
В этой статье я покажу вам, как создать блокнот Jupyter, который извлекает живые данные, строит интерактивный график, а затем, как развернуть его как живую панель мониторинга. Если вы хотите поделиться панелью, все, что вам нужно - это ссылка.
Получаем "живые" данные из Reddit
Для этого мы воспользуемся API, называемое pushshift. Документация прямо здесь.
import requests
url = "https://api.pushshift.io/reddit/search/comment/?q=python"
request = requests.get(url)
json_response = request.json()
Вы можете добавить множество параметров к этому запросу, пример здесь.
Для упрощения метода мы создадим функцию для обращения к API:
def get_pushshift_data(data_type, ** kwargs):
base_url = f'https://api.pushshift.io/reddit/search/{data_type}/'
payload = kwargs
request = requests. get(base_url, params= payload)
return request. json()
Используя payload и kwargs я могу добавить любой параметр в функцию:
get_pushshift_data(data_type="comment",
q="python",
after="48h",
size=1000,
sort_type="score",
sort="desc")
Проанализируем данные с помощью Plotly Express
В какой разделе слово phyton появляется чаще?:
data = get_pushshift_data(data_type="comment",
q="python",
after="48h",
size=1000,
aggs="subreddit")
Параметр aggs показывает какие разделы ( subreddit ) имели наибольшую активность в течение определенного срока, читать здесь.
Нам будет необходима навигация внутри словаря:
data = data.get("aggs").get("subreddit")
Также преобразуем список словарей в датафрейм и выведем первые десять строк:
df = pandas.DataFrame.from_records(data)[0:10]
Output:
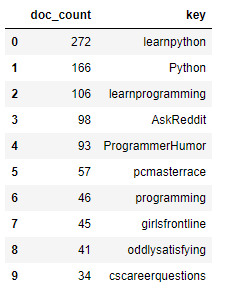
Давайте теперь построим график наших результатов с помощью библиотеки Ploty Express.
pip install plotly.express
import plotly.express as px
px.bar(df,
x="key",
y="doc_count",
title=f"Разделы с наибольшей активностью по python за последние 48 часов",
labels={"doc_count": "# comments","key": "Subreddits"},
color_discrete_sequence=["blueviolet"],
height=500,
width=800)
Output:
Каковы наиболее популярные комментарии со словом phyton?:
data = get_pushshift_data(data_type="comment", q="python", after="7d", size=10, sort_type="score", sort="desc").get("data")
df = pandas.DataFrame.from_records(data)[["author", "subreddit", "score", "body", "permalink"]]
df['body'] = df['body'].str[0:400] + "..."
df['permalink'] = "https://reddit.com" + df['permalink'].astype(str)
def make_clickable(val):
return '<a href="{}">Link</a>'.format(val,val)
df.style.format({'permalink': make_clickable})
Output: 10 популярных комментариев с phyton за последние 7 дней
Узнаем каково настроение комментариев с помощью библиотеки TextBlob.
TextBlob - это простая библиотека, которая позволяет легко понять смысл предложения. Textblob возвращает два значения: полярность настроения (-1 отрицательно; 0 нейтрально; 1 положительно) и субъективность настроения (0 объективно, 1 субъективно). Узнать больше об этой библиотеке можете здесь.
Устанавливаем библиотеку.
pip install textblob
Получаем данные с наибольшим количеством комментариев за последние 2 дня.
data = get_pushshift_data(data_type="comment",
after="2d",
size=1000,
sort_type="score",
sort="desc",
subreddit="python").get("data")
columns_of_interest = ["author", "body", "created_utc", "score", "permalink"
df = pandas.DataFrame.from_records(data)[columns_of_interest]
Пускаем в ход библиотеку TextBlob.
import textblob
df["sentiment_polarity"] = df.apply(lambda row: textblob.TextBlob(row["body"]).sentiment.polarity, axis=1)
df["sentiment_subjectivity"] = df.apply(lambda row: textblob.TextBlob(row["body"]).sentiment.subjectivity, axis=1)
df["sentiment"] = df.apply(lambda row: "positive" if row["sentiment_polarity"] >= 0 else "negative", axis=1)
df["preview"] = df["body"].str[0:50]
df["date"] = pandas.to_datetime(df['created_utc'],unit='s')
Визуализируем с помощью Plotly Express.
В этой визуализации мы можем видеть комментарии, сделанные за последние 48 часов. Мы видим, что большинство комментариев скорее положительные, но некоторые также отрицательные. Вы можете навести курсор на комментарий и прочитать предварительный просмотр. Крутая вещь в том, что если завтра вы запустите тот же сценарий, вы получите другой вывод.
Продолжение следует...