"Внутренний мир" процессоров микроконтроллеров я кратко уже рассматривал ранее а паре статей. И рассматривал, в том числе, тему синхронизации работы узлов процессора, что вносит коррективы в построение процессора.
И вот в комментариях к третьей части возникла довольно интересная дискуссия на тему схем тактирования. Если честно, изначально я не планировал сильно углубляться в этот вопрос, целью была полнота общей картины устройства и работы микроконтроллеров. Но раз вопрос вызвал интерес, давайте поговорим немного подробнее.
Давайте подробнее посмотрим на такты, циклы, конвейеры, доступ к памяти, задержки, дополнительные циклы. Но нужно отметить, что необходимо различать внешние сигналы тактирования и внутренние. И для внутренних мы можем или полагаться на описание в документации, если оно есть, или строить какие то предположения, но уже без полной уверенности.
Ссылки на предыдущие статьи, которые сегодня могут быть вам полезны
"Микроконтроллеры для начинающих. Часть 2. Процессор микроконтроллера"
"Микроконтроллеры для начинающих. Часть 3. Процессор микроконтроллера. Тактирование и синхронизация"
Многофазное тактирование
Показанная в третьей статье цикла схема многофазного тактирования не была мной придумана. Именно так это работает в 8-битных микроконтроллерах PIC.
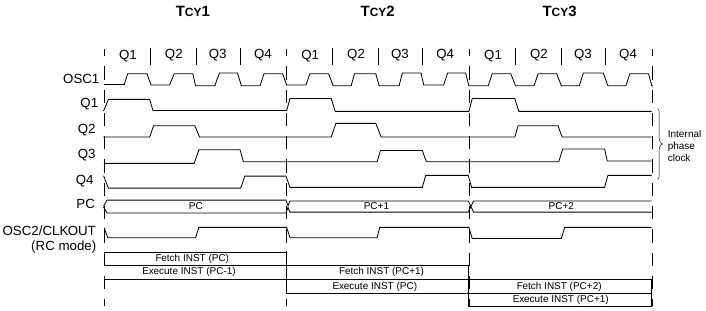
Этим микроконтроллеры, конечно, разработаны не сегодня, и даже не вчера. Но такими уж устаревшими они все таки не являются. И именно из-за того, что машинный цикл в этих микроконтроллерах состоит из 4 тактов, в документации постоянно встречается Fosc/4. Эта частота подается на все прочие узлы микроконтроллера (таймеры, АЦП, ШИМ, и т.д.). То есть, собственно процессор работает на частоте генератора, а вот остальные блоки на частоте в 4 раза меньшей.
Но самое главное не это. Обратите внимание, что не смотря на заявление, что большинство команд выполняется за один машинный цикл, фактически, любая команда выполняется минимум за два цикла! Просто нужно еще учитывать выборку и декодирование команды. А вот это почему то в расчет не принимается.
Полное время выполнения команды и основные этапы
Как я уже писал в третьей статье цикла, выполнение команды состоит из следующих основных этапов:
- Выборка команды из памяти программ
- Декодирование команды
- Выборка операндов из памяти данных
- Выполнение операции
- Сохранение результата
Безусловно, не всегда требуются все этапы. Так операнды могут уже находиться в регистрах процессора, или вообще не требоваться команде. Зачастую несколько этапов можно объединить. Так выборку команды можно объединить с декодированием, а выполнение операции с сохранением результата.
Выше я уже показал пример для PIC, а вот примеры для AVR ми STM8
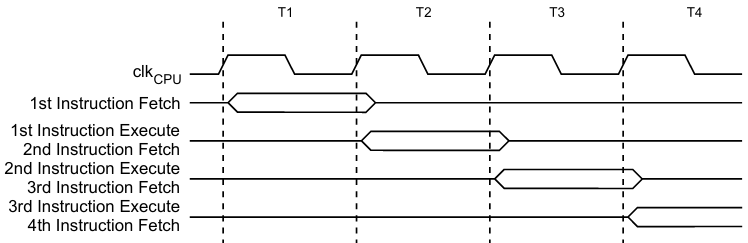
Здесь F это выборка команды, D декодирование, E выполнение.
