Завершая цикл выпусков о хранении данных в памяти, осталось рассказать подробно про символьный тип данных.
Символьный тип данных предназначен для хранения символов. Символы - это буквы алфавита, цифры, пробел, знаки препинания, математические знаки и всё остальное, что мы можем напечатать на клавиатуре. Но не только. Есть так называемые служебные символы: их не видно на экране или на бумаге, но они есть и заставляют компьютер что-нибудь делать.
Например, если текст разбит на строки, то в конце каждой строки присутствует служебный невидимый символ "перенос строки", который и заставляет компьютер начинать новую строку. Есть также символ, который заставляет компьютер пищать, если вы попробуете его вывести на экран.
Как и всё остальное, символы хранятся в памяти компьютера в виде, конечно же, чисел. Каждому символу назначено своё число, или код.
На хранение всех возможных символов изначально выделили один байт. Так как максимальное значение байта это 255, то всего было создано 256 символов (включая код 0).
Для этих символов составили таблицу, которая получила название ASCII (American Standard Code for Information Interchange), то есть "американский стандартный код для обмена информацией".
Кодируя и раскодируя символы с помощью этой таблицы, программисты получили возможность хранить тексты в памяти компьютера и главное – она стала единой системой для всех, а не только для американцев.
В начале таблицы расположены служебные символы, потом различные знаки препинания, потом цифры, и только потом начинаются буквы алфавита. Первая буква латинского алфавита "А" имеет код 65, затем "B" – 66, и далее по порядку. Я выделил в таблице цифры и буквы, чтобы было легче их найти. Большие и маленькие буквы – это разные символы и имеют разные коды. Если "A" это 65, то "a" это 97.
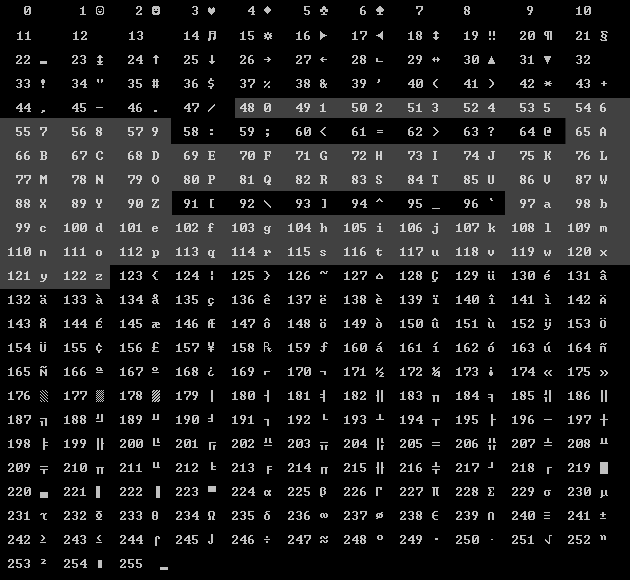
Всю вторую половину таблицы (начиная с кода 128) занимает т.н. псевдографика. То есть разработчики впихнули все нужные знаки, цифры и буквы в первую половину, и затем стали чесать репу – есть еще много места в таблице, что же придумать еще? И придумали всякие линии, уголки, квадратики, закорючки, которые не имеют никакого смысла, но если их печатать на экране, то можно нарисовать с их помощью какую-нибудь таблицу, например. Поэтому они и называются псевдо-графикой. Это графика, нарисованная с помощью символов. Творческие люди немедленно взялись рисовать произведения искусства с помощью разных символов. Это направление искусства стало называться ASCII-art и процветает до сих пор.

Но потом всё стало не так просто. Как только компьютеры стали появляться в СССР и других странах, все сразу заметили, что латинские-то буквы в таблице есть, а русских например нет, греческих тоже нет, арабских и японских тоже нет. В общем, американцы, когда создавали её, думали только о себе.
Тогда каждая страна стала добавлять в таблицу ASCII свои собственные алфавиты. А так как в таблице уже не было свободного места, то национальные алфавиты стали помещать вместо псевдографики, во вторую половину.
Но как будто было мало печалей, появилось несколько версий таблицы с русским алфавитом, потому что разные организации изобретали свои стандарты. Например, русские буквы имеют разную кодировку в операционных системах DOS, Unux и Windows. И чтобы правильно воспроизвести на экране русские буквы, необходимо было знать, какая кодировка используется. Еще недавно кодировки CP-866, Windows-1251 и KOI8-R были всем знакомы и создавали множество проблем. Часто страницу сайта или электронное пиcьмо нельзя было прочитать, потому что они были в неправильной кодировке и на экране вместо русского текста появлялась абракадабра.
С развитием технологий стало понятно, что так дальше жить нельзя и нужно сделать одну-единственную кодировку для всех языков и уже не мучаться. Так появилась таблица Unicode. Если в таблице ASCII можно сохранить только английский и еще какой-нибудь один алфавит, в Unicode стало возможным сохранить вообще все алфавиты.
Почему? Потому что символ в Unicode занимает не 1 байт, а 2 байта, и значит можно задать не 256, а 65536 символов.
Позже появились новые версии Unicode, где символ может занимать и 3 и 4 байта, но это уже детали, которые нам сейчас знать необязательно.
Подытоживая сегодняшний выпуск,
Символы в ASCII – это классические символы, размером в 1 байт.
Символы в Unicode – это современные символы, размером 2 и более байт. Они используются для представления всех мыслимых и немыслимых алфавитов (включая даже клингонский), а также картинок-эмодзи, которые по факту тоже являются символами.
Мы, как программисты, под символьным типом будем понимать классические однобайтные ASCII-символы. Интереса или необходимости что-то делать с Unicode практически нет, это вещь в себе.
Текст получился больше, чем я ожидал, а еще надо рассказать про строки.
Вкратце, строки - это символы, расположенные в памяти друг за другом, подряд. Строка может состоять из классических однобайтных символов или из многобайтных Unicode-символов. Собственно, всё.
В следующих выпусках я уже начну рассказывать про языки программирования, и заодно расскажу больше подробностей про строки, потому что разные языки работают со строками по-разному.