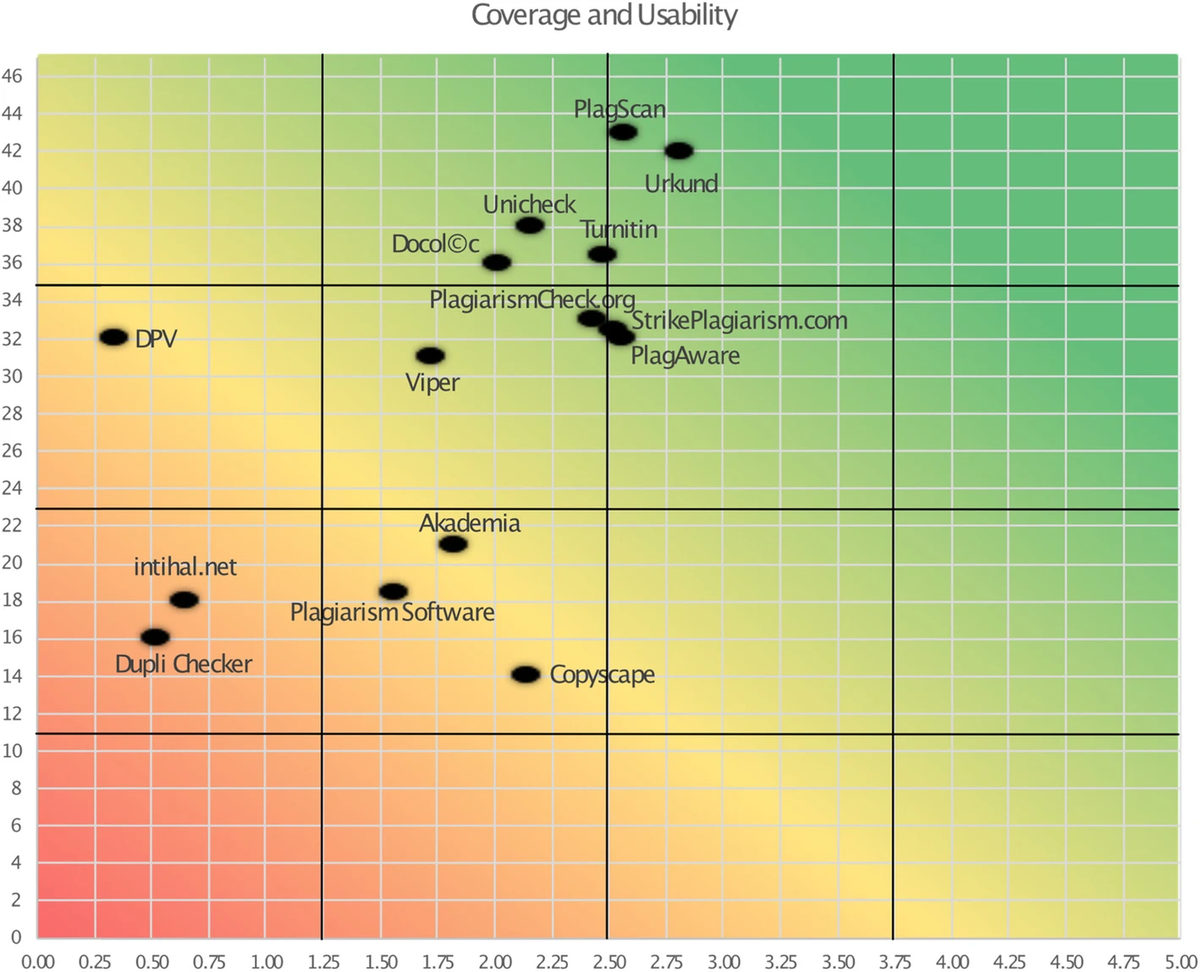
Авторы статьи (международный коллектив авторов из Чехии, Германии, Латвии, Турции, Словакии, Мексики) рассматривают пятнадцать приложений по обнаружению плагиата на нескольких языках и оценивают их по ряду критериев, включая охват и удобство использования.
Они рассмотрели следующие инструменты:
- Akademia
- Copyscape
- Docol©c
- DPV
- Dupli Checker
- intihal.net
- PlagAware
- Plagiarism Software
- PlagiarismCheck.org
- PlagScan
- StrikePlagiarism.com
- Turnitin
- Unicheck
- Urkund
- Viper
Они нашли в них множество слабых мест и не находят ни одного из них подходящим для академического использования. Инструментам необходимо обнаружить больше типов плагиата, указать URL-адрес источника плагиата и, как они пишут: “Уйти от единственного показателя- числа, которое призвано определить степень сходства. Это не так, и организации злоупотребляют им в качестве инструмента принятия решения” мейкера. Они также подчеркивают: «Несмотря на то, что системы способны обнаруживать значительную часть схожего текста, они не определяют плагиат».