Облако является отличным местом для резервного копирования ваших данных для аварийного восстановления. Давайте рассмотрим, как использовать AWS для DR и некоторые архитектуры, которые вы можете рассмотреть.
Обслуживание центров обработки данных физического аварийного восстановления (DR)с каждым годом становится все более дорогостоящим. Перемещая центр обработки данных DR в облако Amazon Web Services (AWS), вы обеспечиваете более быстрое аварийное восстановление и большую отказоустойчивость без затрат на второй физический центр обработки данных. В этой статье мы обсудим, как использовать AWS для управления аварийным восстановлением в облаке. Мы дадим краткий обзор того, как работает AWS disaster recovery, преимущества использования AWS DR, обзор архитектур DR и пример клиента.
Использование AWS Disaster Recovery для закрытия вашего центра обработки данных DR отSoftNAS, Inc.
Прежде чем мы начнем, есть четыре термина, с которыми вы должны быть знакомы при обсуждении аварийного восстановления:
- Непрерывность бизнеса: обеспечение того, чтобы критически важные бизнес-функции вашей организации продолжали функционировать или довольно быстро восстанавливались после серьезного инцидента.
- Аварийное восстановление: аварийное восстановление - это все о подготовке и восстановлении после катастрофы, поэтому любое событие, которое оказывает негативное влияние на ваш бизнес; такие вещи, как сбои оборудования; сбои программного обеспечения; отключения электроэнергии; физические повреждения вашего здания, такие как пожар, наводнение и ураганы или даже человеческая ошибка. Аварийное восстановление-это все о планировании для этих инцидентов.
- Цели точки восстановления (RPO): RPO-это в основном приемлемый объем потери данных, измеренный во времени. Если катастрофа произошла в 12: 00 вечера и ваш RPO составляет один час, ваша система должна восстановить все данные, которые были в системе до 11:00 утра. Ваша потеря данных будет охватывать только с 11: 00 утра до 12:00 вечера.
- Цель времени восстановления (RTO): RTO-это время, которое требуется после сбоя для восстановления ваших бизнес-процессов до их согласованных уровней обслуживания. Если ваша катастрофа происходит в 12 часов дня, а ваш RTO составляет восемь часов, вы должны быть снова запущены не позднее 20: 00.
Сохраните Ваш основной центр обработки данных, но перенесите аварийное восстановление в AWS
Мы не говорим, что вам нужно закрыть все ваши центры обработки данных и перенести их в AWS. Вы можете сохранить свой основной центр обработки данных, но закрыть свой центр обработки данных DR и перенести эти рабочие нагрузки в AWS.
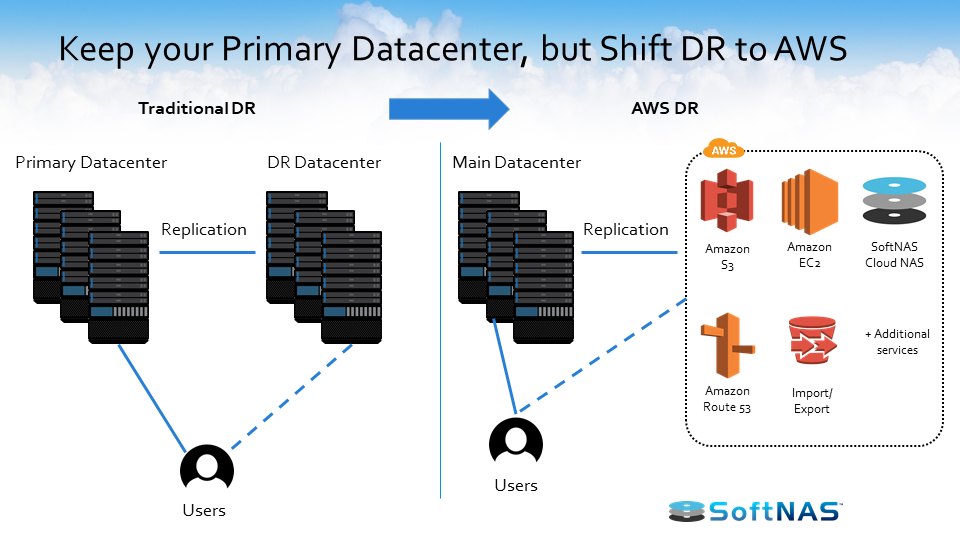
На изображении выше, у нас есть наша традиционная архитектура DR слева. У вас есть ваш основной центр обработки данных, а затем у вас есть ваш DR datacenter. С центром обработки данных DR существует репликация между основным и центром обработки данных DR. Вы можете восстановиться, как только произойдет сбой в основном центре обработки данных. Таким образом, ваши пользователи по-прежнему могут работать без слишком большого воздействия.
При использовании традиционного аварийного восстановления у вас есть инфраструктура, необходимая для поддержки повторяющейся среды. Физическое расположение, питание, охлаждение, безопасность для обеспечения того, чтобы это место было защищено, обеспечение хранения и достаточной емкости сервера для запуска всех отсутствующих критических служб, включая аутентификацию пользователей, мониторинг DNS и оповещение.
Справа, у нас есть аварийное восстановление с управляемым на AWS. Вы видите главный центр обработки данных, но вы можете настроить репликацию в облако AWS, используя несколько сервисов, включая Amazon S3, Route 53, Amazon EC2 и SoftNAS Cloud NAS .
Вы получите все преимущества вашего текущего центра обработки данных DR, но без необходимости поддерживать какое-либо дополнительное оборудование или беспокоиться о подготовке вашего текущего центра обработки данных.
Давайте сравним физический Dr datacenter и AWS Disaster Recovery. С вашим центром обработки данных DR есть высокая стоимость для его создания и обслуживания. Вы несете ответственность за хранение, питание, сеть, Интернет и многое другое. Существует много капитальных затрат, связанных с обслуживанием центра обработки данных DR.
Средства хранения, резервного копирования и извлечения данных стоят дорого. Часто требуется несколько недель, чтобы добавить больше емкости, потому что планирование, закупки и развертывание просто занимают время с физическими центрами обработки данных. Это также сложно проверить ваши планы DR. Тестирование для DR on-site занимает много времени и требует много усилий, чтобы убедиться, что он работает правильно.
С правой стороны, у нас есть преимущества использования AWS для DR.там не так много капитальных затрат при использовании AWS. Прелесть использования AWS для управления DR заключается в том, что все это по требованию, поэтому вы будете платить только за то, что используете.
Существует также согласованный опыт работы в различных средах AWS. AWS просто очень прочный и высокодоступный. Существует много защиты в том, чтобы убедиться, что ваш AWS DR будет запущен и запущен. Вы также можете автоматизировать свое восстановление. Наконец, вы можете даже настроить аварийное восстановление для каждого приложения или подразделения. Таким образом, различные бизнес-единицы в рамках организации могут иметь различные цели и задачи восстановления.
Управление инфраструктурой аварийного восстановления.
Прелесть использования AWS для управления вашим DR заключается в том, что вы действительно отвечаете только за ваше хранилище моментальных снимков. AWS обрабатывает маршрутизаторы, брандмауэры, операционные системы и многое другое. AWS просто снимает все это с ваших рук, поэтому вы можете сосредоточиться на более важных задачах и проектах.
Как AWS disaster recovery отражает ваш центр обработки данных DR? На рисунке выше показаны традиционные сервисы DR и сервисы AWS. Например: с DNS AWS имеет маршрут 53; для балансировщиков нагрузки AWS имеет эластичную балансировку нагрузки; веб-серверы могут быть EC2 или автоматическое масштабирование. Центры обработки данных управляются зонами доступности.
Поскольку все находится на AWS, стандарты безопасности предприятия, безусловно, соблюдаются. AWS всегда в курсе сертификации, будь то ISO, HIPAA, ITAR или другие стандарты соответствия.
