Доброго времени суток!
Поступило мне задание написать модуль взаимодействия с базой данных вокруг которой можно было бы обернуть поисковую систему.
Базой данных была выбрана SQLite3, и отказаться на данный момент от нее нельзя.
Так же, система должна хорошо масштабироваться горизонтально.
Мы будем работать только с входными данными и как они поступают в базу данных нас, в данный момент, не сильно интересует. Просто скажу что вариантов для этого масса. Так же мы не будем использовать готовые поисковые системы вроде ElasticSearch.
Начнем с введения и концепции системы.
У нас есть готовая база данных SQLite3 в которой есть таблица main с полями: title (Заголовок), description (Описание), path (Путь до файла).
Все поля носят текстовый характер.
Так же у нас есть поисковый запрос, скажем, "Фото слона в Африке".
Наша задача состоит в том, что бы найти максимально подходящий по смыслу файл используя поисковый запрос, название и описание файла.
Казалось бы все очень просто, ведь в SQLite3 есть операторы LIKE и MATCH, которые, в свою очередь, ищут вхождения и совпадения соответственно.
Вот пример:
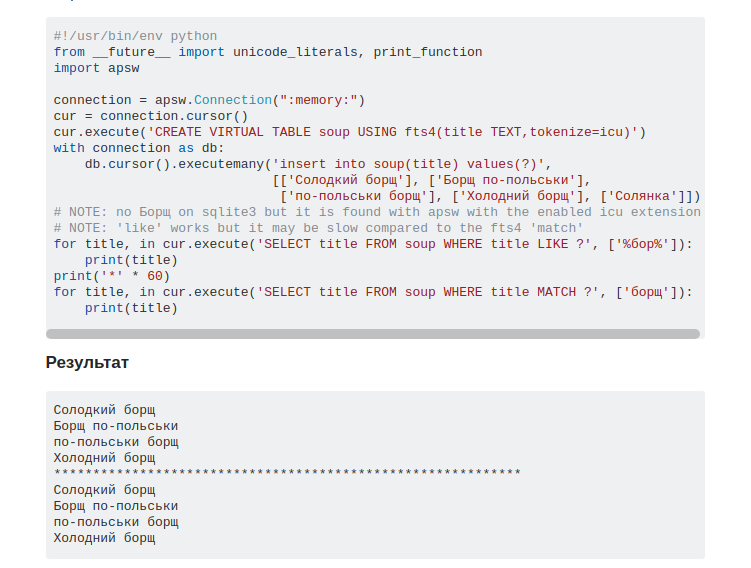
Однако эти операторы нам не подойдут, поскольку они чрезвычайно медленные, а так же плохо поддаются масштабированию.
Но концепция их нам подходит.
Нам нужно найти совпадение слов в поисковом запросе и полях базы данных.
Если посмотреть в сторону готовых поисковых систем, то там высокая скорость обработки данных достигается с помощью индексации полей.
Индексация. А что такое индексация?
Индекс - это своего рода маячок, указатель, который помогает нам быстро понять к какой категории принадлежит строка в базе данных.
Индексация - это процесс создания таких маячков для каждой строки в базе данных.
Представьте что Вам нужно доставить письмо.
Но при этом дома на вашей улице не содержат номеров, в прочем как и квартиры. Получается Вам придется заглядывать в каждую квартиру от дома к дому и спрашивать "Не Ваше ли это письмо?".
На это потребуется довольно много времени, не так ли?
Гораздо легче если бы на домах и квартирах были бы указатели, которые говорили бы нам о том, кто там живет.
То же самое и с базами данных.
Индексы и есть те самые указатели на домах.
Без индексации полей база данных будет просто перебирать каждое поле в каждой строке в надежде найти совпадения, и так, пока она не переберет их все. Ладно если строк 10-15. А если их миллион? То то и оно.
Поэтому для того что бы реализовать нашу идею нам необходимо проиндексировать все строки и поля, поставив тем самым на них указатели, а потом при запросе быстро по этим указателям обращаться.
Таким образом нам нужно создать две новых таблицы:
1) Таблица с название words в которой будут поля (id, word)
2) Таблица с названием indexes в которой будут поля (id, word_id, row_id)
В таблицу words мы будем записывать слова, которые мы будем получать разбивая текстовые предложения из полей title и description по словам и приводя эти слова к их изначальной форме, например "слона" > "слон".(Этот процесс называется токенизация текста).
А в таблице indexes мы будем создавать наши указатели, соотнося слова со строками в которых они находятся.
Таким образом если поисковый запрос будет "борщ", то мы получим все поля в которых есть слово "борщ".
Если поисковый запрос будет "Фото слона", мы получим все поля в которых содержаться слова "фотография" и "слон".
