Формулы в Google Data Studio позволяют создавать дополнительные показатели, используя математические формулы, что позволяет добавлять в отчет новые метрики и характеристики.
Список формул и функций в Google Data Studio
В данный момент все формулы описаны лишь на английском языке и ознакомиться с ними можно в справке Data Studio:
https://support.google.com/datastudio/table/6379764?hl=en
Ниже приведет переведенный список функций в Студии данных на русском языке:
Синтаксис — Описание
APPROX_COUNT_DISTINCT(X) — Возвращает приблизительное количество уникальных значений X
AVG(X) — Среднее значение всех значений X
COUNT(X) — Количество значений X
COUNT_DISTINCT(X) — Количество уникальных значений X
MAX(X) — Максимальное значение X
MEDIAN(X) — Медиану всех значений X
MIN(X) — Минимальное значение X
PERCENTILE(X,N) — Процентиль ранга N поля X
STDDEV(X) — Стандартное отклонение X
SUM(X) — Сумма всех значений X
VARIANCE(X) — Дисперсия X
ABS(X) — Абсолютное значение числа
ACOS(X) — Обратный косинус X
ASIN(X) — Обратный синус X
ATAN(X) — Число, обратное касательной к X
CEIL(X) — Ближайшее целое число больше X. Например, если значение X равно v, CEIL (X) больше или равно v
COS(X) — Косинус X
FLOOR(X) — Ближайшее целое число меньше X. Например, если значение X равно v, FLOOR (X) равно или меньше v
LOG(X) — Логарифм к основанию 2 из X
LOG10(X) — Логарифм к основанию 10 X
NARY_MAX(X, Y [,Z]*) — Максимальное значение X, Y, [, Z] *. Все входные аргументы должны быть одного типа: все числа. По крайней мере один входной аргумент должен быть полем или выражением, содержащим поле
NARY_MIN(X, Y [,Z]*) — Минимальное значение X, Y, [, Z] *. Все входные аргументы должны быть одного типа, все числа. По крайней мере один входной аргумент должен быть полем или выражением, содержащим поле
POWER(X, Y) — Результат возведения X в степень Y
ROUND(X, Y) — X с округлением до Y прецизионных цифр
SIN(X) — Синус X
SQRT(X) — Квадратный корень из X. Обратите внимание, что X должен быть неотрицательным
TAN(X) — Тангенс X
DATE_DIFF(X, Y) — Разница в днях между X и Y (X - Y)
DAY(X [,Input Format]) — День месяца
HOUR(X [,Input Format]) — Час суток
MINUTE(X [,Input Format]) — Минуты
MONTH(X [,Input Format]) — Месяц
QUARTER(X [,Input Format]) — Квартал года
SECOND(X [,Input Format]) — Секунды
TODATE(X, Input Format, Output Format) — Превращает дату в формате UTC в нужный формат, например "%Y" возвращает год
WEEK(X) — Неделя года в формате ISO 8601
WEEKDAY(X [,Input Format]) — День недели
YEAR(X [,Input Format]) — Год
