Работая с большими объемами данных нам часто нужно составить список уникальных значений - артикулы или названия товаров, должности, города - да мало ли еще!
Эту задачу можно решить несколькими способами:
- Команда удаления дубликатов (Remove duplicates)
- Сводная таблица (Pivot table)
- Команда расширенный фильтр (Advanced filter)
- Динамическая фильтрация с помощью формул
- миллион способов сделать фильтрацию с помощью макросов.
В заголовке написано "при помощи формул", поэтому коротко расскажу про первые три способа, и подробнее расскажу про четвертый - как сделать динамическую фильтрацию и сортировку массива при помощи формул.

Способ первый - команда удаления дубликатов.
Воспользуемся примером с должностями, когда мы делали выпадающие списки (https://zen.yandex.ru/media/id/5f24070dd98a994308ce5e45/kak-sdelat-vypadaiuscii-spisok-v-excel-chast-2-5f318e6a268a8b3aa0499c21 )
Выбрав таблицу, нажме на кнопку Удалить дубликаты (Remove Duplicates) в разделе Данные (Data):
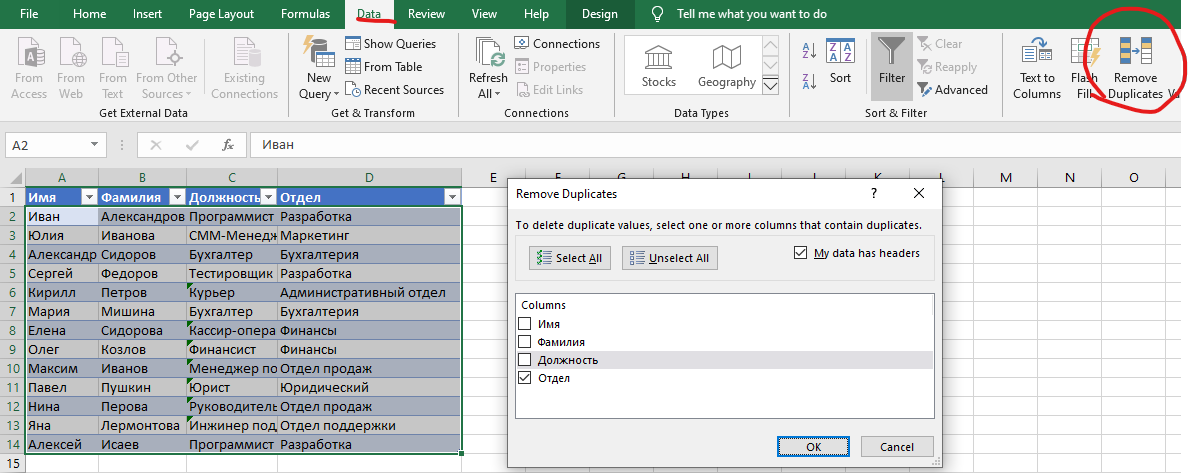
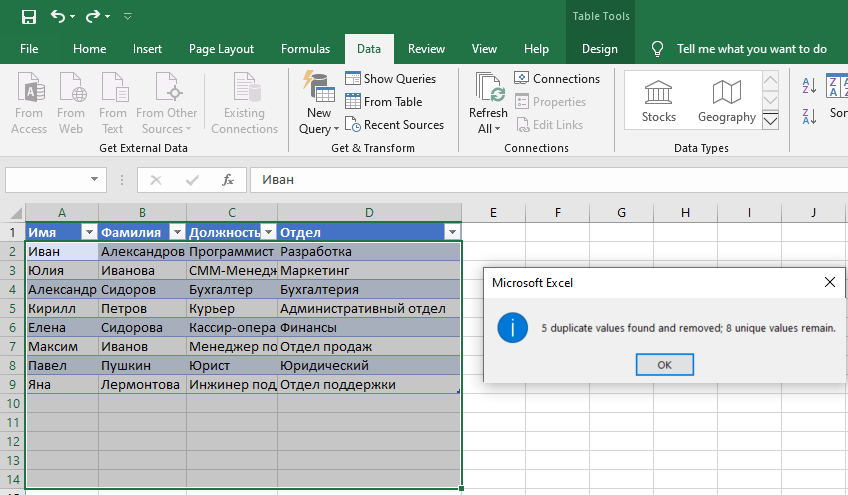
Если выбрать в окне удаления дубликатов только столбец "Отдел", удалится 5 строк с дубликатами. Если выбрать "Должность" и "Отдел", будут удалены только две строки, где сочетание отдела и должности повторяется. Если к выбору добавить еще колонку "Имя" или "Фамилия" - не удалится ничего, так как все сочетания уникальны.
Плюсы способа: просто, быстро, есть дополнительные настройки: можно выбирать уникальность по нескольким столбцам.