К тому же, поскольку это будет обособленный модуль, его можно подключать на разные машины к разным базам данных, за счет чего достигается масштабирование.
С планами определились, пора переходить к реализации.
Для начала нам надо создать базу данных с тестовыми данными.
Для этого создадим файл config.py в который запишем название текущих баз данных.
Далее создаем файл database.py с помощью которого мы будем взаимодействовать с основной базой данных и создавать тестовые данные для проверки работы модуля.
Для всех моих модулей баз данных я использую заранее созданную мной заготовку которую считаю наиболее оптимальной. Она не позволяет плодить атомарные подключения, не держит открытыми подключения и курсоры, а так же позволяет работать из разных частей приложения в рамках одного класса.
Как обычно, воспользуюсь ей:
Как вы видите я уже передал данные о названии базы данных из config.py
Теперь осталось создать нашу с вами таблицу main.
Для этого добавим её название в список "tables_list" в 74 строке, а так же создадим новую функцию с названием create_table_main, которая будет создавать эту таблицу в случае её отсутствия, а так же создадим функцию write_to_table_main которая поможет нам записать данные в таблицу.
Теперь нам осталось создать точку входа, инициализировать класс и обратится к функции write_to_table_main для того что бы записать тестовые данные.
Вот таким вот образом.
Запускаем файл и на выходе получаем готовую базу данных для теста.
Далее перейдем непосредственно к созданию модуля, который будет индексировать нашу, только что созданную, базу данных.
Для этого воспользуемся все той же заготовкой которая была описана выше.
Но в этот раз мы сразу её немножко подверстаем:
1) Мы заранее импортируем библиотеки "re" и "pymorphy2", "collections". Они понадобятся нам для того что бы провести токенизацию текста.
pymorphy2 - сторонняя библиотека. Для её установки воспользуйтесь инструкцией: https://pymorphy2.readthedocs.io/en/latest/user/guide.html
2) В функции __init__ мы добавим второй объект подключения к базе данных. Поскольку в рамках этого модуля мы будем работать как с бд в которой хранятся индексы, так и с бд в которой хранится информация.
3) Мы поменяем наш декоратор подключения добавив в него еще один уровень, который будет принимать как аргумент тип бд к которой мы хотим подключится при запросе. Если main - то основная бд. Если мы ничего не указываем - то бд с индексами.
Так же по аналогии с предыдущим модулем мы создаем необходимые нам таблицы в базе данных. Их две, indexes и words. Структура таблиц описана выше.
Создаем файл database_index.py и вносим все вышеописанные изменения.
Вот полный код:
Отлично!
Теперь нам осталось создать функцию которая индексировала бы поля.
Создадим функцию "indexing", используя декоратор с аргументом db='main', поскольку будем работать с основной базой данных.
В ней мы создадим запрос с помощью которого получим все строки из этой базы данных.
Далее, для каждой строки мы склеиваем название и описание (можно сделать по другому, но для более быстрого примера этот вариант подойдет. Обычно в поисковых системах можно выбрать где искать: в описании, в названии, или везде), разбиваем этот текст на слова с помощью функции re.findall в качестве аргумента передав регулярку для поиска слов от 2 символов и более - r'\w{2,}', а так же сам текст.
Ну и приводим эти слова к изначальной форме с помощью функции parse библиотеки pymorphy2. Но обращаться мы будем к экземпляру класса pymorphy2.MorphAnalyzer() который мы создали в функции __init__ в переменной morph.
Далее готовые слова мы записываем в список и посылаем в функцию create_index нашего класса, которую мы позже создадим.
Вот код функции indexing:
Ну и далее нам осталось буквально мелочи.
Создаем функцию insert_words - которая будет записывать слова в изначальной форме и присваивать им id.
После чего создаем функцию create_index - которая будет сопоставлять id слова и id строки.
Ну и функция search_row_by_words для того что бы проверить что все работает и получить результат.
Код:
Создаем точку входа и смотрим результат:
Если все сработало результат будет вот таким:
[((1,), 2), ((5,), 1)]
Вот и все!
Конечно мы можем добавить доработки в этот код, например сейчас создаются дубли при индексации, или можно вынести токенизацию в отдельную функцию, поскольку надо токенизировать и поисковый запрос тоже, ну и так далее, но этот код создавался в первую очередь что бы объяснить и показать принцип индексации и поиска по словам в SQLite3.
Для продакшена его использовать нельзя.
Полноценные готовые файлы вы можете найти по ссылке:
https://github.com/Stormx480/sqlite3_indexing
Так же по этой теме:
1) Индексы в базах данных более подробно: https://www.youtube.com/watch?v=ZuUnlJFWPkA
2) Как работает ElasticSearch: https://habr.com/ru/post/489924/