
В нашей команде начали применять практики DevOps задолго до того, как мы стали называться Mad Devs. Конкретно я, столкнулся с этим явлением более 10 лет назад, когда начал админить в команде разработчиков.
В то время этого термина еще не существовало, однако уже тогда частично применялись пока еще не оформленные правила и принципы DevOps:
- непрерывная интеграция;
- автоматические поставки;
- ответственность каждого члена команды за продукт;
- прямая коммуникация с заказчиком;
- сбор и анализ business/application метрик;
- документация и т.д.
По сути, все это было логическим продолжением Agile и начиналось ровно тогда, когда разработчик переставал писать код для локалхоста.
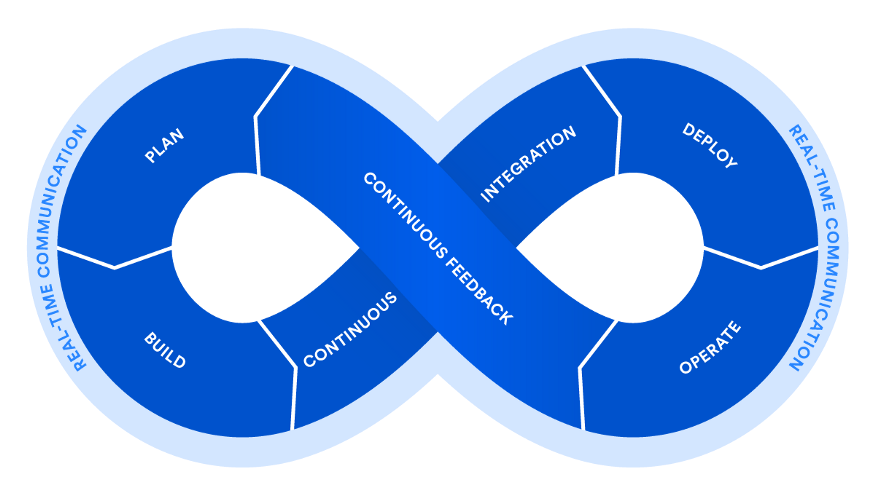
Схема DevOps представленная в свое время Atlassian остается актуальной до сих пор. По сути своей — это цикл современной разработки и поставки продукта, куда включена и его эксплуатация.
Долгое время эксплуатация продукта была отделена от разработки и разработчиков. Этим занимались какие-то нелюдимые, злобные существа называющие себя сисадминами. Сисадмины не участвовали в разработке и коммуникации, они с матами ловили перекинутые через стену пакеты с кодом и пытались его где-то как-то запустить. После каждой такой попытки они несколько дней пялились в логи в поисках непонятной ошибки, профайлили запросы в БД, втыкали в strace и т.д. Позже выяснялось, что всего-навсего нужно было определить новую переменную окружения или добавить новый параметр в конфиг: просто разработчик не предупредил, а админ знает о продукте лишь его название и то что он на похапэ…
Возвращаясь в ностальгическое прошлое: когда я начал админить в той команде, меня не посадили в подвал подальше от людей, как стереотипного админа, наоборот — я сел в самаю гущу разработчиков. С этого момента для меня и начался DevOps. Тогда же я узнал, что не смотря на важность знаний и скиллов, еще более приоритетным, оказалось общение и возможность прямо влиять на продукт с позиции operations, а разработчики смогли донести или корректировать свои требования задолго до поставки. Один раз попробовав этот кайф, никакого админа уже не загонишь в подвал).
Быстро выяснилось, что когда продукт проектируется, разрабатывается и эксплуатируется совместно, когда каждый отвечает за продукт и знает в общих чертах где, как и что запущено в продакшене — совсем не страшно давать доступ разработчику на “прод”. Конечно сейчас делать там нечего ни админу, ни разрабу, но лично для меня тогда — это был культурный шок — разраб на проде, а прод не лежит). Такое однозначно невозможно со стеной между Dev и Ops.
Но если DevOps — это процесс гибкой разработки, когда в него включена и эксплуатация, тогда кто такие, эти девопсы? Откровенно говоря, правильнее говорить DevOps-инженер, но для простоты я буду писать с маленькой буквы на русском. Итак, что это за люди такие — девопсы?
Это роль в команде, которую может взять на себя один или несколько крепких миддлов, не важно разработчик это, тестировщик или админ, для закрытия дыры в цикле непрерывной интеграции, поставки и эксплуатации продукта.
На мой субъективный взгляд, лучше когда этот кто-то из админской среды (но не эникейщик) — так в команде будут закрыты low-level вопросы, которые могут отвлекать или раздражать разработчиков, например апгрейд БД, configuration management или любые другие инфрастуктурные вещи. В пользу админов в роли девопсов я бы привел еще такой момент: пока живет и развивается продукт — живет и развивается DevOps в команде, он будет съедать все человекочасы и силы брошенные туда (и требовать добавки), и разработчик начнет лажать в разработке. К тому же вопросы operations ближе всего к админам — вхождение в роль будет быстрее).
