
SEO-специалистам учить язык программирования вовсе не обязательно, но понимание принципов сканирования и рендеринга поможет превратить JS из помехи в союзника. Давайте разбираться, что к чему!
Речь пойдёт о технической оптимизации. Абсолютное большинство сайтов используют JS для улучшения пользовательского опыта, сбора статистики, интерактивности, загрузки контента, меню, кнопок и других элементов. Наша цель, как SEO-специалистов, облегчить процесс сканирования контента и по возможности избегать проблем, которые часто возникают при обработке страниц, использующих JavaScript.
Руководство частично основано на материалах от Ahrefs, Onely, Google Developers, за что им большое спасибо.
Как Google обрабатывает JS?
Поисковые системы пытаются получить тот же контент, что видят в браузере пользователи. В Google за процесс рендеринга и сканирования отвечает сервис обработки веб-страниц Web Rendering Service (WRS, часть системы индексации Caffeine). Вот упрощенная схема процесса:
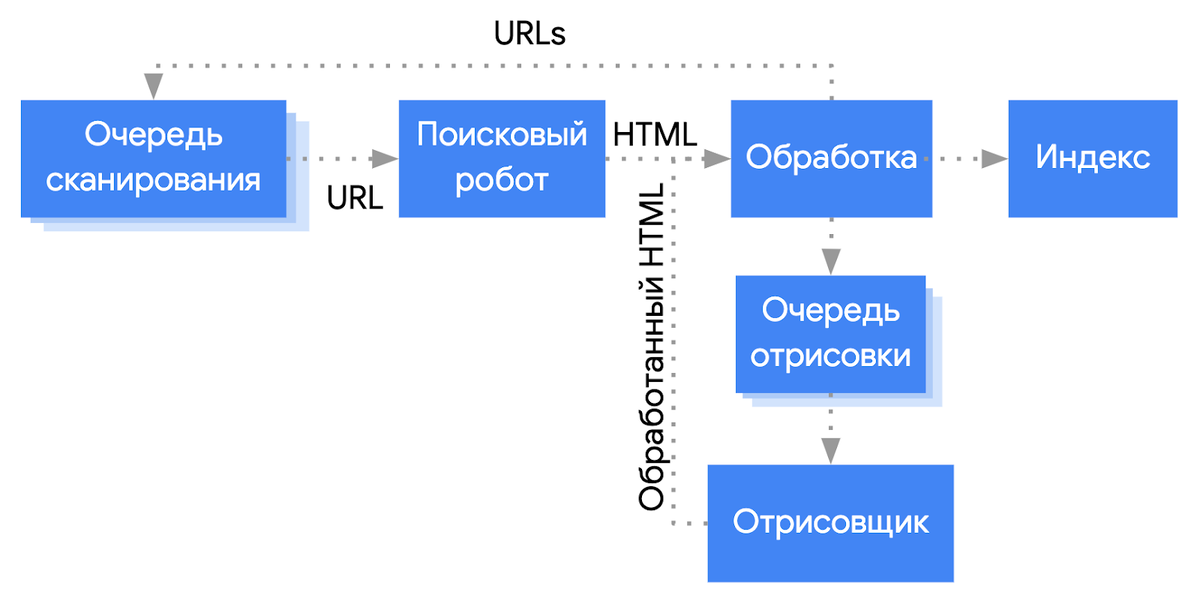
Обратите внимание, на схеме Google получает конечный HTML для обработки, но на деле сканирует и кэшируют почти все дополнительные ресурсы, необходимые для формирования страницы (JS-файлы, CSS, синхронные и асинхронные запросы XHR, точки приёма API и так далее). Почему «почти» все? Некоторые из ресурсов Googlebot и WRS могут игнорировать, как недостаточно важные для отображения контента.
Разберём процесс на примере отдельного URL.
1. Crawler (Краулинг)
Робот Googlebot отправляет серверу GET-запрос, в ответ получает HTTP-заголовки и содержимое страницы. Если в заголовке или мета-теге robots нет запрета на сканирование, то URL ставится в очередь на отображение. Подробнее о способах закрытия от индексации мы рассказывали в отдельном руководстве.
Важно учитывать, что в условиях mobile-first-индексации в большинстве случаев запрос поступает от мобильного user-agent Google. Проверить, какой робот сканирует ваш сайт можно в Search Console (раздел «Проверка URL»).
Нужно иметь в виду, что в HTTP-заголовках страницы можно настроить правила для отдельных user-agents, например, запретив для них индексацию или показывая отличный от других контент. Ниже пример запрета перехода по ссылкам для Googlebot и индексации для всех остальных.
HTTP/1.1 200 OK
Date: Tue, 25 May 2020 21:42:43 GMT
(…)
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
(…)