
Немного об OpenCV
Это библиотека‚ которая до 1–й версии разрабатывалась в центре разработки программного обеспечения Intel․
OpenCV написана на языке C/C++ и содержит алгоритмы для։ интерпретации изображений‚ калибровки камеры по эталону‚ устранение оптических искажений‚ определение сходства‚ анализ перемещения объекта‚ определение формы объекта и слежение за объектом‚ 3D–реконструкция‚ сегментация объекта‚ распознавание жестов и т․д․
Эта библиотека очень популярна за счёт своей открытости и возможности бесплатно использовать как в учебных‚ так и коммерческих целях․
Большая часть алгоритмов является ресурсоёмкой‚ что‚ в зависимости от целей обработки‚ может требовать большого объема вычислительных ресурсов‚ для обработки даже одного видеопотока в режиме реального времени․ Под ресурсами подразумеваются как вычислительные ядра CPU‚ так и GPU‚ а так же другие аппаратные ускорители․
Камера или другой источник поставляет видеопоток с определенным количеством кадров в секунду (FPS‚ Frames Per Second)‚ которые должны быть обработаны аналитической платформой․ Каждый кадр видео занимает существенный объем памяти‚ например‚ для кадра разрешения 4K глубиной цвета 24 бит‚ массив NumPy ndarray будет занимать 24 MB в RAM‚ а за 1 секунду буферизации при FPS равным 30‚ данных кадров накопится на 729 MB․ При низкой производительности цепочки обработки можно столкнуться с ситуацией отказа из–за переполнения RAM‚ дискового пространства или потери кадров․ Таким образом‚ цепочка обработки должна быть достаточно производительной‚ чтобы успеть обработать все кадры․
Базовое решение ։
Простой подход к построению цепочки обработки подразумевает‚ что она является последовательной․ В этом случае‚ при стандартной частоте кадров равной 30‚ цепочка должна обрабатывать каждый кадр за 1/30 секунды (33 мс)․ Если вам удается добиться такой производительности цепочки‚ можно не искать более производительную архитектуру‚ а остановиться на данной схеме․ Базовый пример из OpenCV как раз успешно обрабатывать кадр за 1/30 секунды на любом актуальном оборудовании։
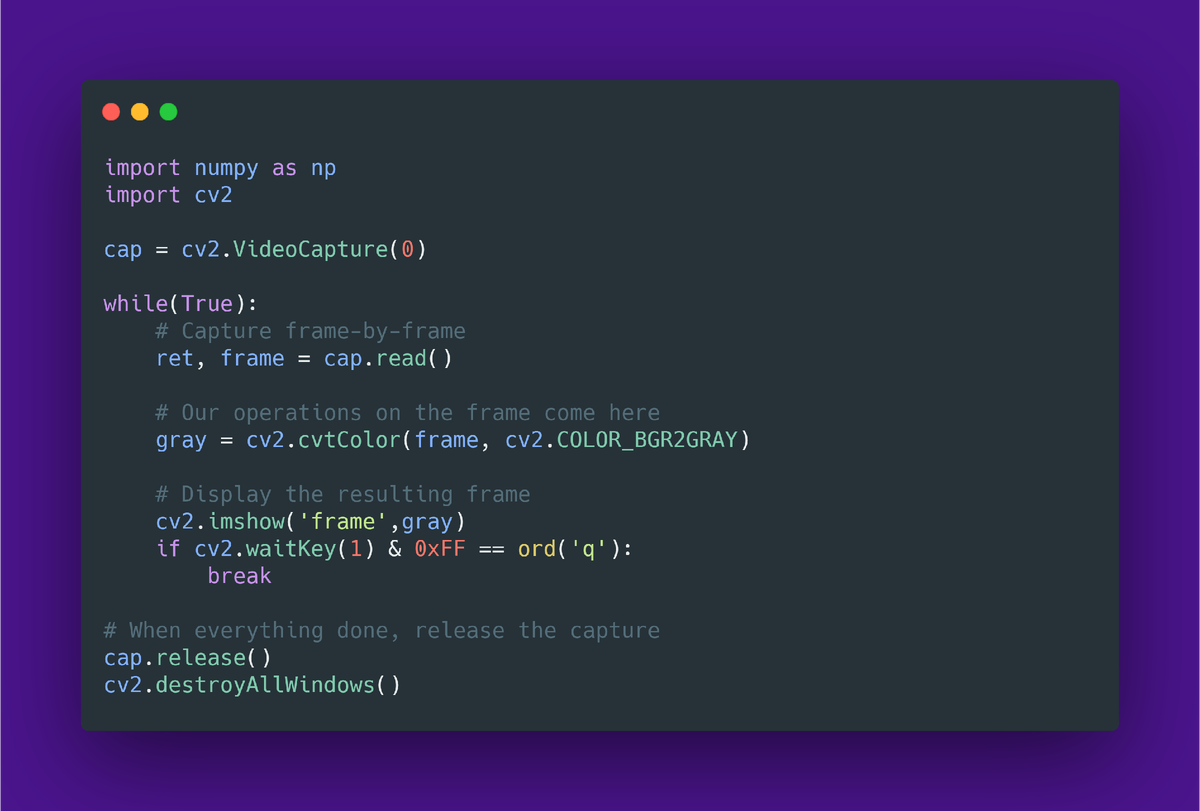
В том случае‚ если цепочка успешно обрабатывается линейно в рамках одного процесса‚ масштабирование тривиально – вы просто добавляете вычислительные ресурсы и балансируете запуск цепочек обработки таким образом‚ чтобы не создавать перегрузку CPU‚ GPU или аппаратных ускорителей․
Часто‚ однако‚ время работы цепочки подвержено колебаниям‚ которые зависят от количества анализируемых объектов и событий‚ происходящих в кадре․ Таким образом‚ время работы цепочки может варьироваться в довольно широких пределах‚ к примеру‚ в нашем программном решении по распознаванию лиц в кадре один из этапов занимает следующее время на устройстве Nvidia Jetson Xavier։
- одно человек в кадре։ 2․4 ± 0․18 мс․
- пять человек։ 10․01 ± 0․44 мс․
Как видно‚ время линейно растет относительно количества лиц․ Это пример алгоритма‚ время выполнения которого зависит от содержимого кадра․ Если таких алгоритмов несколько‚ время обработки кадра может выходить за пределы желаемого‚ что приведет к задержке обработки или потере кадров․ В итоге‚ возникает потребность распределения и декомпозиции работы между вычислителями‚ в рамках которой реализуется распределенный граф обработки‚ где каждый узел обеспечивает обработку некоторой части общего алгоритма․
Например‚ каждое из пяти найденных в кадре лиц может быть обработано на отдельном узле за 2․4 мс‚ при этом сам граф может внести фиксированную задержку за счет затрат на пересылку данных между его узлами․
Мой кошелёк яндекс деньги для желающих мотивировать меня работать над каналом.