При работе с данными часто приходится работать с временными характеристиками объектов. Чтобы этот процесс сделать удобным и быстрым в pandas, придется немного постараться.
Сразу перейдем к работе с реальными данными. Допустим, мы скачали набор данных, в котором данные не приведены к необходимым типам. Это неудобно, так как с данными строкового или иного "невременного" типа невозможно напрямую выполнять операции, связанные с использованием временных разниц. В моей базе данных есть информация об облигациях федерального займа, которые я и выгружаю в pandas.
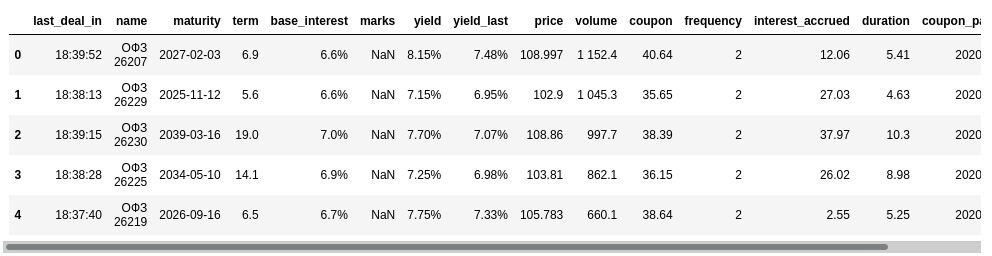
Как мы видим, данные, которые описывают дату и время, представлены как тип object. Начнем их приобразовывать к нужному нам типу.
Самая простоя задача - изменение типа без изменения информации - для этого в pandas есть метод .to_datetime(). Возьмем колонки maturity и coupon_payable и преобразуем их к новому типу. Помимо данных, указываем желаемый формат (гггг-мм-дд).
ofz_df.maturity = pd.to_datetime(ofz_df.maturity, format='%Y-%m-%d' , errors='coerce')
ofz_df.coupon_payable = pd.to_datetime(ofz_df.coupon_payable, format='%Y-%m-%d', errors='coerce')
Параметр errors='coerce' позволит избежать ошибок типа "ValueError: time data 0000-00-00 doesn't match format specified" из заполнить эти строки значениями NaT.
Теперь задача посложнее. В колонке last_deal_in содержится информация о времени последней сделки, однако отсуствует дата, к тому же, мы собирали эту информацию вчера, следовательно, нужно указать прошлую дату.
Для этого нужно импортировать стандартную библиотеку datetime (import datetime) и используем метод .apply() и лямбда-функцию, которая будет применяться к каждому объекту столбца.
ofz_df.last_deal_in = pd.to_datetime(ofz_df.last_deal_in)
ofz_df.last_deal_in = ofz_df.last_deal_in.apply(lambda x: x - datetime.timedelta(days=1))
Наконец, последняя задачка - автоматизировать подсчет времени до момента погашения облигации (столбец term). Если мы просто вычтем текущую дату из даты погашения облигации, то мы получим разницу в днях.
ofz_df['term'] = ofz_df['maturity'].apply(lambda x: x - pd.Timestamp(datetime.date.today()))
Чтобы пересчитать эту разницу в годах, придется подгрузить еще одну библиотеку - NumPy.
import numpy as np
ofz_df['term'] = np.round(ofz_df['term'] / np.timedelta64(1, 'Y'), 1)
В этой строке мы сразу округлим значения столбца до десятых с помощью функции np.round(). В функцию np.timedelta64() первым аргументом мы передаем временную разницу (1) и интервал - 'Y' (год).