YEARWEEK(X) — Номер года и недели
TOCITY(X [,Input Format]) — Название города
TOCONTINENT(X [,Input Format]) — Название континента
TOCOUNTRY(X [,Input Format]) — Название страны
TOREGION(X [,Input Format]) — Название региона
TOSUBCONTINENT(X [,Input Format]) — Имя субконтинента
"CASE
WHEN C = 'yes'
THEN 'done:yes'
ELSE 'done:no'
END — Оценивает ровно одно значение на основе набора заданных логических выражений. Выучить больше"
CAST(field_expression AS TYPE) — Превращает поле или выражение в TYPE. Агрегированные поля не допускаются внутри CAST. TYPE может быть NUMBER или TEXT
HYPERLINK(URL, link label) — Превращает гиперссылку на URL, помеченную меткой ссылки
IMAGE(Image URL, [Alternative Text]) — Создает изображение из картинки в источнике данных
CONCAT(X, Y) — Возвращает текст , который является конкатенация X и Y
CONTAINS_TEXT(X, text) — Возвращает true, если X содержит текст, в противном случае возвращает false. Чувствительный к регистру
ENDS_WITH(X, text) — Возвращает true, если X заканчивается текстом, в противном случае возвращает false. Чувствительный к регистру
LEFT_TEXT(X, length) — Количество символов с начала X . Количество символов указывается по длине
LENGTH(X) — Количество символов в X
LOWER(X) — Преобразует X в нижний регистр
REGEXP_EXTRACT(X, regular_expression) — Возвращает первую совпадающую подстроку в X, которая соответствует шаблону регулярного выражения
REGEXP_MATCH(X, regular_expression) — Возвращает true, если X соответствует шаблону регулярного выражения, в противном случае возвращает false
REGEXP_REPLACE(X, regular_expression, replacement) — Заменяет все вхождения текста , который соответствует шаблону регулярного выражения в X с заменой строкой
REPLACE(X, Y, Z) — Возвращает копию X со всеми вхождениями Y в X заменяется на Z
RIGHT_TEXT(X, length) — Указывает количество символов с конца X . Количество символов указывается по длине .
STARTS_WITH(X, text) — Возвращает true, если X начинается с текста. В противном случае возвращает false. Чувствительный к регистру.
SUBSTR(X, start index, length) — Возвращает текст , который является подстрока X . Подстрока начинается с начального индекса и имеет длину символов.
TRIM(X) — Возвращает X с удаленными начальными и конечными пробелами.
UPPER(X) — Преобразует X в верхний регистр.
Как использовать формулу в Google Data Studio
В датасете
Для этого понадобится в режиме редактирования перейти во вкладку «Ресурс»-«Добавленные источники данных».
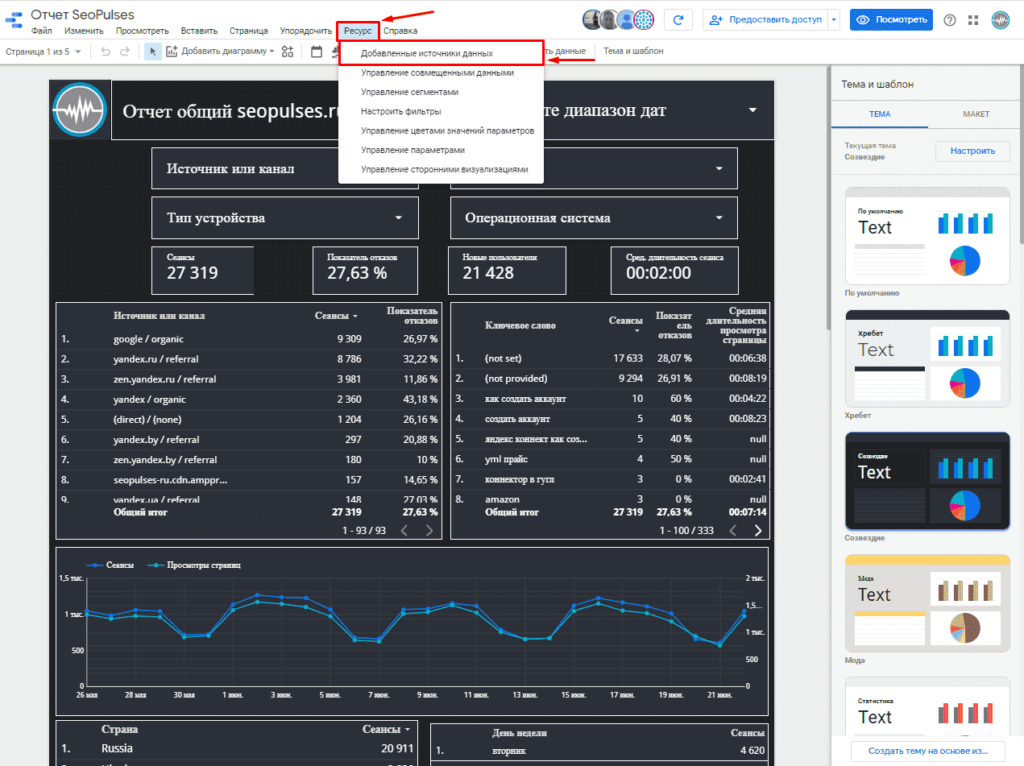
