What is Data Reconciliation?
Data reconciliation (DR) is a term typically used to describe a verification phase during a data migration where the target data is compared against original source data to ensure that the migration architecture has transferred the data correctly.
During data migration, it is possible for mistakes to be made in the mapping and transformation logic. Also, runtime failures such as network dropouts or broken transactions can lead to data being left in an invalid state. These problems can lead to a range of issues such as:
- Missing records
- Missing values
- Incorrect values
- Duplicated records
- Badly formatted values
- Broken relationships across tables or systems
Reconciliation criteria
- Keep checks as simple as possible
- The result should be presented as a list (table) of "bad" data in the tables (files) we checked.
- The decision to fix bad data should be made as a result of the work of this script.
- All checks should perform very fast
The structure of the reconciliation project
The project is a spark-submit job
Build package.zip
To make this project work there is a need to gather all dependencies together in one file that will be sent to all cluster nodes with --py-files argument
bash calcDQ/build.sh
Run a job
src - source table (file) dst - destination table (file) j - JSON config
spark-submit --master yarn \
--py-files recon/package.zip \
recon/run.py -src sandbox_apolyakov.recon_source -dst sandbox_apolyakov.recon_dest -j recon/table_name_recon_config.json
Recon package checks
policies.validation.int_validator - args: tolerance: Performs the comparison between int type values with the given tolerance (optional)
policies.validation.string_validator - Performs the comparison between string type values
policies.validation.date_validator - Performs the comparison between date type values
Package file structure
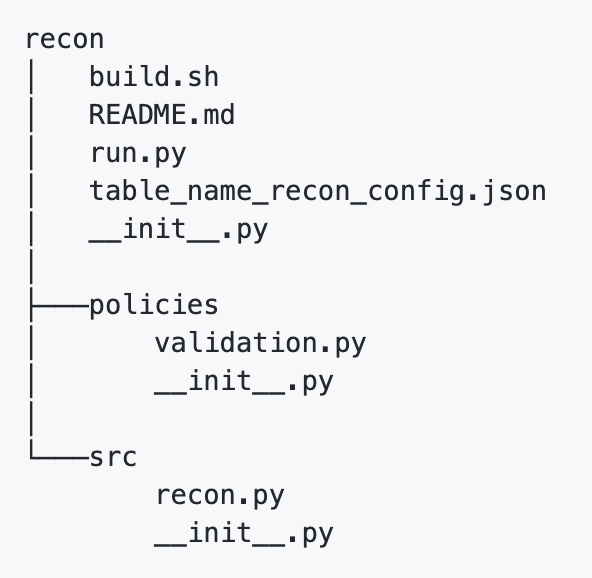
Entry point - run.py
- build.sh - Execute everytime on policies, src folders update
- table_name_recon_config.jsonConfig - file to compare two data sets
- policies.validation - Validations
- src.recon - Application source code
An example of a configuration json file table_name_recon_config.json
{
"key": "id",
"col_1": {
"dst_column_name": "name",
"src_column_name": "name",
"validation": {
"properties": {},
"validationMethod": "string_validator"
}
},
"col_2": {
"dst_column_name": "age",
"src_column_name": "vozrast",
"validation": {
"properties": {
"tolerance": 0.1
},
"validationMethod": "int_validator"
}
},
"col_3": {
"dst_column_name": "day",
"src_column_name": "day",
"validation": {
"properties": {},
"validationMethod": "date_validator"
}
}
}
- key - The unique name of an ID (identity) column. It should be named similar in both tables.
- col_* - The placeholder to store data for every column checked
- dst_column_name - The column name in destination table (file)
- src_column_name - The column name in source table (file)
- validation - Validation options for a column
- properties - Validation parameters
- validationMethod - Validation method
How it works
- Get data from tables we have got in script arguments src and dst
- Validation politics are applied to every column of every row
- The data that did not pass the validation is stored into dataframe that can be written into any database or file later on
Reconciliation process does not affect data ingest and data integration processes. It works in parallel with existing processes and helps engineers to measure a quality of data ingestion processes
Init code
Init test data for Hive
drop table if exists sandbox_apolyakov.recon_source;
create table sandbox_apolyakov.recon_source (
id int,
name string,
vozrast int,
day date
);
insert into sandbox_apolyakov.recon_source values
(1, 'Dow', 33, '2018-07-13'),
(2, 'Pits', 122, '1917-04-12'),
(3, 'Chris', 38, '2001-05-26'),
(4, 'James', 21, '2001-05-26'),
(5, 'Penelopa', 38, '2001-05-30');
drop table if exists sandbox_apolyakov.recon_dest;
create table sandbox_apolyakov.recon_dest (
id int,
name string,
age int,
day date
);
insert into sandbox_apolyakov.recon_dest values
(1, 'Dow', 33, '2018-07-13'), -- valid
(2, 'Pits', 120, '1917-04-10'), -- invalid age (122 -> 120) and date (1917-04-12 -> 1917-04-10)
(3, 'Charles', 38, '2001-05-26'), -- invalid name (Chris -> Charles)
(4, 'James', 200, '2001-05-26'), -- invalid age (21 -> 200)
(55, 'Penelopa', 38, '2001-05-10') -- invalid date (2001-05-30 -> 2001-05-10) and Index
;
Tests was performed on Hadoop Hortonworks 2.6.5, Spark 2.3.1, Python 2.7
Example
An example of a full join operation with the given src and dst data sources
There is a new row is created per every invalid column of every row.
If one row with 3 invalid columns is reconciled - the result will have 3 rows with the description of every invalid check between src and dst tables (files)
Code and README.md you can find on github