Существует также аспект физической безопасности. Центры обработки данных AWS очень безопасны, расположены в неприметных помещениях, и физический доступ строго контролируется. Они регистрируют весь физический доступ к своим центрам обработки данных.С сетью оборудования и программного обеспечения, они имеют систематическое управление изменениями. Обновления происходят поэтапно и они делают безопасный вывод хранилища из эксплуатации. Существует также автоматизированный мониторинг, самоаудит и расширенная защита сети.
Архитектуры аварийного восстановления AWS
Давайте рассмотрим некоторые архитектуры DR и сценарии для AWS. Существует четыре основные архитектуры DR:
- Резервное копирование и восстановление
- сигнальная лампа
- горячий резерв
- Мульти-сайт
Прежде чем мы обсудим архитектуры, давайте рассмотрим некоторые сервисы AWS, связанные с DR.для резервного копирования и восстановления вы не используете слишком много основных сервисов AWS. Вы собираетесь использовать Amazon S3, Glacier, SoftNAS Cloud NAS (для репликации), Route 53 и VPN.
При переходе на Pilot Light вы добавите Тома CloudFormation, EC2, EBS, Amazon VPC и DirectConnect.
Для горячего режима ожидания вы добавляете автоматическое масштабирование, эластичную балансировку нагрузки и настройку также нескольких прямых подключений. Для мульти-сайта существует целый ряд сервисов AWS, которые можно добавить.
Архитектура резервного копирования и восстановления
Способ резервного копирования и восстановления данных показан на рисунке ниже. Слева находится локальный центр обработки данных, а справа-инфраструктура AWS DR.
Слева у вас есть центр обработки данных, использующий файловый протокол iSCSI, а затем у вас есть виртуальный NAS поверх этого управляющего хранилища файлов. С AWS DR вы можете использовать комбинацию SoftNAS Cloud NAS , Amazon S3, EC2 и EBS для работы с архитектурой резервного копирования и управления ею.
В традиционных средах резервное копирование данных выполняется в центр обработки данных DR. Это вне сайта, так что если что-то не удается, это займет много времени, чтобы восстановить вашу систему, потому что вы должны вытащить их, а затем вытащить резервные данные из них.
Amazon S3 и Glacier действительно хороши для этого. Использование сервиса SoftNAS Cloud NAS позволяет использовать моментальные снимки локальных данных и копировать их в хранилище S3 для резервного копирования. Преимуществом этого является то, что вы также можете настроить свои тома данных моментальных снимков, чтобы дать вам очень прочную резервную копию.
Это довольно рентабельно, так как вы не платите за это много денег. В случае аварии вы получите резервные копии из S3 и запустите необходимые инфраструктуры. Таким образом, это экземпляры EC2 с подготовленными массами, балансировкой нагрузки и т. д. Вы восстанавливаете систему из резервной копии.
С архитектурой резервного копирования и восстановления, это немного больше времени занимает. Это не мгновенно, но есть работа вокруг для этого.
С помощью SoftNAS Cloud NAS можно настроить репликацию с помощью SnapReplicate. Это делает ваши данные мгновенно доступными вместо того, чтобы ждать его загрузки и резервного копирования. Теперь все это мгновенно доступно для вас. Так что ваш RTO и ваш RPO идут от часов или дней в минуты или только один или два часа.
Пилотная Светлая Архитектура
Переходя к архитектуре Pilot Light, это сценарий, в котором минимальная версия архитектуры основного центра обработки данных всегда выполняется в облаке.
Это довольно похоже на сценарий резервного копирования и восстановления. С помощью AWS вы можете поддерживать мощность пилотного фонаря, настраивая и запуская наиболее важные основные элементы в своей системе в AWS. Когда придет время восстановления, вы можете быстро подготовить полномасштабную производственную среду вокруг критического ядра.
Чтобы подготовиться к использованию архитектуры Pilot Light, вы реплицируете все свои критические данные в AWS. Вы готовите все необходимые ресурсы для вашего автоматического запуска. В том числе AMI, настройки сети, балансировка нагрузки. Мы даже рекомендуем зарезервировать несколько экземпляров тоже.
