
Рассмотрим задачу выявления и удаления дублирующих значений в массивах информации с библиотекой Pandas. В демонстрационных целях будем использовать набор объявлений о продажах квартир в Республике Северная Осетия-Алания, имеющий следующий вид:
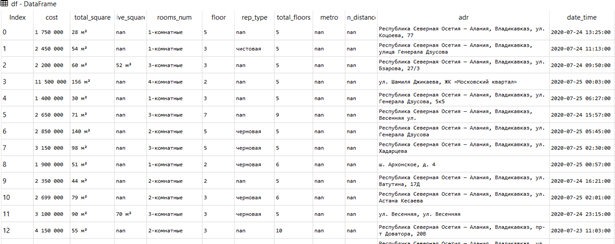
Для определения дублирующих данных можно воспользоваться методом duplicated, в котором при желании задается подмножество столбцов, одинаковые значения в которых являются признаком дубликата (параметр subset, по умолчанию равен None - все столбцы), а также стратегию пометки строк как дубликата (параметр keep, только первое вхождение не помечается как дубликат - по умолчанию, только последнее значение не помечается как дубликат, все повторяющиеся значения помечаются как дубликаты). Продемонстрируем работу метода на заданном наборе столбцов и со стратегией пометки всех дублирующих значений:
Чтобы получить соответствующие значения столбцов достаточно проиндексировать таблицу объектом Series, полученным на предыдущем шаге:
Для удаления повторяющихся значений в pandas предназначен метод drop_duplicates, который в числе прочих имеет такие же, как и duplicated параметры. Продемонстрируем его применение на практике:
То есть данный метод удалит все строки, которые имеют одинаковые значения в заданных столбцах. Это можно проверить альтернативным способом, получив индексы строк таблицы, для которых duplicated выдает положительное значение, и удалив их из таблицы по номерам: