
Рассмотрим задачу выявления и удаления незаполненных значений, которые в Pandas обозначаются служебным значением NaN. В демонстрационных целях будем использовать набор объявлений о продажах квартир в Республике Северная Осетия-Алания, имеющий следующий вид:
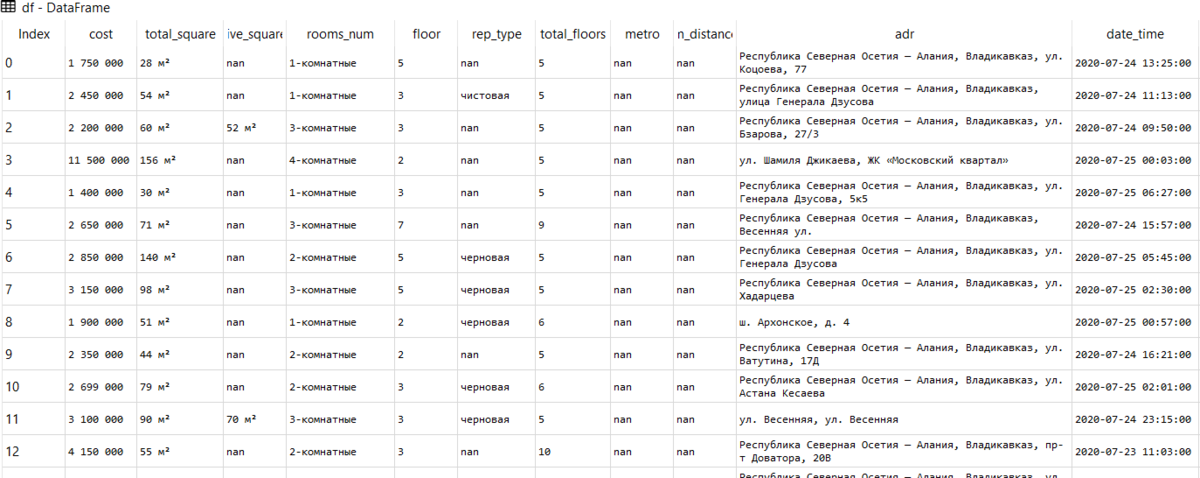
Для определения незаполненных значений используются методы isnull, notnull, возвращающие True/False для каждого объекта (обычно значение в столбце или элемент в строке) в зависимости от присутствия в нем пропущенных значений. Например, выведем строку нашей таблицы, в которой значение date_time не заполнено:
Для удаления незаполненных значений служит метод dropna, который позволяет задать ось удаления (строки, столбцы); порог минимального количества заполненных значений для принятия решения об удалении; подмножество полей, для которых удаляются незаполненные значения. Эти возможности реализуются посредством следующих параметров:
axis – определяет будут удаляться строки (значение 0) или столбцы (1) с недостающими значениями;
how – условие удаления при всех пустых значениях (значение all) или хотя бы одном (any);
thresh – пороговое количество непустых значений, меньше которого требуется удаление;
subset – задает группы имен столбцов или строк для удаления нулевых значений;
Например, так можно удалить строки, в которых столбец date_time содержит пустое значение (такая всего одна):
Другой пример – мы располагает таблицей со значениями нетипичного изменения стоимости недвижимости за неделю в различных категориях площадей (подробнее описывалось в статье), имеющей следующий вид:
Для того, чтобы оставить записи с количеством ненулевых значений не менее 3, потребуется вызвать метод dropna(thresh = 3). В результате получается таблица следующего вида:
Зачастую некоторые объекты с отсутствующими значениями следует сохранить и заполнить разумными значениями. Например, в таблице цен на недвижимость ячейки с отсутствующей «жилой площадью» («live_square») можно заполнить средним значением по жилым площадям в строках, «общая площадь» («total_square») в которых попадала в тот же диапазон что и в заданной. Это реализуется в следующем коде:
# очищаем столбцы и приводим их содержимое к типу с плавающей
# точкой
df.loc[df['total_square'].notnull(), 'total_square'] = df.loc[df['total_square'].notnull(), 'total_square'].map(
lambda x: x.replace('м²', ''))
df.loc[df['live_square'].notnull(), 'live_square'] = df.loc[df['live_square'].notnull(), 'live_square'].map(
lambda x: x.replace('м²', ''))
df['total_square'] = df['total_square'].astype(np.float32)
df['live_square'] = df['live_square'].astype(np.float32)
# ставим в соответствие каждому значению общей площади квартиры
# соответствующий ей диапазон
bins = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 1000]
cat = pd.cut(df['total_square'], bins)
# задаем столбец, содержащий среднее жилой площади для каждого
# диапазона
live_sq = df['live_square'].groupby(cat).transform(np.mean)
# для пустых ячеек с жил площадью вставляем значение, полученное на предыдущем шаге
df['live_square'] = np.where(df['live_square'].isnull(), live_sq, df['live_square'])
Отмечу, что способы разбивки по диапазонам значений (например, функция pandas.cut) описывались в статье, а обработка отдельных значений (метод map) в статье.
Напоследок продемонстрирую результаты преобразования нашей таблицы после выполнения указанного выше участка кода: