Обратила внимание, что по некоторым моментам, которые во время учёбы вызывают затруднение, в реальных проектах вообще не парятся.
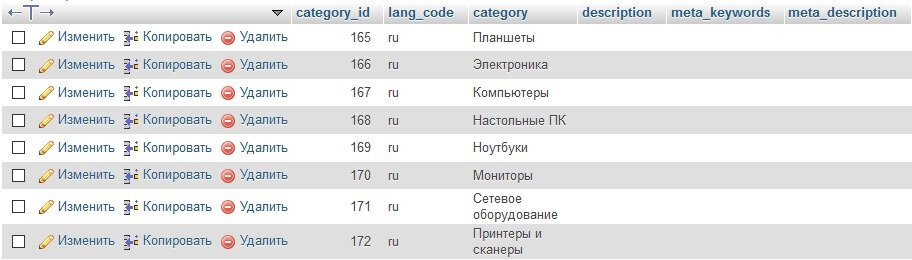
Когда студенты только начинают изучать базы данных, то мучаются, выбирая, что назначить первичным ключом. В таблице с данными о людях может быть это будет номер паспорта? Разработчики реальных баз над таким вопросом не ломают голову вообще, они просто создают ещё одно дополнительное поле, содержащее id - идентификатор. В таблице Клиенты оно будет называться Client_id, в таблице Товары - Good _id.
В таком подходе есть ещё дополнительные преимущества. Так как это поле добавляется к таблице искусственно и не зависит от других, то значения в нём - это просто порядковые номера. Отпадает необходимость создания составного ключа. Такому полю прописывается auto_increment, и значения прописывает сама СУБД. Исключаются человеческий фактор и вероятность ошибки.
А ещё таблицы с нормальными формами чертят только на сферических рабочих местах в вакууме. В реальной жизни решения принимаются проще: "Есть таблица Покупатели и таблица Товары. Один покупатель может купить много товаров, и один и тот же товар могут купить много покупателей, следовательно между ними должна быть какая-нибудь ещё таблица, например, Покупка, которая будет содержать id покупателя, id товара, дату, и, конечно, первичный ключ - id покупки."
Наверняка есть ещё какие-то отличия, которых я не заметила. Было бы интересно узнать ваше мнение.