То есть, производители микроконтроллеров все таки выделяют отдельные этапы выполнения команды, но предпочитают их не упоминать при описании быстродействия.
Тут нет злого умысла! Просто учитывается влияние конвейера. Но о конвейере мы поговорим чуть позже.
Кстати, время выполнения, не полное, хотя так его так пытаются назвать, для AVR определяется так
Повторюсь, здесь не учитывается цикл выборки и декодирования. Но эта иллюстрация показывает один очень интересный момент.
Тактирование и синхронизация по двух фронтам
В комментариях этот подход, и справедливо, называли более современным. Но вот в пример приводили AVR, иллюстрацию для которого я привел чуть выше. На первый взгляд, тут действительно синхронизация по обоим фронтам тактового сигнала. Но присмотритесь внимательнее.
Фаза "Register operands fetch" действительно начинается по нарастающему фронту тактового сигнала в периоде T1. Но вот про фазу "ALU operation execute" такого уже нельзя сказать. Она начинается до спадающего фронта тактового сигнала. А фазу "Result write back" вообще нельзя привязать к какому либо фронту тактового сигнала. Она не начинается, а заканчивается по нарастающему фронту тактового сигнала уже в периоде Т2.
Кстати, обратите внимание, что в документации на AVR говорится, что тактовая частота не делится внутри микроконтроллера. То есть, машинный цикл равен одному периоду тактовой частоты (частоты генератора). Но это отнюдь не означает, что внутри AVR не используется многофазная синхронизация. Я уже говорил, что может использоваться, например, умножение частоты.
Так что, с синхронизацией по двум фронтам все действительно плохо? Вовсе нет. Просто пример выбрали неудачный. А раз так, то давайте разбираться подробнее.
Интерфейс памяти
Выполнение любой команды начинается с ее выборки из памяти. Из памяти, в конечном итоге, получают большинство операндов. В память записывают результат операции. Поэтому любой процессор должен уметь работать с памятью.
Сразу оговорюсь, что я буду рассматривать интерфейс памяти некоего абстрактного процессора. Причем без каких либо схем и механизмов диспетчеризации (трансляция адресов, виртуализация, внешняя/внутренняя, отображение и т.д.). Так же, я не буду рассматривать формирование служебных сигналов.
Это, скажем так, самый общий случай. Очень упрощенный. Пока нам не важно, какая именно память (программ или данных). Давайте рассмотрим основные узлы этой функциональной схемы.
Полный адрес памяти, на этой иллюстрации, состоит из адреса страницы и адреса внутри страницы. Нет, это не PIC, это общий случай. Для PIC адрес страницы (адрес банка) может быть представлен, например, регистром PCLATH или BSR. Для AVR это может быть один из регистров RAMPx. Для STM8 это старший байт полного адреса памяти. Страницы памяти могут быть представлены неявно, просто в виде сигналов CS для выбора конкретной микросхемы памяти. Суть при этом остается неизменной.
Адрес страницы, в данном примере, хранится в регистре PAGE_REG. А адрес ячейки внутри страницы в регистре-защелке ADDR_LAT. Запись информации в эти регистры, а значит, выдача адреса на подшину адреса памяти, осуществляется по нарастающему фронту сигнала синхронизации sync.
Данные, записываемые в память или считываемые из нее, хранятся в регистре-защелке DATA_LAT. Запись в этот регистр осуществляется по спадающему фронту сигнала синхронизации. Для упрощения, не будем рассматривать ситуации чтения и записи по отдельности, с точки зрения синхронизации. Просто примем, что при записи в память, по спадающему фронту sync, данные будут записаны в DATA_LAT и выставлены на подшину данных памяти. А при чтении, выставленные памятью данные будут записаны в DATA_LAT по спадающему фронту sync.
На этой же иллюстрации приведен и пример временной диаграммы. Сигнал синхронизации подается и в блок памяти, но как он там используется не входит в наше рассмотрение.
