
В течение жизни наш мозг постоянно обновляет внутреннюю модель, которая помогает ему предсказывать, как работает мир вокруг нас. Модель, которая хорошо предсказывает реальность, помогает нам эффективно действовать и получать ништяки, которые имеют для нас ценность. Плохая модель обновляется, чтобы лучше предсказывать будущее. Это основа процесса обучения.
Как это работает?
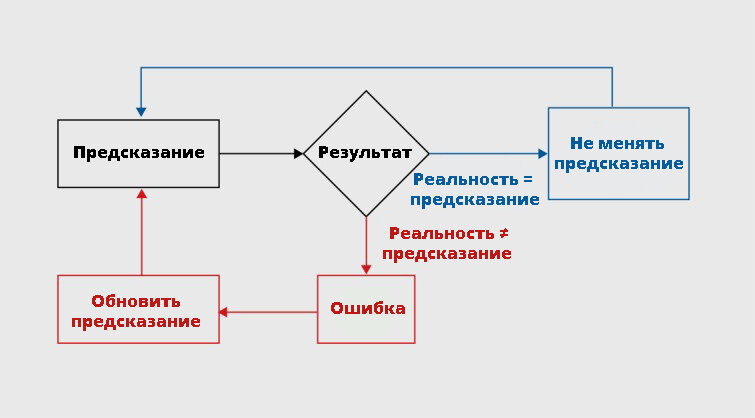
Дофамин кодирует ошибку предсказания награды: его выделение зависит от того, что мы ожидаем получить и что получили в реальности.
Предположим, Маша работает официанткой, и ее заработок складывается из оклада + бонусной части за дополнительные продажи.
Маша посчитала, что в этом месяце она сможет заработать 80 тысяч, если превысит минимальную планку по продажам. Это ожидание мотивировало её совершать активные действия (предлагать гостям десерты и вино) для получения награды.
Какой результат может ожидать Машу в день выдачи зарплаты:
▪️ Маша и правда получила 80 тысяч — реальность совпала с ожиданиями. Дофаминовая система не реагирует на полученную награду, так как не было ошибки предсказания. Поведение Маши не меняется.
▪️ Маша ошиблась с предсказанием и получила оклад без бонусной части (50 тысяч) — реальность оказалась хуже ожиданий. Возникла негативная ошибка предсказания, активность дофаминовых нейронов опустилась ниже базового уровня. Она чувствует разочарование. Теперь она будет записывать каждую сделанную продажу, чтобы точно получить бонус.
▪️ Оказалось, что Маша сделала больше продаж, чем думала, за что получила 90 тысяч. Возникла положительная ошибка предсказания, которая привела к выбросу дофамина. Маша испытывает положительные эмоции. Она будет стараться повторить этот опыт. первом случае неожиданная награда приводит к выделению дофамина (положительная ошибка предсказания в виде пика). Во втором случае награда ожидаема, поэтому дофамин выдел
Наше поведение меняется в зависимости от разницы между полученным и ожидаемым. Получили больше, чем ждали — надо сделать это опять. Получили меньше — надо обновить прогноз и изменить поведение. Происходит процесс обучения, благодаря которому мы обновляем нашу внутреннюю модель так, чтобы она точнее предсказывала реальность и приводила к желаемым результатам.
Во всей этой истории я вижу несколько важных моментов:
1. Каждая ошибка — это возможность чему-то научиться. Если мы не попали по мишени, благодаря ошибке мы корректируем себя при следующей попытке. Не будет ошибок — не будет развития.
2. Мы удовлетворены чем-то, когда ожидание совпадает с реальностью. Неудовлетворение возникает, когда ожидание с реальностью не совпадает.
Если при выходе на новую работу мы ожидаем, что работы будет мало, коллектив будет классный, а платить будут много, мы будем чувствовать неудовлетворение, когда окажется наоборот.
Если ожидаем, что сделаем 10 задач за день, а делаем 2, начинаем винить себя за непродуктивность.
3. Чтобы минимизировать расхождение реальности с ожиданиями, нужно заранее эти ожидания немного занижать. Например, я не жду, что смогу за месяц выучить английский, но уверена, что смогу выучить 100 слов и успешно пройти 5 уроков из учебника.
Не хотите сдуться в самом начале пути к цели? Разбивайте большую цель на маленькие, не ждите быстрых и впечатляющих результатов. Впечатляющие результаты дают маленькие шаги, которые выполняются регулярно.
4. То, какую мы стратегию выбираем при "неудаче", влияет на то, как мы будем вести себя дальше и к чему это нас приведет.
✅ меняем ожидания и поведение → адаптируемся к реальности, развиваемся, достигаем важных целей
❌ забиваем на цель совсем, чтобы избегать неудач → лишаемся позитивных изменений, новизны, топчемся на одном и том же месте, погрязая в рутине