Источник: Nuances of Programming
Предыдущие части: Часть 1
Сверточные нейронные сети (CNN) схожи с обычными нейронными сетями: они состоят из нейронов с обучаемыми весами и сдвигами. Каждый нейрон получает входные данные, выполняет скалярное произведение и при необходимости добавляет нелинейную оптимизацию. Вся сеть выражает одну дифференцируемую функцию оценки: начиная от пикселей «сырых» изображений и заканчивая оценкой класса. Они также обладают функцией потерь (например, SVM/Softmax) на последнем (полностью подключенном) слое.
В чем же заключаются различия? Архитектуры ConvNet делают предположение, что входные данные являются изображениями, благодаря чему определенные свойства могут быть зашифрованы в архитектуру. В результате функция пересылки становится более эффективной для реализации, а количество параметров в сети значительно уменьшается.
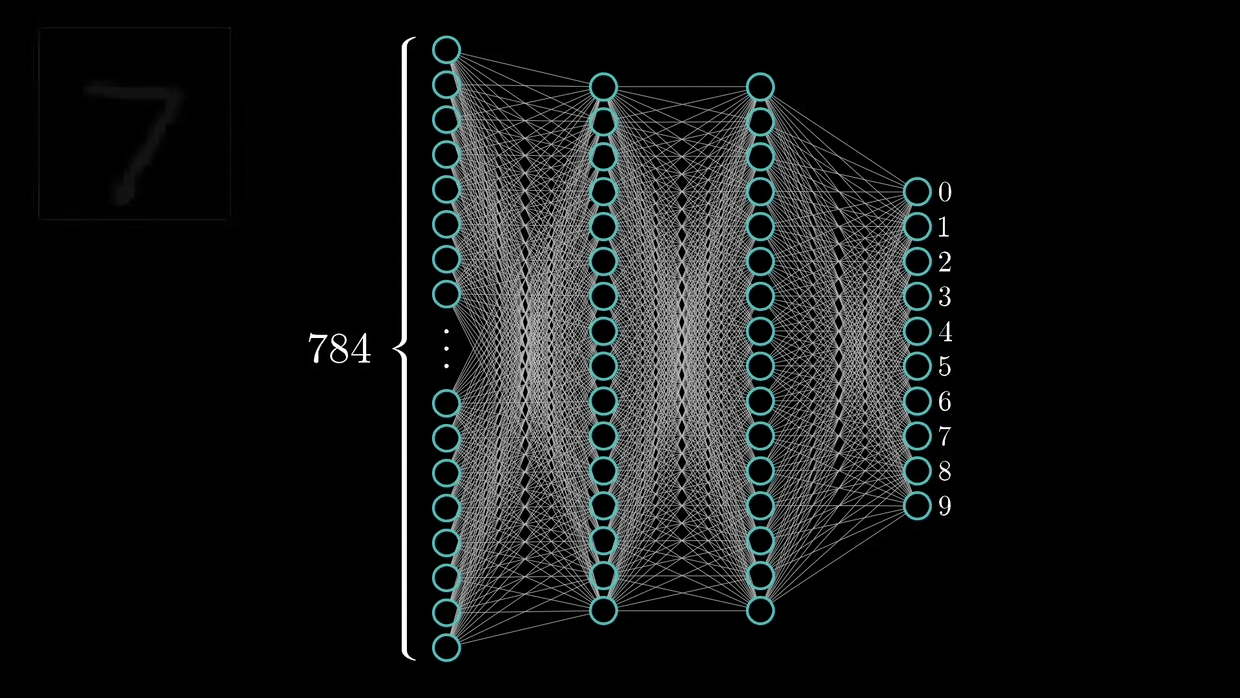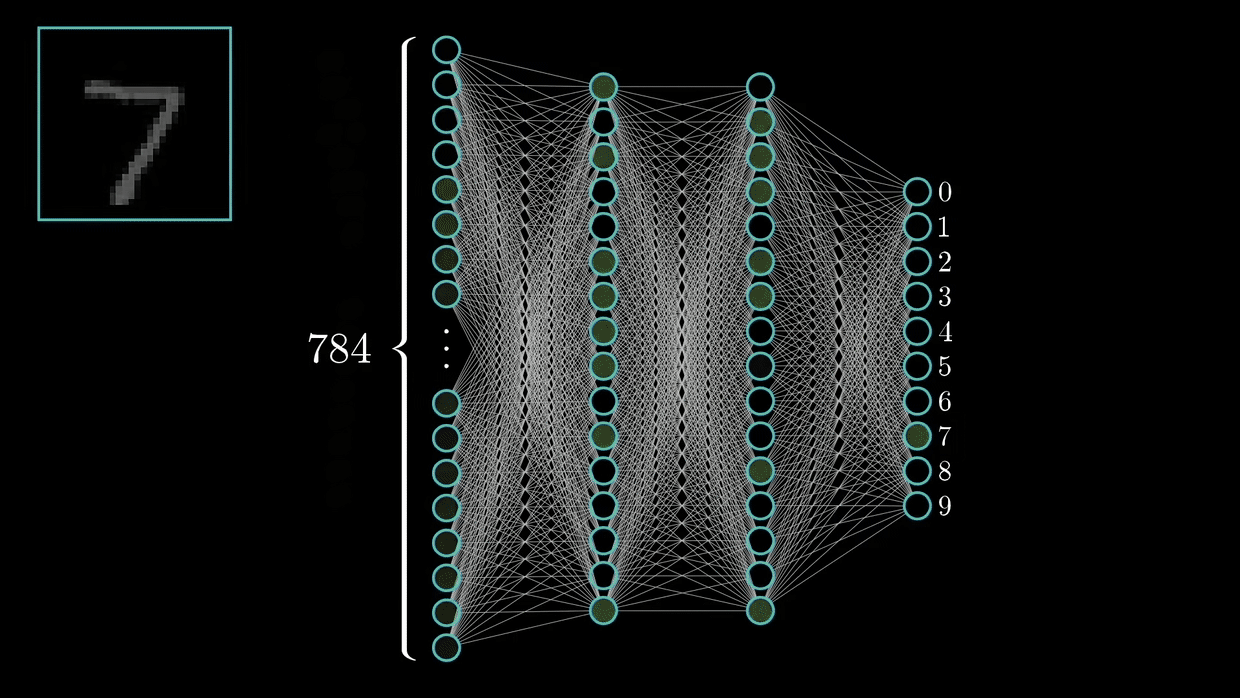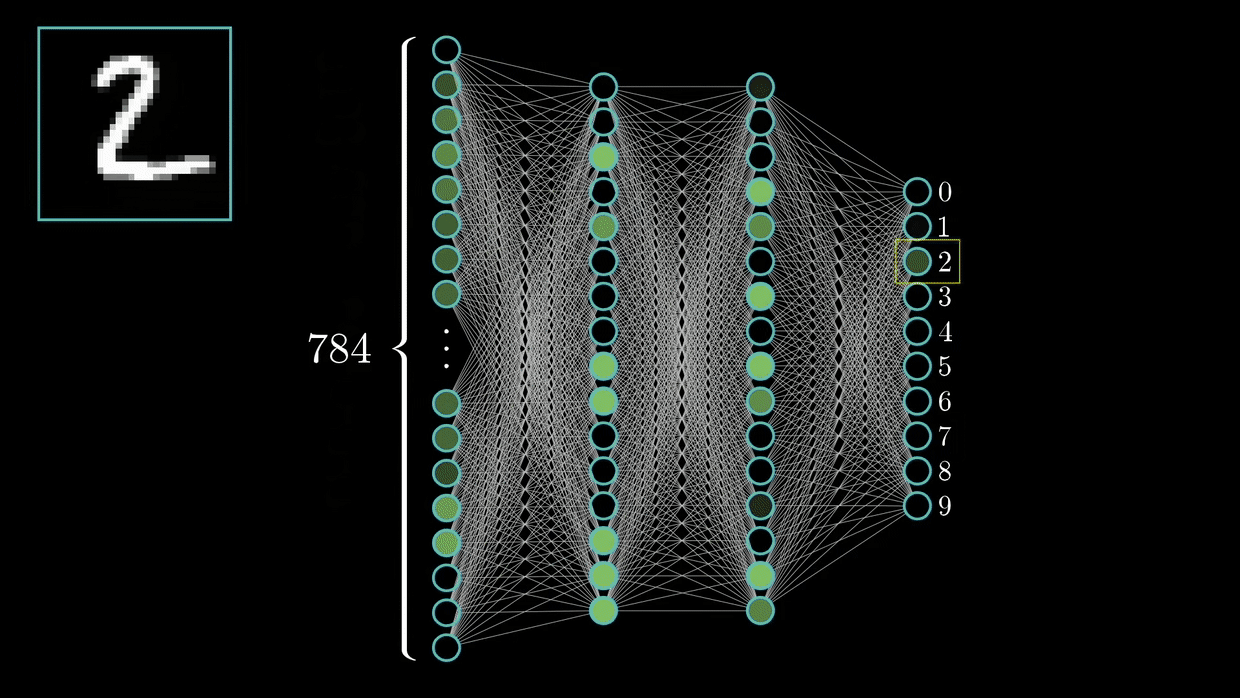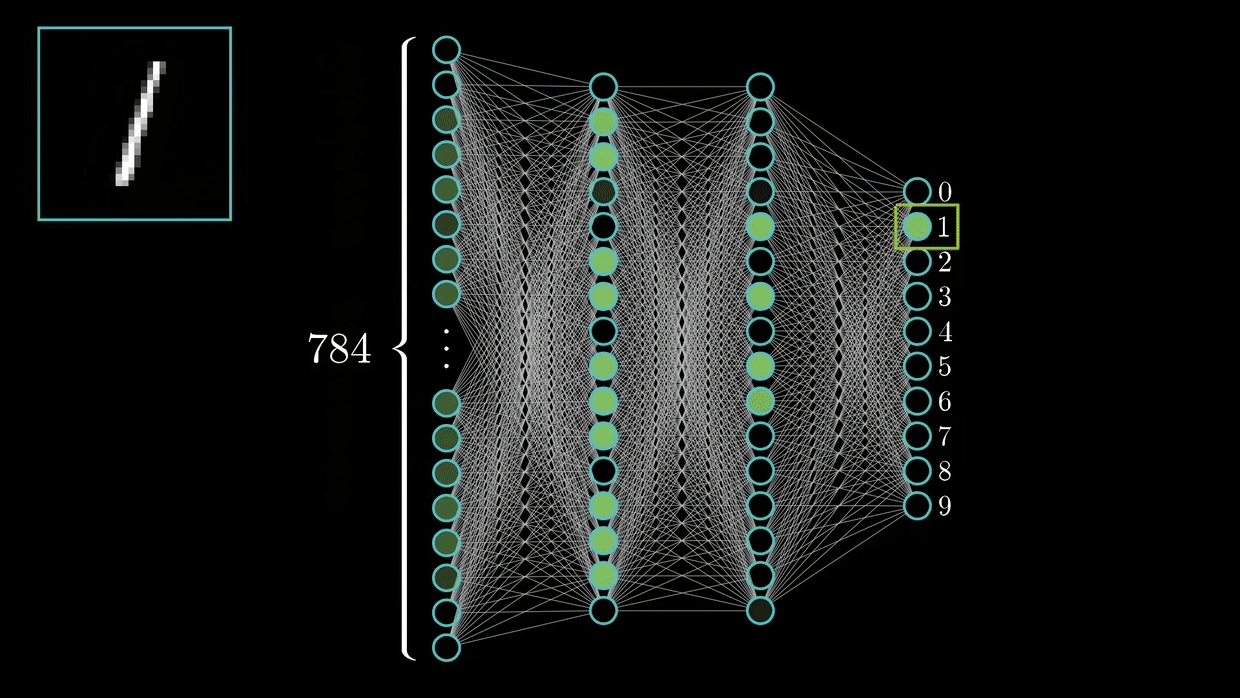
Они способны обнаруживать первичные функции, которые затем объединяются последующими слоями архитектуры CNN, что приводит к обнаружению более сложных и релевантных признаков.
Для работы с нейронными сетями мы будем использовать Google Colab — бесплатный сервис, предоставляющий GPU и TPU в качестве сред выполнения.
Реализация сверточной нейронной сети
Для начала загружаем все необходимые библиотеки:
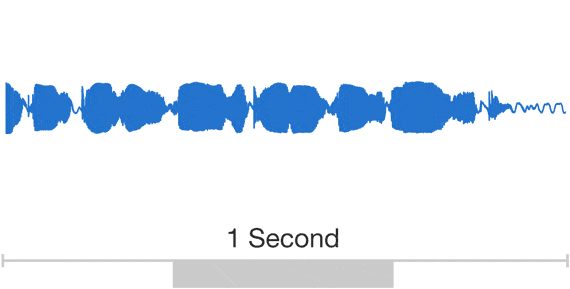
Теперь преобразуем файлы аудиоданных в PNG или извлекаем спектрограмму для каждого аудио с помощью библиотеки Python librosa:
Приведенный выше код создает директорию img_data, содержащую все изображения, классифицированные по жанрам.