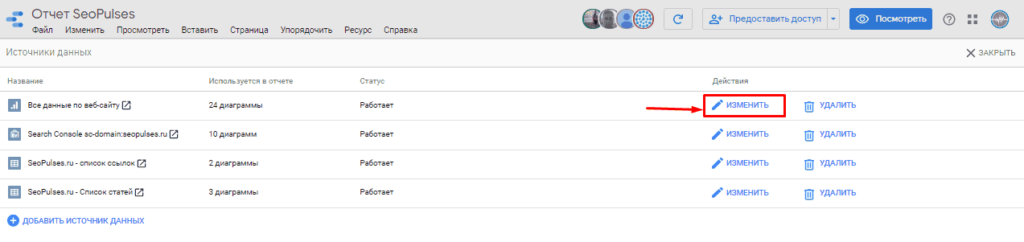
Выбираем нужный коннектор (источник данных) и нажимаем на «Изменить».
Кликаем на добавить новое поле.
Теперь потребуется:
- Даем название значению;
- Вводим формулу.
Важно! Регистр (строчная или заглавная буквы) не влияет на работу функций.
Важно! Прописывать текст можно, как и в языке Python, в одинарных кавычках ‘Текст1’, так и в двойных «Текст».
Важно! Идентификатор поля заполнять не нужно, он выдается автоматически.
Важно! При написании формулы в отличие от Excel и Google Таблиц не ставиться в начале знак «=».
Во время написания формулы система будет показывать подсказки и выдавать значения из датасета.
Если формула заполнена некорректно, то в нижней-левой части интерфейса появится соответствующее уведомление.
Пример использования функций.
В отчете
После сохранения эти данные можно будет использовать в дашборде.
Важно! При использовании этого метода, потребуется создать дополнительный показатель в каждом отдельном элементе.
В дашборде потребуется выбрать нужный элемент и кликнуть на «Создать поле».
После этого аналогично вышеописанной инструкции заполняем:
- Название;
- Описываем формулу.
Все готово метрика добавлена.
Наиболее популярные функции и формулы в Google Студии Данных
Сумма (SUM)
Позволяет агрегировать данные (суммировать).
Округление (ROUND)
Позволяет превратить цифру с длинным хвостом в нужную. Например, превращение показателя отказов в целое число.
Вводим нужную конструкцию, где 0 отвечает за отображение целого числа. Также имеется умножение на 100, так как показатель отказов в Google Analytics — это число от 0 до 1.
Задача выполнена.
CASE и END
Дает возможность использовать конструкцию ЕСЛИ, например, если канал трафика в Google Analytics organic представим его аналогично Яндекс.Метрике как поисковый трафик. Для этого создаем новый показатель.
Вводим нужную конструкцию.
case
when канал=’organic’ then ‘Поисковый трафик ‘
end
Готово.
Регулярные выражения (REGEXP_MATCH и REGEXP_EXTRACT)
Позволяют использовать регулярные выражения аналогично Google Analytics и Яндекс.Метрике в дашбордах Data Studio.
Например, из примера выше, можно сделать замену органики и рефералов на «Органический трафик» (Лишь для примера). Применяем в этом случае:
case
when REGEXP_MATCH(Канал,’^(organic|referral)$’) then ‘Органический трафик’
end
Получаем готовый вариант.
Источник: https://seopulses.ru/formuli-i-funkcii-v-google-data-studio/
Подписывайтесь на наш Telegram-канал
Подписывайтесь на наш Youtube-канал
Подписывайтесь на нашу группу ВКонтакте