Помимо общего представления об интерфейсе памяти эта иллюстрация показывает и ту самую синхронизацию по обоим фронтам. У нас цикл обращения к памяти тактируется двумя фронтами одного сигнала, и занимает ровно один период тактового сигнала.
А теперь давайте перейдем к рассмотрению особенностей интерфейсов памяти программ и данных.
Интерфейс памяти программ
В большинстве случаев, из памяти программ за одно обращение считывается больше одного байта данных. И это весьма важное отличие от памяти данных.
Для чего это требуется? Длина кода команды почти всегда больше одного байта. И для ускорения работы процессора имеет смысл считывать всю команду за одно обращение к памяти, а не по частям. Кроме того, весьма целесообразно, для быстрых процессоров особенно, считывать более одной команды. То есть, организовать конвейер команд, или кэш-память.
Как именно будет реализован конвейер нам сейчас не важно. Это может быть простой линейный буфер, или кольцевой буфер. Так же, не важно, каким будет объем этого буфера или сколько команд в него помещается.
Адрес в памяти программ хранится в регистре PC. Для упрощения я не буду рассматривать отдельно страницы памяти, так это уже показано выше. Но нам придется учитывать тот факт, что регистр PC не является статичным. Его содержимое не просто увеличивается при выборке очередной команды, но может быть полностью перезаписано при выполнении команд перехода.
Но переходы могут быть и относительными, а значит нам потребуется как то выполнять арифметические операции. Использовать для этого АЛУ процессора не обязательно, нам достаточно просто использовать отдельный сумматор.
Вот так, примерно и упрощенно, может выглядеть интерфейс памяти программ. Если присмотреться внимательнее, то станет видно, что в его основе лежит рассмотренный ранее обобщенный интерфейс памяти. Но есть и отличия.
Регистр PC, как я уже говорил, хранит адрес очередной команды (или выполняющейся). Как это не печально, но мы не можем его использовать для адресации памяти напрямую. По одной простой причине - конвейер, который представлен на иллюстрации буфером Buf. В нем уже содержатся считанные ранее команды, поэтому при переходе к следующей команде нам нужно только дополнить его, а не перезаписывать полностью.
Я не стал показывать логику управления конвейером, для нас это не важно. Но именно эта логика управляет преобразованием содержимого регистра PC в содержимое регистра-защелки ADDR_LAT.
Сумматор SUM используется для формирования адреса следующей команды при выполнении команд относительных переходов. На один вход этого сумматора подается содержимое регистра PC, а на другой смещение ofs, получаемое либо от АЛУ, либо от дешифратора команд. Выход сумматора, через мультиплексор MUX, поступает обратно в регистр PC.
Мультиплексор позволяет обойтись без использования сумматора при выполнении команд абсолютных переходов. При этом в регистр PC записывается полный адрес команды addr. Как видно, у нас одна подшина addr/ofs используется и для передачи адреса, и для передачи смещения относительно текущего адреса.
Если выполняется обычная команда, а не команда перехода, то регистр PC просто увеличивается сигналом +1, причем для нас не важно, как именно он формируется. Зато понятно, что в качестве PC может использоваться двоичный счетчик соответствующей разрядности с входами для записи нового значения.
Буфер Buf, в который считывается сразу несколько байт из памяти программ, может иметь объем M байт, если конвейер отсутствует. Или К*М байт, если организован конвейер длиной К команд. Для простоты будем считать, что у нас все команды имеют одинаковую длину. Через подшину cmd содержимое буфера доступно для остальных узлов процессора.
Осталось рассмотреть синхронизацию работы интерфейса памяти сигналом sync. Здесь нет принципиальных отличий от рассмотренного ранее. То есть, по нарастающему фронту у нас на подшину адреса выставляется адрес первого считываемого байта, а по спадающему в буфер записывается выданная памятью по подшине данных информация.
Но отличия все таки есть. И они представлены модулем задержки delay. Для чего он нужен? Дело в том, что сигнал через сумматор и мультиплексор распространяется не мгновенно. Точно так же, увеличение регистра PC требует некоторого времени. Поэтому сигнал sync на PC подается напрямую, а вот на регистр-защелку ADDR_LAT с задержкой обеспечивающей гарантированное завершение обновления PC.
При этом у нас по прежнему адрес формируется по нарастающему фронту sync, но на подшине адреса памяти он появляется с некоторой задержкой. Таким образом, у нас по прежнему цикл памяти программ синхронизируется по обоим фронтам синхросигнала, но мы смогли выделить дополнительный, внутренний, сигнал обеспечивший многофазную синхронизацию внутренней логики. Это один из возможных способов формирования внутренних сигналов синхронизации, без деления или умножения тактовой частоты.
Процессор выставляет на addr/ofs новый адрес или смещение, для команд перехода, или выдает сигнал "+1", для остальных команд. По нарастающему фронту сигнала sync начинается изменение содержимого PC. d_sync это задержанный на максимальное время обновления PC сигнал sync, точнее, задержка выполняется только для его нарастающего фронта. По нарастающему фронту d_sync содержимое PC копируется (через логику управления конвейером, если она есть) в ADDR_LAT и адрес появляется на подшине адреса памяти.
Модуль памяти выполняет свою часть работы и выдает на подшину данных памяти содержимое нескольких (количество определяется реализацией) байт памяти. По спадающему фронту sync эта информация записывает с буфер (конвейер) Buf. После этого код команды становится доступен на подшине cmd для дешифрации.
Теперь посмотрим на разрядность шин, показанных на иллюстрации. N это разрядность шины адреса, определяется доступным объемом памяти программ. М это разрядность шины данных. Например для PIC это может быть 12, 14, или 16 (два байта) бит. Для STM8 это 32 бита (4 байта). С это ширина шины кода команды для дешифрации. Определяется реализацией.
Объем буфера Buf может быть разный. Например, для STM8 он равен 96 бит (12 байт). Еще раз подчеркну, что логика работы буфера (конвейера) я вообще никак не рассматриваю.
Интерфейс памяти данных
Работа с памятью данных во многом похожа на работу с памятью программ. Но за одно обращение, обычно, считывается/записывается только один байт. Кроме того, тут уже не будет регистра адреса, аналогичного PC. Адрес байта данных полностью определяется процессором.
Эта функциональная схема проще предыдущей только за счет того, что не стало регистра PC. Сумматор обеспечивает возможность режима адресации "индекс+смещение" (база+смещение). Мультиплексор исключает сумматор из работы если учет смещения не требуется. Задержка sync нужна по той же причине, что и в интерфейсе памяти программ, для работы сумматора требуется некоторое время.
Обратите внимание, что разрядность шины данных памяти я уже явно обозначил равной 8 битам. Поскольку интерфейс памяти данных, за исключением указанных отличий, похож на интерфейс памяти программ, я не буду приводить временную диаграмму его работы.
Дешифрация (декодирование) команд
На первый взгляд, здесь нет ничего сложного. Просто подаем на дешифратор, скорее всего выполненный в виде ПЗУ, код команды и получаем на выходе все необходимые сигналы и состояния. Однако, на практике, код команды может занимать переменное число бит, пересекать границы байт, или вообще быть "размазанным" по нескольким байтам.
Кроме того, в декодирование команды входит и определение режимов адресации, и количества операндов. А иногда и выборка операндов из памяти. В AVR выборка операнда из памяти выполняется после декодирования, как я показывал на иллюстрации из документации. А вот в STM8 и вычисление адреса, и выборка операнда выполняются на стадии декодирования (Decoding and addressing stage).
Так как мы рассматриваем абстрактный процессор, выделим выборку операндов в отдельный этап выполнения команды. А раз так, то собственно декодирования становится достаточно простым. Но для него требуется некоторое время. Подробности декодирования нам не важны, статья не об этом.
Выборка операндов из памяти
Выборка операндов не сводится к работе интерфейсов памяти. Необходимо еще и формирование адресов операндов, для которого недостаточно сумматора в интерфейсе. Адрес операнда может содержаться в коде команды, находиться в индексном регистре, включать в себя смещение. Да и смещение, если оно используется, может быть как в коде команды, так и в одном из регистров. То есть, требуется специальный блок адресации, который может быть довольно сложным.
В нашем случае мы разместили часть схемы вычисления адреса в интерфейсе памяти. А это существенно упрощает блок адресации. В общем случае, для вычисления адресов может использоваться АЛУ процессора, но обойдемся без этого.
Кроме того, в нашем абстрактном процессоре для любой команды будет доступно не более двух операндов, причем как минимум один из них должен быть в регистре, а не в памяти. А еще, у нашего процессора не будет режимов адресации с автоинкрементом и автодекрементом.
Я не стал показывать сигнал синхронизации sync. Как он используется интерфейсами памяти уже показано ранее. Этот сигнал поступает в блок регистров общего назначения (РОН), но как он там используется я расскажу чуть позже.
OPCODE это код команды, возможно уже без кода операции, так как нам в данном случае важна только информация об адресе и режимах адресации операндов.
Зачем я показал интерфейс памяти программ? По той причине, что существует возможность чтения константы из памяти программ и использование ее как данных. Примером могут служить команда LPM в AVR, команда LDF в STM8 если указан адрес в пространстве программ, команда TBLRD в PIC.
Остается рассмотреть, зачем нужен регистр-защелка DATA_LAT. Все очень просто. После выборки операндов мы можем переходить к выполнению заданной командой операции, но нам нужно при этом и записать результат операции на его место. А если результат должен помещаться в память данных? Что бы освободить интерфейс памяти данных для записи результата наш блок адресации и помещает операнд из памяти в этот временный регистр. А мы получаем возможность записи результата одновременно с выполнение операции.
На иллюстрации я показал работу блока адресации при чтении данных. Если же требуется запись данных в память, как результата операции, то данные подаются непосредственно на шину data интерфейса памяти данных. Я не стал показывать это на иллюстрации.
Блок операций
Здесь и происходит этап собственно выполнения заданной командой операции. Можно сказать, что это АЛУ, но это будет ошибкой. Дело в том, что не каждая операция может быть выполнена за один шаг, просто с использованием АЛУ. Например команды умножения и деления, если они вообще реализованы, обычно выполняются итерационно. Как именно это реализуется, нам не важно. Это может быть некий конечный автомат или блок микропрограммного управления.
Для нашего абстрактного процессора будем считать, что итерационное выполнение операций не требуется. Что бы не усложнять излишне и без того не простую статью. Поэтому наш блок операций получается очень простой, практически это АЛУ
Теперь мы можем попытаться собрать все воедино.
Собираем все вместе
Давайте попробуем собрать из этиз блоков собственно наш абстрактный процессор. Но пока без схемы синхронизации.
В общем то, все просто. Примерно так, как я рассматривал это во второй, третьей, и четвертой статьях цикла. Но теперь мы расмматриваем вопрог немного подробнее. Нам остается реализовать синронную работу всех узлов процессора.
Что мы можем сразу увидеть? У нас два независимых модуля памяти. А значит, мы можем одновременно работать с ними. Можно предположить, что декодер команд должен работать после выборки команды через интерфейс памяти программ, но это никак не влияет на работу с памятью данных. Вероятно, потребуется некоторое усложнение декодера, например, введением регистров-защелок, что бы декодирование очередной команды не влияло на уже выполняющуюся.
Блок адресации может работать только после декодирования команды, так как ему требуется информация о режимах адресации, которая формируется декодером.
Последним у нас будет работать блок операций, причем он будет использовать и блок адресации, а, возможно, и интерфейс памяти данных. Давайте попробуем собрать это в некую последовательностную диаграмму.
Не правда ли, очень похоже на то, что приводят в своей документации производители процессоров? Но почему у нас появилось пустое место во второй строке? Дело в том, что у нас работа блока операций (выполнение и сохранение) тоже использует блок адресации, а значит, мы не может одновременно выбирать операнд и сохранять результат.
Мы можем объединить в один этап выборку команды и ее декодирование (как в AVR), а выполнение и схранения наоборот разбить на два этапа (как в PIC). Это даст нам иную последовательностную диаграмму. Но в целом радикально картина не изменится.
Теперь попробуем ввести синхронизацию. Раз у нас получилось 4 основных этапа выполнения команды, то разумно предположить, что потребуется 4-фазная синхронизация, как это и сделано в PIC. Но мы можем и несколько оптимизировать процесс. Причем воспользуемся маркетинговых ходом производителей, которые не учитывают выборку и декодирование команды.
Давайте выделим две группы функций. Первая - выборка и декодирование команды. Вторая - выборка операнда и выполнение (включая сохранение). Добавим в нашу поледовательностную диаграмму сигнал синхронизации.
Получилось? Да, вполне. Нам пришлось немного сдвинуть выборку команды, теперь она выолняется только после декодирования предыдущей. Зато не стало пустого места, пропуска такта. Здесь Tn это один период тактовой частоты.
Но давайте посмотрим внимательнее, нам ведь не хватает только одного тактового сигнала. В интерфесах памяти мы выкрутились добавив формирование задержанного фронта сигнала синхронизации, что бы дать время отработать сумматору и регистру PC. С декодированием команды особых сложностей нет, нужно просто учесть, что на это требуется время. А вот с выборкой операнда и выполнение все гораздо хуже.
Так для выборки операнда нам нужно сформировать его адрес в блоке адресации, а затем получить данные через интерфейс памяти. После этого, мы должны охранить данные в блоке регистров или регистре-защелке. Формирование адреса требует времени. Да и запись данных тоже.
Фактически, для этапа "выборка операнда" нам надо в два раза больше тактов, минимум. Мы можем пойти по пути Microchip, которая в своих микроконтроллерах спользовала внутреннее деление тактовой частоты. Этот путь я показал в третьей статье цикла и в начале данной статьи. Но что делать, если мы хотим работать на частоте тактового генератора, как это декларирует Atmel?
Например, мы можем использовать тот же подход, что я показал при рассмотрении интерфейсов памяти. То есть, использовать задержки.
Я показал, как получаются четыре фронта сигнала, четыре внутренних сигнала синхронизации, из одного внешнего тактового сигнала. Причем обратите внимание, что величины задержек разные, а значит и временные интервалы полученных таким образом синхросигналов будут разными.
Теоретически, это вполне рабочий способ. Причем так можно сформировать множество внутренних синхросигналов. Величины задержек выбирают исходя из максимальной частоты тактового сигнала, на которой должна работать схема. Однако, у данного подхода есть весьма серьезный недостаток.
Нет, я говорю не сложности построения такой схемы. Задержки могут формироваться цифровым способом, например, счетчиком с комбинационной логикой.
Если такой процессор будет работать на более низкой тактовой частоте, то часть периода тактового сигнала не будет использоваться для полезной работы. Но самое плохое не это. Длительность формируемых таким процессором сигналов может не зависеть от тактовой частоты, так как определяется временем соответствующей задержки. А это допустимо не всегда.
Поэтому лучше использовать умножение частоты для формирования внутренней схемы многофазной синронизации. И так действительно делают. Внутри микропроцессоров и микроконтроллеров. При этом мы получаем ту самую многофазную, но только внутри микросхемы, систему синхронизации. А внешне это выглядит так, как пишет Atmel, то есть работа на частоте тактового генератора.
Конвейер и последовательное выполнение команд
А теперь давайте посмотрим, что будет, если нашему прошессору попадется команда работающая с данными расположенными в памяти программ.
Я говорю вот об этом фрагменте нашей последовательностной диаграммы
В этом случае у нас эти этапы не могут быть выполнены параллельно, так как и выборка команды, и выборка операнда, будут обращаться к интерфейсу памяти программ. Возникает коллизия. В таком случае нам придется задержать выборку следующей команды, так как приоритет имеет выборка операнда для уже выполняющейся команды. Возникает пропуск цикла, а производительность процессора падает.
