Привет, в этой статье я вам расскажу о структурах данных, которые так или иначе вам стоит знать если вы считаете себя программистом. Этот список достаточно спорный, и вы можете без зазрения совести вносить свои коррективы в комментариях, чтобы сделать эту статью ещё лучше.
Если вы не знаете, что именно означает, термин «структура данных», то вы вероятнее всего новичок. Структура данных — это способ хранения данных в вычислительной технике, то есть в компьютерах. Если вы не понимаете зачем всё это нужно, то вот простой пример: в библиотеке мы храним книги вертикально, а не горизонтально, потому что их легче достать. Тоже происходит с компьютерными данными, мы используем разные структуры данных чтобы получить некоторые преимущества в конкретной ситуации, например быстрый доступ к данным, быстрое удаление, быстрая вставка. У нас есть куча разных вариаций как эти данные можно хранить, и все они используются для конкретных целей. Нетрудно догадаться, что все они разные, какие-то похожи между собой, каки-то отличаются кардинально, но, в общем и целом, на данный момент времени у нас есть структура данных, для решения любой задачи. Я вам расскажу о структурах данных, которые встречаются чаще всего, и следовательно, для решения 90% задач этих структур данных вам будет достаточно.
LINKED LIST
Первое с чего я начну, это связный список или linked list. Преимущества: быстрая вставка данных и их удаление. Размер связного списка не обязательно должен быть фиксированным во время компиляции, и он может меняться во время runtime динамически в сравнении с нативным массивом, связный список состоит из так называемых node, каждый node содержит данные и указатель, на следующую или предыдущую ноду, в зависимости от того какой именно, список вы используете. Недостатки: занимает больше памяти т.к. кроме данных в ноде ещё храниться один или два указателя. И помимо всего этого, долгий поиск элементов.
ARRAY
Массив это вообще фундаментальная структура данных, на основе которой сделаны многие другие структуры. Фишка массива в том, что доступ к элементам происходит за константное время, то есть очень быстро в смысле семантического анализа. Минус использования массива в том, что размер должен быть фиксированным во время компиляции, и не может изменяться динамически. Удаление элементов затратное с точки зрения производительности, так же, как и добавление. Массив хорош для хранения и доступа к данным, а связный список для манипуляции с этими данными.
QUEUE
Следующая структура данных, которые мы должны знать это очередь queue, структура данных также называется FIFO, то есть first in first out, первый зашёл первый и уйдёшь. То есть работает по принципу обыкновенной очереди, тут всё просто. Пример: ваша операционка, когда у вас всё зависает, вы кликаете мышкой, и наживаете все кнопки на клавиатуре, после того как ваш комп всё таки отлагает, все эти события выполняться именно в том порядке, в котором вы их нажимали.
STACK
В качестве противоположности мы имеем структуру данных, которая называется stack, LIFO, last in first out. Стек вообще используется везде начиная с вашего процессора, и вплоть до браузера, принцип работы также прост. Представьте стол, на который вы складываете книги по одной и потом так же по одной их забираете, именно та книга, которую вы положили на стол первой, последней со стола и уйдёт. Пример: с функцией или методом main в C++ или Java, main идёт на самое дно стека, а уже на него кладутся все стольные функции, и методы из вашей программы, пока main не завершиться, а завершиться он последним, ваша программа будет работать. Очень удобная структура данных.
PRIORITY QUEUE
Так же у нас есть очередь с приоритетом, или priority queue. ведёт себя идентично обычной очереди, но output зависит от конкретной реализации. Мы зададим, какой-то ключ или параметр, по которому будет вычисляться приоритет самого аутпута. Скажем у нас есть очередь, с задачами для программиста, и как только он закончит с одной задачей, он переходит к следующей, самой приоритетной. Используется в таких алгоритмах как A*- алгоритм поиска кратчайших путей от точки а к точке б, алгоритм создаёт некий лист, и с помощью приоритетной очереди вычисляет какой путь самый короткий.
HASH TABLE
Двигаемся дальше к структуре данных, которая называется hash table. Это по сути своей массив только вместо индексов, мы можем использовать так называемые хеш-коды, которые мы можем создавать сами, или использовать уже готовые хеш-функции. Пример использования может быть следующим, представьте, что у вас есть библиотека и основная фича — это мгновенный доступ к книге по её названию. Каждую книгу, которую вы добавляете в вашу библиотеку вы прогоняете через программу, передавая туда название книги вы получаете хеш-код и используя этот хеш-код вы узнаёте, где именно лежит ваша книга. Шикарно поехали дальше,
BINARY TREE
Есть такая структура данных как бинарное дерево, ассоциации со словом бинарное у меня в последнее время негативные так как я сразу думаю о каких-то там биржах, где кидают народ, но тут мы никого кидать не будем, а будем учить структуры данных. И так бинарное дерево или binary tree, это коллекция node каждая из которых имеет ещё две ноды выглядит это примерно вот так.