Что девопсы должны знать и уметь? Мы выкладывали у себя требования для девопсов, я не буду перечислять все пункты, вкратце озвучу основные моменты.
Принципы гибкой разработки: один из важнейших навыков в современном мире разработки (и в особенности ремоута). Сюда входит не только умение отличить Канбан от Скрама, но что еще важнее — умение коммуницировать, понимать Value для заказчика, трекать время, а также внятные ворклоги и прозрачные стэндапы, документация.
Автоматизация + everything as a code: нужно как можно скорее отучаться от ручного мартышкиного труда. В настоящее время почти для каждой задачи есть свой инструмент. А если нет, всегда есть питон и баш. Например, нужно создать образ виртуалки — используй Packer, отконфигурить 10+ хостов — Ansible, создать k8s кластер в Гугл Клауде или CDN на Амазоне — terraform. Автоматизировано должно быть все, начиная от загрузки нового bare-metal сервера по сети и заканчивая деплоем контейнера в кластер. Написанный код должен быть воспроизводимым и идемпотентным, коммиты должны быть обоснованы задачей в треккере и подчиняться пункту выше.
Облачная и гибридная архитектура: в настоящее время никто не замыкается на одной платформе (и правильно). Нельзя быть фанатом и евангелистом какого-то одного решения. Различные части сервиса могут быть запущены и на AWS, и на Heroku и других IaaS, PaaS и SaaS. Необходимо находить наиболее выгодное решение и уметь мигрировать сервис между платформами в адекватный промежуток времени. Для этого конечно же не обойтись без предыдущего пункта.
Масштабирование и Высокая доступность: важно знать терпимость бизнеса к простою, к потере данных за определенный период и т.д. Бессмысленно делать HA ресурсе, который может пролежать день, и никто не заметит этого, в тоже время часовой downtime другого ресурса может стоить дороже полной хот-стендбай копии оплаченной на год вперед. Масштабирование с облаками и контейнеризацией стало гораздо проще, однако к этому должна быть готова как инфраструктура, так и сам сервис (для примера: наверное самая распространенная болячка — хранение объектов на локальном сторедже).
Мониторинг: для ретроспективы, прогнозов и реакций необходимо собирать все доступные метрики — системные, аппликейшн и бизнес. У команды должны быть глаза. К сожалению, нет универсального решения — каждый сервис и облако предлагает свой набор метрик и алярмов, но часто этого не достаточно. Можно использовать внешние системы, например Librato или Datadog; или построить свою на базе Prometheus. Все упирается в стоимость, потраченное время и задачи.
Безопасность: это не прямые обязанности девопса, однако знать элементарные вещи — must. SSL на эндпоинтах, никаких * в полиси, никаких публичных/открытых на запись бакетов, шифрование разделов, закрытые файерволлы и секьюрити группы, MFA и т.д. Плюс в коллаборации с настоящими безопасниками девопсы могут достаточно быстро автоматизировать и применять новые политики безопасности для сервисов.
Что может сделать такой специалист, придя в команду, где вроде и так все работает, где разработчики настроили окружение, разобрались как запустить базу и создали автоскейл группу. Или еще проще — запустили аппку на Heroku, добавили необходимых эддонов и спят спокойно. Есть какие-то алерты и метрики, и с виду все хорошо. Однако:
- Т.к. все обычно делается руками и мышкой — невозможно воспроизвести архитектуру или восстановить ее часть, в случае каких-либо облачных проблем.
- Не радует ценник, т.к. довольно бесконтрольно создаются ресурсы, и часто забываются, никто не делает анализ трат и не ищет/предлагает альетрнативы, никто не занимается расчетом и покупкой reserved instances.
- Нет отлаженного деплоя и консистентных тестов. Возможно нет интеграционки вообще и тесты прогоняются локально у разработчиков, да и прогоняются ли.
- Непонятные ошибки, которые проявляются только на продакшене и которые невозможно никак воспроизвести локально. Падает доверие заказчика к it-отделу, идет постоянная война с product owner’ом.
- Проблемы с производительностью сервиса и не ясна причина, сервис в основном состоит из spof, на починку тратится много времени из-за чего страдает и без того небыстрая разработка.
- Необходимо мигрировать сервис на другую платформу и/или подготовить текущую архитектуру для бурного роста.
- Мониторинг, если он есть отрабатывает слишком долго. Команда узнает о проблеме в последнюю очередь, после пользователей и заказчика.
И подобный список можно продолжать очень долго. Какие-то моменты можно решить просто пообщавшись, а в каких-то придется менять процесс разработки и поставки. Возможно понадобятся чисто технические навыки или знание конкретной платформы. Но, в любом случае даже непродолжительное участие девопса в проекте сильно повлияет на команду и процессы, происходящие в ней.
Ранее статья была опубликована тут.