выполнения каких-либо действий. Это как нельзя лучше соответствовало нашей цели по созданию текстового редактора, отвечающего конкретным требованиям службы новостей. Вот некоторые из наиболее интересных функций, разработанных нашей командой:
Отслеживание изменений
Функция отслеживания изменений, показанная в примере выше, небезосновательно является самой усовершенствованной и важной. Учитывая, что процесс написания статьи новостной службы сопровождается сложным взаимодействием журналистов и разных редакторов, необходимо видеть, какие изменения и когда были внесены в документ. Эта функция основана на тщательном отслеживании каждой транзакции, сохранении ее в базе данных и последующем отображении в документе в виде зеленого текста для дополнений и красного зачёркивания для удалений.
Настраиваемые заголовки
Oak разрабатывался как текстовый редактор, ориентированный на дизайн и позволяющий журналистам и редакторам визуально оформлять статьи в соответствии с содержанием материала. В связи с этим были созданы узлы настраиваемых заголовков, включающие горизонтальные и вертикальные изображения без рамок по краям. Эти заголовки в Oak являются узлами со своим уникальными NodeView и схемами, позволяющими им включать подписи под материалами, временные метки, изображения и другие вложенные узлы. Для пользователей они уже отражают заголовки в том виде, в каком могут быть опубликованы на сайте для читателей. Таким образом, журналисты и редакторы имеют точное представление о том, как будет выглядеть статья после опубликования ее на сайте New York Times.
Комментарии
Комментарии — важная часть рабочего процесса службы новостей, так как редакторам необходимо поддерживать связь с журналистами, задавать вопросы и предлагать рекомендации. В нашем старом редакторе пользователи были вынуждены вставлять комментарии прямо в документ рядом с текстом статьи, из-за чего статья становилась перегруженной и всегда была вероятность что-то упустить. Для редактора Oak наша команда создала хитроумный плагин ProseMirror, который отображает комментарии справа от статьи. Верите или нет, но комментарии фактически являются типом метки по своей сути. Это такие же примечания к тексту, как полужирный шрифт, курсив или гиперссылки, только с разницей в стиле отображения.

Oak прошел долгий путь в своем развитии, и мы продолжаем разрабатывать новые возможности с учетом потребностей разных отделов службы новостей, которые начинают использовать новый редактор.
Читайте также:
Читайте нас в телеграмме и vk
Перевод статьи Sophia Ciocca: Building a Text Editor for a Digital-First Newsroom