Ниже приведены спектрограммы семплов:
Следующий шаг — разделение данных на наборы для обучения и тестирования.
Устанавливаем split_folders:
pip install split_folders
80% данных будет использоваться для обучения и 20% для тестирования.
Приведенный выше код возвращает две директории для обучающего и тестового набора в родительскую:
Увеличение числа изображений
Увеличение числа изображений представляет собой искусственное создание обучающих изображений с помощью различных способов обработки, таких как случайная ротация, переходы, сдвиги, перевороты и т.д.
В Keras есть класс ImageDataGenerator, значительно упрощающий этот процесс. Ознакомиться с ним можно в официальной документации Keras.
У класса ImageDataGenerator есть три метода: flow(), flow_from_directory() и flow_from_dataframe() для чтения изображений из массива и папок. Мы рассмотрим только flow_from_directory().
Он обладает следующими аргументами:
- directory: путь папки, в которой находятся все тестовые изображения. В данном случае: ./data/train
- для batch_size необходимо установить число, разделяющее общее количество изображений в тестовом наборе.
Почему это относится только к test_generator?
На самом деле «batch_size» необходимо установить как для обучающего, так и для тестового генератора. Однако, если batch_size не совпадает с числом семплов в обучающем или тестовом наборах, а некоторые изображения пропускаются при каждом получении из генератора, они будут отбираться в ближайшую обучающую эпоху. Для тестового набора выборку изображений нужно выполнить только один раз. - для class_mode устанавливаем «binary» при наличии двух классов для прогнозирования, в противном случае используем «categorical». При создании системы автоэнкодера ввод и вывод, скорее всего, будут представлены одним и тем же изображением. В этом случае устанавливаем «input».
- для shuffle устанавливаем значение False, поскольку изображения нужно выводить по «порядку», чтобы предсказать результаты и сопоставить их с уникальными id или именами файлов.
Создаем сверточную нейронную сеть:
Скомпилируйте/обучите сеть с помощью стохастического градиентного спуска (SGD). При использовании этого метода несколько семплов выбираются случайным образом вместо полного набора данных для каждой итерации.
После обучения модели CNN переходим к ее оценке. evaluate_generator() использует как тестовый ввод, так и вывод. Сначала он прогнозирует выходные данные с помощью набора для обучения, а затем оценивает производительность в сравнении с тестовым набором. Таким образом, он выдает показатель эффективности, в данном случае точность.
Модель была обучена на 50 эпохах (на выполнение на Nvidia K80 GPU потребовалось 1,5 часа). Для повышения точности количество эпох можно увеличить до 1000 и более.
Заключение
CNN — это эффективная альтернатива для автоматического извлечения признаков, что подтверждает гипотезу о том, что внутренние характеристики вариаций музыкальных данных аналогичны характеристикам данных изображений. Созданная модель CNN обладает высокой масштабируемостью, но недостаточно надежна для обобщения результатов обучения для невидимых ранее музыкальных данных. Эта проблема решается с помощью расширенного набора данных.
На этом все. Спасибо за внимание!
Читайте также:
Перевод статьи Nagesh Singh Chauhan: Audio Data Analysis Using Deep Learning with Python (Part 2)Таким образом, потеря составляет 1,70, а точность — 33,7%.
Наконец, переходим к прогнозированию на тестовом наборе данных. Перед вызовом predict_generator необходимо перезагрузить test_set. В противном случае выходные данные будут получены в странном порядке.
test_set.reset()
pred = model.predict_generator(test_set, steps=50, verbose=1)
На данный момент у predicted_class_indices есть прогнозируемые метки, однако сами прогнозы невозможно определить. Теперь нужно сопоставить эти метки с их уникальными id, такими как имена файлов.
Модель была обучена на 50 эпохах (на выполнение на Nvidia K80 GPU потребовалось 1,5 часа). Для повышения точности количество эпох можно увеличить до 1000 и более.
Заключение
CNN — это эффективная альтернатива для автоматического извлечения признаков, что подтверждает гипотезу о том, что внутренние характеристики вариаций музыкальных данных аналогичны характеристикам данных изображений. Созданная модель CNN обладает высокой масштабируемостью, но недостаточно надежна для обобщения результатов обучения для невидимых ранее музыкальных данных. Эта проблема решается с помощью расширенного набора данных.
На этом все. Спасибо за внимание!
Читайте также:
Читайте нас в телеграмме и vk
Перевод статьи Nagesh Singh Chauhan: Audio Data Analysis Using Deep Learning with Python (Part 2)