В случае аварии вы автоматически вызываете ресурсы вокруг реплицируемого набора основных данных. Затем вы можете масштабировать систему по мере необходимости для обработки текущего производственного трафика. Опять же, одним из преимуществ AWS является возможность масштабирования выше или ниже в зависимости от текущих потребностей.
Горячая Резервная Архитектура
Переходя к архитектуре горячего резервирования, это сценарий аварийного восстановления, который является уменьшенной версией полнофункциональной среды. Он всегда работает в облаке. Таким образом, в основном теплый режим ожидания распространяется на элементы Pilot Light, и это еще больше уменьшает восстановление, потому что некоторые из ваших сервисов всегда работают в AWS – они не простаивают, и с ними нет простоя. Идентифицируя критически важные для вашего бизнеса системы, вы можете полностью дублировать их на AWS и всегда иметь их включенными.
Горячий резервный режим довольно хорошо справляется с производственными нагрузками. Чтобы подготовиться, вы снова реплицируете все свои критические данные в AWS. Вы подготавливаете все необходимые ресурсы и зарезервированные инстансы. В случае аварии вы автоматически вызываете ресурс вокруг реплицированного основного набора данных. Вы масштабируете систему по мере необходимости для обработки текущего производственного трафика.
Цель горячего режима ожидания состоит в том, чтобы заставить вас встать и работать почти мгновенно. Ваш RTO может составлять около 15 минут, а ваш RPO может варьироваться от 1 до 4 часов.
Наконец, у нас есть архитектура нескольких сайтов. Здесь ваша инфраструктура AWS DR работает параллельно с существующей структурой на месте. Вместо того, чтобы быть активным-неактивным, это будет активная-активная конфигурация. Это самая мгновенная архитектура для ваших потребностей DR. В любой момент, как только ваш локальный центр обработки данных выходит из строя, AWS будет идти вперед и забрать рабочую нагрузку почти сразу.
В принципе, вы будете работать с полной производственной нагрузкой без какого-либо снижения производительности, поэтому он немедленно заполняет всю вашу производственную нагрузку. Все, что вам нужно сделать, это просто настроить свои DNS-записи, чтобы они указывали на AWS. Ваш RTO и ваш RPO находятся в течение нескольких минут, поэтому не нужно беспокоиться о том, чтобы тратить время на перепроектирование всего.
Пример аварийного восстановления AWS для клиентов
Вот пример, показывающий, как наши клиенты используют аварийное восстановление на AWS.Клиент использует AWS для управления своими бизнес-приложениями, и они разбили их на приложения уровня 1, уровня 2 и уровня 3.
Для приложений уровня 1, которые должны быть запущены 24/7, у них есть свои экземпляры EC2 для всех служб, работающих в любое время. Их собственная инфраструктура и инфраструктура AWS сбалансированы по нагрузке и настроены для автоматической отработки отказа. Они выполняют начальную синхронизацию данных с помощью внутреннего программного обеспечения для резервного копирования или FTP. Наконец, они настроили репликацию с SoftNAS Cloud NAS для автоматической отработки отказа в считанные минуты.
С помощью приложений уровня 2 они настраивают только критические основные элементы системы – они не настраивают все. Опять же, у них есть свои экземпляры EC2, работающие только для критических служб. Они предварительно настроили свои Ami для приложений уровня 2,которые могут быть быстро подготовлены. Их облачная инфраструктура сбалансирована по нагрузке и настроена для отработки отказа AMI. Они сделали начальную синхронизацию данных с их программным обеспечением резервного копирования. Наконец, репликация была настроена с помощью SoftNAS Cloud NAS.
Для приложений уровня 3, где RPO и RTO не слишком строгие, они реплицируют все свои данные в S3 с помощью SoftNAS Cloud NAS . Агин, они сделали синхронизацию со своим программным обеспечением для резервного копирования. Они пошли вперед и заранее настроили свои масс. И тогда также их инциденты EC2 вращаются от объектов в пределах S3 к ручному процессу, но они могут попасть туда довольно быстро.