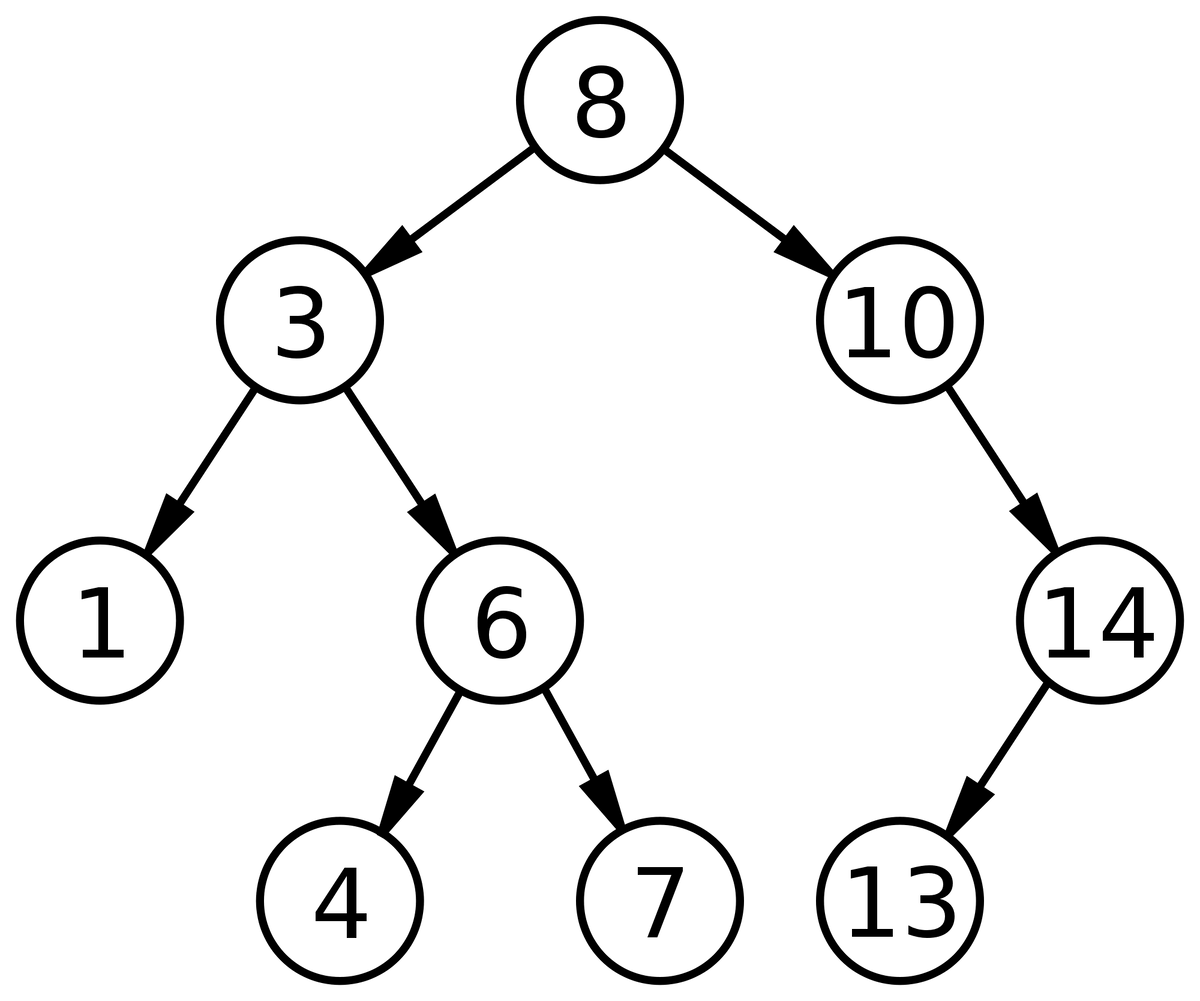
Используется часто для преобразования алгоритмов с линейной сложностью, в сложность log n грубо говоря для ускорения, также бинарное дерево используется для алгоритма компрессии huffman или скажем в конструировании компилятора, а именно синтаксического дерева.
На самом деле до того, как написать этой статью я хотел вставить сюда ещё чёрно-красные деревья, графы, векторы и матрицы, но потом решил, что эти структуры данных специфические и знание их зависит от сферы в которой вы работаете а в то время как эти сем структур нужны везде и каждому. Если вы заметили, то я специально не говорил о синтетическом анализе этих структур, потому что я планирую написать отдельную статью об этом, и вообще о том, как вычислять сложность алгоритмов и структур данных. Я надеюсь, что после прочтения это статьи вы станете чуть лучше, найдёте для себя что-то полезное или повторите забытое.