Мы уже видели, что pandas хорошо умеет обращаться с датами. Но он также хорошо умеет работать со строками! Возьмём наши данные из предыдущей части.
In [1]:
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
pd.options.display.max_rows = 7
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (15, 3)
plt.rcParams['font.family'] = 'sans-serif'
In [2]:
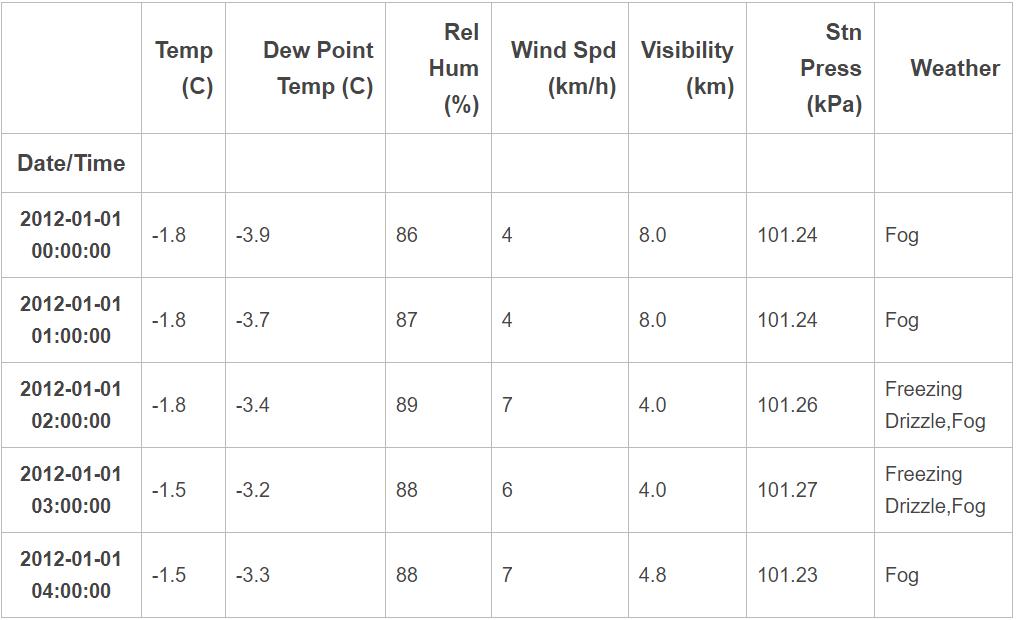
weather_2012 = pd.read_csv('data/weather_2012.csv', parse_dates=True, index_col='Date/Time')
weather_2012[:5]
Out[2]:
Операции над строками в pandas
Мы видим, что столбец 'Weather' содержит текстовое описание погоды за час. Предположим, что снежная погода в описании содержит "Snow".
pandas позволяет векторизовать операции над строками, позволяя эффективно обрабатывать столбцы. В документации есть много хороших примеров.
In [3]:
weather_description = weather_2012['Weather']
is_snowing = weather_description.str.contains('Snow')
Этот код даёт нам бинарный вектор, который не очень красиво выглядит, поэтому мы построим график.
In [4]:
is_snowing[:5]
Out[4]:
Date/Time
2012-01-01 00:00:00 False
2012-01-01 01:00:00 False
2012-01-01 02:00:00 False
2012-01-01 03:00:00 False
2012-01-01 04:00:00 False
Name: Weather, dtype: bool
In [5]:
is_snowing.plot()
Out[5]:
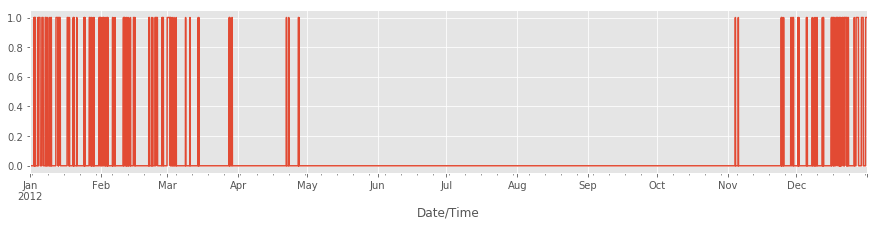
Находим снежные месяцы
Если мы хотим медианную температуру за каждый месяц, нужно использовать метод resample(), как в примере:
In [6]:
weather_2012['Temp (C)'].resample('M').median().plot(kind='bar')
Out[6]:
Внезапно, июль и август оказались самыми тёплыми.
Что касается снега, можно считать, что мы имеем дело с векторами из нулей и единиц, вместо True и False:
In [7]:
is_snowing.astype(int)[:10]
Out[7]:
Date/Time
2012-01-01 00:00:00 0
2012-01-01 01:00:00 0
2012-01-01 02:00:00 0
..
2012-01-01 07:00:00 0
2012-01-01 08:00:00 0
2012-01-01 09:00:00 0
Name: Weather, dtype: int64
а затем использовать resample, чтобы найти процент времени, когда шёл снег.
In [8]:
is_snowing.astype(int).resample('M').mean()
Out[8]:
Date/Time
2012-01-31 0.240591
2012-02-29 0.162356
2012-03-31 0.087366
...
2012-10-31 0.000000
2012-11-30 0.038889
2012-12-31 0.251344
Freq: M, Name: Weather, dtype: float64
In [9]:
is_snowing.astype(int).resample('M').mean().plot(kind='bar')
Out[9]:
Теперь мы знаем! В 2012, декабрь был самым снежным месяцем.
Строим графики температур и снежности вместе
Также можно объединить эти 2 статистики в один DataFrame и построить их графики вместе:
In [10]:
temperature = weather_2012['Temp (C)'].resample('M').median()
is_snowing = weather_2012['Weather'].str.contains('Snow')
snowiness = is_snowing.astype(int).resample('M').mean()
# Name the columns
temperature.name = "Temperature"
snowiness.name = "Snowiness"
Снова используем concat, чтобы объединить колонки в один DataFrame.
In [11]:
stats = pd.concat([temperature, snowiness], axis=1)
stats
Out[11]:
In [12]:
stats.plot(kind='bar')
Out[12]:
Ох, это не работает, потому что масштаб выбран неправильно. Лучше построим их на двух разных графиках:
In [13]:
stats.plot(kind='bar', subplots=True, figsize=(15, 10))
Out[13]:
array([,
], dtype=object)