
Тупо перебирать пиксели — скучно и неэффективно (даже для алгоритма!). Нужно много раз по-разному сжимать изображения, так AI будет учиться намного быстрей. Как и почему?
Самое смешное, что для того, чтобы улучшить качество, нужно выкинуть кучу имеющейся информации. Контринтуитивно, правда? Но это именно так! Важно выкинуть мусор — сжать изображение так, чтобы оно было более компактным, но не менее узнаваемым. Например:
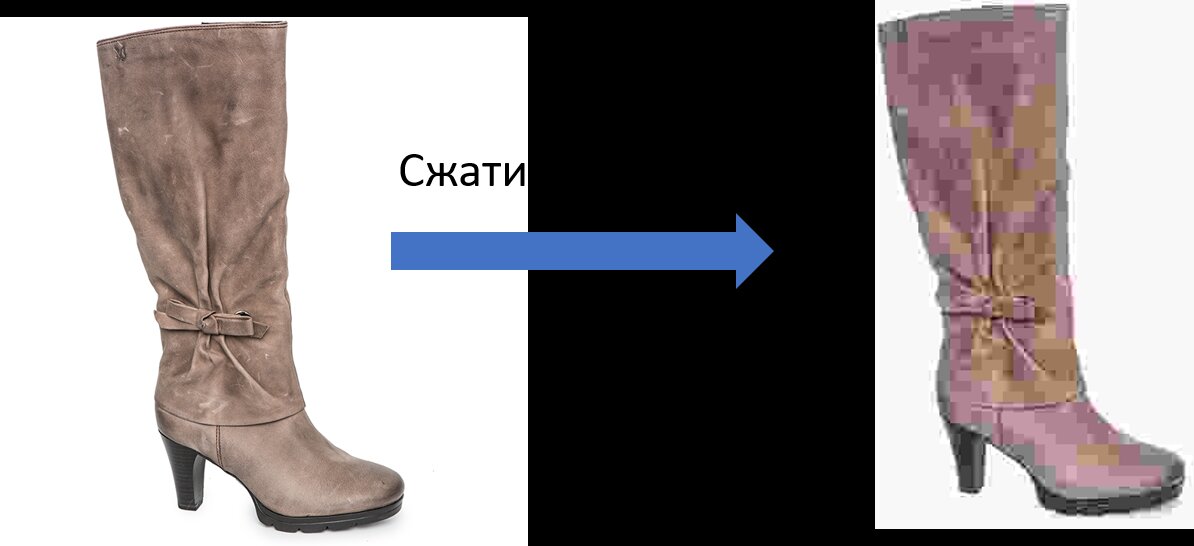
Второе изображение можно обработать в десятки раз быстрее, чем первое. Тем не менее, само по себе сжатие не дало бы преимуществ для обучения искусственного интеллекта — да, скорость обработки сжатой базы выросла бы кратно, но качество обучения сильно упало бы. В итоге, чтобы добиться высокого качества распознавания, пришлось бы увеличить базу во много раз. Это уничтожило бы выгоду от быстрой обработки.
Но есть решение! Одно и то же изображение можно сжимать не один раз, а множество, при этом меняя способ сжатия, чтобы каждый раз получались принципиально новые изображения. Таким образом, в сжатых изображениях будут проявляться разные важные черты исходного образа. Например, в домах в одном случае будут подчеркнуты вертикальные линии, а в другом — горизонтальные. Обработав их, алгоритм лучше поймет, что такое «дом», чем при обработке несжатой картинки дома.
Сейчас описанный алгоритм («сжатие и пулирование» — “convolutions and pooling”) является стандартным для распознавания изображения. Он позволяет увеличить скорость обучения в разы по сравнению с наивным подходом «пиксель за пикселем».
#наука #технологии #искусственный интеллект #it #распознавание образов