Сейчас занят тем, что улучшаю наши библиотеки для работы с биржами, и приходится читать много tcpdump-ов всего того, что было послано по сети. Занимаясь этим почти полную неделю открыл для себя пару приемов.
Перемотка фрейма
Если вы работаете с каким-то фреймо-ориентированным протоколом, например websocket или EUREX ETI, но как правило, первые байты в них отведены полю "размер сообщения", затем идёт само сообщение. Как при этих вводных быстро перейти к следующему сообщению?
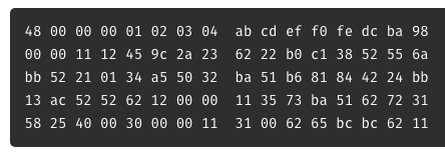
Например, тут: 48 00 ... это начало первого сообщения. 48 это в шестнадцатеричной системе. Как найти начало второго сообщения? Раньше я переводил 48 в десятичную, будет 72, затем отсчитывал 72 символа. И получается 31 00 ... (в последней строке) это начало следующего сообщения. И тут я понял, что hexdump показывает по 16 байт в строке, то есть переход к следующей строке - это +10 в шестнаднатиричной системе. Так что если размер сообщения 48 (шестнаднатиричные), то надо пропустить 4 строки и 8 символов, так просто!
ASCII из шестнаднатиричного вида
[hexdump -C] предоставляет удобный интерфейс для работы как с бинарными, так и с текстовыми протоколами. Но порой достать сообщение и посмотреть его в hexdump довольно сложно, а протокол текстовый. Я вынес для себя пару совсем простых правил. В шестнадцатиричном представлении 30 соответствует символу 0. Так что 30-39 это просто "убрать переднюю 3". 40 соответствует "символу перед A", что удобно - мы знаем что A - первая буква, то есть 40 + 1. Таким образом 41-45 легко считываются как A, B, C, D, E соответственно. Таким же образом 60 это "символ перед строчной a".
Успешной отладки!