Минусы: дубликаты удаляются прямо в той таблице, в которой мы работаем. Если нам нужно сохранить данные, то придется каждый раз копировать таблицу на новый лист. Конечный результат не связан с изначальными данными, при изменении изначальных данных список уникальных результатов не обновится.
Способ второй - сводная таблица
Выделив нужный диапазон данных выбираем команду Сводная таблица (Pivot Table) в разделе Вставить (Insert)
В появившемся окне с настройками сводной таблице можно скорректировать выделенный диапазон и выбрать место, куда вставить сводную таблицу. По умолчанию предлагается создать новый лист, с чем мы и согласимся.
Дальше в появившейся справа панели перетащим нужное нам поле в графу Строки (Rows). Если хотим оставить уникальные отделы - перетащим "Отдел". Если хотим уникальные должности - аналогично перетащим "Должность".
Плюсы: отфильтрованные уникальные данные копируются в новое место, не удаляя данные в изначальной таблице. Сводная таблица связана с изначальными данными, поэтому при изменении изначальных данных не нужно пересоздавать сводную таблицу, достаточно нажать на кнопку Обновить (Refresh) в разделе Данные (Data).
Минусы: достаточно сложный способ, не подходит для новичков. Хотя таблица и связана с данными, каждый раз нужно инициировать обновление вручную.
Способ третий - команда расширенный фильтр
Аналогично созданию сводной таблицы: выделяем наш диапазон, и в разделе Данные (Data) выбираем команду Расширенный фильтр (Advanced filter). Проверяем настройки. В графе Диапазон списка (List range) должны остаться только те колонки, сочетание которых должно быть уникальным (как в первом способе). Можно выбрать что делать с итоговым результатом: отобразить прямо в изначальных данных (дубли не удаляются, а прячутся), либо скопировать в новое место.
Плюсы: универсальный вариант - просто, можно проверить уникальность по нескольким колонкам, есть выбор как отображать результат.
Минусы: только то, что при обновлении данных придется применять фильтр снова, чтобы результаты обновились.
Четвертый способ - формулы
Четвертый способ - использовать формулы для работы с массивами INDEX (ИНДЕКС), MATCH (ПОИСКПОЗ), COUNTIF (СЧЁТЕСЛИ), IFERROR (ЕСЛИОШИБКА) а также SMALL (НАИМЕНЬШИЙ), ISTEXT (ЕТЕКСТ), ISNUMBER (ЕЧИСЛО).
Вот эта формула: =IFERROR(IFERROR(SMALL(IF((COUNTIF($D$2:D2; Table2[Отдел])=0)*ISNUMBER(Table2[Отдел]);Table2[Отдел]; "A"); 1); INDEX(Table2[Отдел]; MATCH(SMALL(IF(ISTEXT(Table2[Отдел])*(COUNTIF(D2:$D$2; Table2[Отдел])=0); COUNTIF(Table2[Отдел]; "<"&Table2[Отдел]); ""); 1); IF(ISTEXT(Table2[Отдел]); COUNTIF(Table2[Отдел]; "<"&Table2[Отдел]); ""); 0)));"")
Необходимые пояснения:
- Формула должна начинаться как минимум, с 2 строки в столбце (в примере выше - с третьей), а ячейка над формулой должна либо содержать значение, которого нет в списке, либо должна быть пустой.
- Table2[Отдел] - это именнованный диапазон данных. Если вы используете таблицу - у вас будет похожее название. Если нет - нужно указать, например $A$1:$A$100.
- Это формула массива, о чем говорят фигурные скобки вокруг формулы. Вводить их вручную бесполезно, нужно в строке с формулой нажать Ctrl + Shift + Enter.
- Формула должна быть протянута на столько ячеек, сколько уникальных значений мы допускаем максимально.
- Подробно и в деталях, как работает эта формула я разобрал в статье https://zen.yandex.ru/media/id/5f24070dd98a994308ce5e45/neobychnoe-ispolzovanie-formul-v-excel-kak-vybrat-iz-spiska-unikalnye-znacheniia-bez-makrosov-5f33e5e9f13d89681bf68520 , здесь лишь используется усовершенствованный вариант, который, помимо отбора уникальных значений, еще и сортирует данные.
- Сортировка выполняется при помощи тех же функций INDEX, MATCH, COUNTIF, но немного по-разному для текста и чисел (поэтому и используются IF, ISTEXT и ISNUMBER. Также есть функция ISERROR, которая фильтрует ошибки, что позволяет иметь пустые строки в исходных данных.
Напишите в комментариях, если нужен дополнительный разбор :-)
Плюсы: универсальный вариант, который работает сам, автоматически обновляя список уникальных значений из исходных данных.
Минусы: думаю минусы очевидны - это самый сложный вариант. Мало того, что формулы нужно вставлять вручную, это еще и формулы массива, и малоопытный пользователь Excel легко может что-нибудь испортить.
Как обычно, прикладываю ссылку на файл Excel: https://yadi.sk/i/0hgvtRRVDsTXeA