Другим примером являются команды условных переходов, причем это, пожалуй, наиболее известный пример коллизий и сбоев конвейера. Дело в том, что при выполнении команды условного перехода не известно, какую команду выбирать из памяти следующей, так как не известно, будет ли выполнен переход. Может потребоваться считывать или следующую команду, или команду по адресу перехода.
В современных производительных процессорах используются различные методы ограничивающие число сбоев конвейера. Но в 8-битных микроконтроллерах в большинстве случаев используется пропуск тактов.
Кроме того, даже такое вот параллельное выполнение и выборки следующей команды (простейший конвейер), как мы рассматривали, накладывает свой отпечаток на выполнение команд в некоторых условиях.
Например, при выполнении команды sleep в микроконтроллерах PIC (перевод микроконтроллера в режим сна) следующая команда, перед переходом в сон, оказывается уже выбранной. И когда микроконтроллер просыпается, то это предварительно выбранная команда выполняется. Причем даже в том случае, если процессор пробуждается в результате прерывания. То есть, сначала выполнится эта ранее выбранная команда, и только потом управление будет передано в обработчик прерываний. Если такое недопустимо, то после sleep производитель рекомендует вставлять команду nop.
А если выборка операнда не требуется, так как он уже в регистре? В таком случае поведение зависит от реализации процессора. В нашем абстрактном процессоре у нас окажется бесполезно потраченной половина такта, в котором и должен был выбираться операнд.
Бывает и другая ситуация, когда использование косвенной адресации приводит в вставке дополнительного такта, что приводит к увеличению количества тактов исполнения команды. Такое поведение указывается в документации, которую нужно читать внимательно.
Особенность STM8
На этом вопросе я остановлюсь кратко, так как это тема отдельной статьи. Помните, что из памяти программ считывание идет порциями по 4 байта? И длина кода команды может быть от 1 до 4 байт. Кажется, все прекрасно, но как всегда все портят детали... Точнее, байт префикса, о котором я писал в статье "Микроконтроллеры для начинающих. Часть 16. Команды пересылки данных STM8". Эти префиксы предшествуют команде и увеличивают ее длину.
А это приводит к тому, что выборка команды займет не один, а два цикла. Ситуацию спасает то, что буфер команд вмещает 12 байт. При этом выборка очередной команды задержится.
Кроме того, поскольку формирование адресов и выборка операндов относятся к этапу декодирования, этот этап может занимать разное число циклов. Кроме того, и этап выполнения команды может занимать разное количество циклов.
А это приводит к тому, что реальное число циклов выполнения команды не является постоянным, а зависит от того, какие команды ей предшествуют. И сама команда оказывает влияние на длительность выполнения последующих команд.
Кроме того, в STM8 возможно выполнение программы из памяти данных, что еще больше усложняет ситуацию. Так как выборка из памяти команд идет по одному байту, а не по 4. В результате, возможно вот такое
Или такое
Заключение
Я немного подробнее рассмотрел вопросы работы отдельных блоков процессора, причем с точки синхронизации их совместной работы. Но все равно, это чрезвычайно упрощенное рассмотрение.
Я попытался показать, что внешние сигналы синхронизации могут радикально отличаться (и отличаются) от того, как синхронизация устроена внутри микроконтроллера. И что многофазная синхронизация по прежнему актуальна, просто спряталась внутри.
При этом мы можем лишь строить предположения о том, как на самом деле все устроено внутри, просто производители редко описывают это в документации.
Настолько глубоко погружаться в работу процессоров нужно довольно редко. А новичкам, на которых и ориентирован цикл статей, вообще почти никогда. По этой причине я и ограничился лишь кратким описанием в статьях 2, 3, и 4, цикла. Что бы было понимание, но без излишнего усложнения.
Однако, поскольку вопрос вызвал интерес и обсуждение, решил уделить ему чуть больше внимания.