
Данная статья написана только для образовательных целей. Мы никого ни к чему не призываем, только в целях ознакомления! Автор не несёт ответственности за ваши действия!
Задача
Задача будет состоять в том, чтобы выгрузить данные о просмотренных фильмах на КиноПоиске: название фильма (русское, английское), дату и время просмотра, оценку пользователя.
На самом деле, можно разбить работу на 2 этапа:
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. Requests удобнее и лаконичнее, так что, использоваться будет она.
Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
Регулярные выражения, конечно, нам пригодятся, но использовать только их, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним.
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser.
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут).
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, просто получаем страницу по url и сохраняем в локальный файл.
import requests
user_id = 12345
url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url для второй страницы
r = requests.get(url)
with open('test.html', 'w') as output_file:
output_file.write(r.text.encode('cp1251'))
Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.
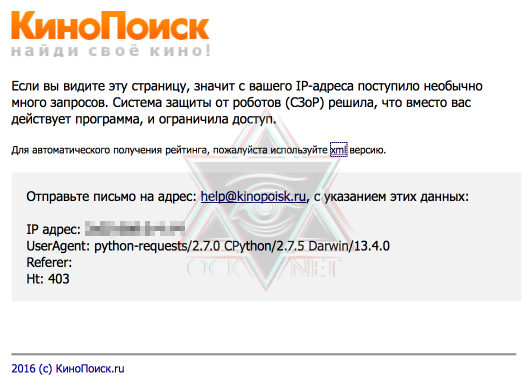
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью "Сеть" в "Инструментах разработчика" в браузере, обычно нужный нам запрос — самый продолжительный.
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
}
r = requests.get(url, headers = headers)
На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: "Как понять сколько всего страниц с оценками?" Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов (<div class = "profileFilmsList">).
Полный код для загрузки данных:
# establishing session
s = requests.Session()
s.headers.update({
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
})
def load_user_data(user_id, page, session):
url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list' % (user_id, page)
request = session.get(url)
return request.text
def contain_movies_data(text):
soup = BeautifulSoup(text)
film_list = soup.find('div', {'class': 'profileFilmsList'})
return film_list is not None
# loading files
page = 1
while True:
data = load_user_data(user_id, page, s)
if contain_movies_data(data):
with open('./page_%d.html' % (page), 'w') as output_file:
output_file.write(data.encode('cp1251'))
page += 1
else:
break
Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
from lxml import html
test = '''
<html>
<body>
<div class="first_level">
<h2 align='center'>one</h2>
<h2 align='left'>two</h2>
</div>
<h2>another tag</h2>
</body>
</html>
'''
tree = html.fromstring(test)
tree.xpath('//h2') # все h2 теги
tree.xpath('//h2[@align]') # h2 теги с атрибутом align
tree.xpath('//h2[@align="center"]') # h2 теги с атрибутом align равным "center"
div_node = tree.xpath('//div')[0] # div тег
div_node.xpath('.//h2') # все h2 теги, которые являются дочерними div ноде
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию "Инспектировать элемент" в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге <div class = "profileFilmsList">. Выделим эту ноду:
from bs4 import BeautifulSoup
from lxml import html
# Beautiful Soup
soup = BeautifulSoup(text)
film_list = soup.find('div', {'class': 'profileFilmsList'})
# lxml
tree = html.fromstring(text)
film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0]
Каждый фильм представлен как <div class = "item"> или <div class = "item even">. Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
# Beatiful Soup
movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href')
movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text
# lxml
movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0]
movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0]
Еще небольшой хинт для debug'a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
# BeatifulSoup
print item
#lxml
from lxml import etree
print etree.tostring(item_lxml)
Резюме
В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.