За последний год у нас было много запусков новых продуктов. Мы хотели добиться, чтобы API-сервисы легко масштабировались, были отказоустойчивыми и готовыми к быстрому росту пользовательской нагрузки. Наша платформа реализована на OpenStack, и я хочу рассказать, какие проблемы отказоустойчивости компонентов нам пришлось закрыть, чтобы получить отказоустойчивую систему. Думаю, это будет любопытно тем, кто тоже развивает продукты на OpenStack.

Общая отказоустойчивость платформы складывается из устойчивости её компонентов. Так что мы постепенно пройдем через все уровни, на которых мы обнаружили риски и закрыли их.
Видеоверсию этой истории, первоисточником которой стал доклад на конференции Uptime day 4, организованной ITSumma, можно посмотреть на YouTube-канале Uptime Community.
Отказоустойчивость физической архитектуры
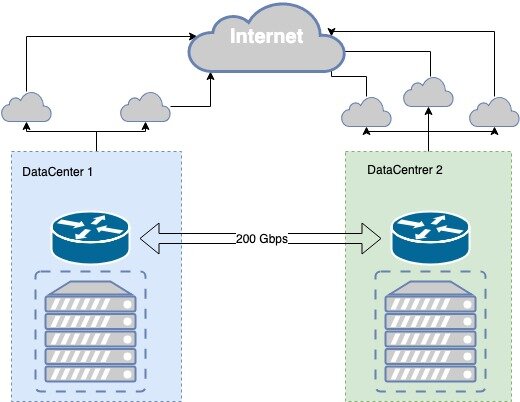
Публичная часть облака MCS сейчас базируется в двух дата-центрах уровня Tier III, между ними есть собственное темное волокно, зарезервированное на физическом уровне разными трассами, с пропускной способностью 200 Гбит/c. Уровень Tier III обеспечивает необходимый уровень отказоустойчивости физической инфраструктуры.
Темное волокно зарезервировано как на физическом, так и на логическом уровне. Процесс резервирования каналов был итеративный, возникали проблемы, и мы постоянно совершенствуем связь между дата-центрами.
Например, не так давно при работах в колодце рядом с одним из дата-центров экскаватором пробили трубу, внутри этой трубы оказался как основной, так и резервный оптический кабель. Наш отказоустойчивый канал связи с дата-центром оказался уязвимым в одной точке, в колодце. Соответственно, мы потеряли часть инфраструктуры. Мы сделали выводы, предприняли ряд действий, в том числе проложили дополнительную оптику по соседнему колодцу.
В дата-центрах есть точки присутствия провайдеров связи, которым мы транслируем свои префиксы по BGP. Для каждого сетевого направления выбирается лучшая метрика, что позволяет обеспечивать разным клиентам наилучшее качество соединения. Если связь через одного провайдера отключается, мы перестраиваем свою маршрутизацию через доступных провайдеров.
В случае отказа в работе провайдера мы в автоматическом режиме переключаемся на следующего. В случае отказа одного из дата-центров мы имеем зеркальную копию наших сервисов во втором дата-центре, которые принимают всю нагрузку на себя.
Что мы используем для отказоустойчивости на уровне приложений
Наш сервис построен на ряде opensource-компонентов.
ExaBGP — сервис, который реализует ряд функций с использованием протокола динамической маршрутизации на базе BGP. Мы активно его используем, чтобы анонсировать наши белые IP-адреса, через которые пользователи получают доступ к API.
HAProxy — высоконагруженный балансировщик, позволяющий настраивать очень гибкие правила балансировки трафика на разных уровнях модели OSI. Мы используем его для балансировки перед всеми сервисами: базы данных, брокеры сообщений, API-сервисы, web-сервисы, наши внутренние проекты — все стоит за HAProxy.
API application — web-приложение, написанное на python, с помощью которого пользователь управляет своей инфраструктурой, своим сервисом.
Worker application (далее просто worker) — в сервисах OpenStack это инфраструктурный демон, который позволяет транслировать API-команды на инфраструктуру. Например, создание диска происходит именно в worker, а запрос на создание — в API application.
Стандартная архитектура OpenStack Application
Большинство сервисов, которые разрабатываются под OpenStack, пытаются следовать единой парадигме. Cервис обычно состоит из 2 частей: API и worker’ы (исполнители бэкенда). Как правило, API — это WSGI-приложение на python, которое запускается либо как самостоятельный процесс (daemon), либо с помощью уже готового веб сервера Nginx, Apache. API обрабатывает запрос пользователя и передает дальнейшие инструкции на выполнение приложению worker application. Передача происходит с помощью брокера сообщений, как правило это RabbitMQ, остальные поддерживаются плохо. Когда сообщения попадают в брокер, их обрабатывают worker’ы из в случае необходимости возвращают ответ.
Эта парадигма подразумевает изолированные общие точки отказа: RabbitMQ и базу данных. Зато RabbitMQ изолирован в рамках одного сервиса и по идее может быть индивидуальным для каждого сервиса. Так что мы в MCS максимально разделяем эти сервисы, для каждого отдельного проекта создаем отдельную базу, отдельный RabbitMQ. Этот подход хорош тем, что в случае аварии в каких-то уязвимых точках ломается не весь сервис, а только его часть.
Количество worker application ничем не ограничено, поэтому API может легко масштабироваться горизонтально за балансировщиками в целях увеличения производительности и отказоустойчивости.
В некоторых сервисах необходима координация внутри сервиса — когда происходят сложные последовательные операции между API и worker’ами. В этом случае используется единый центр координации, кластерная система типа Redis, Memcache, etcd, которая позволяет одному worker’у сказать другому, что эта задача закреплена за ним («ты, пожалуйста, ее не бери»). Мы используем etcd. Как правило воркеры активно общается с базой данных, пишет и читает оттуда информацию. В качестве базы данных мы используем mariadb, которая у нас находится в мультимастер-кластере.
Такой классический одиночный сервис организован общепринятым для OpenStack образом. Его можно рассматривать как замкнутую систему, для который достаточно очевидны способы масштабирования и отказоустойчивости. Например, для отказоустойчивости API достаточно поставить перед ними балансировщик. Масштабирование worker’ов достигается за счет увеличения их количества.
Слабым местом во всей схеме являются RabbitMQ и MariaDB. Их архитектура заслуживает отдельной статьи.В этой статье хочу сфокусироваться на отказоустойчивости API.
Делаем балансировщик HAProxy отказоустойчивым с помощью ExaBGP
Чтобы наши API были масштабируемы, быстры и отказоустойчивы, мы поставили перед ними балансировщик. Мы выбрали HAProxy. На мой взгляд, он обладает всеми необходимыми характеристиками под нашу задачу: балансировка на нескольких уровнях OSI, интерфейс управления, гибкость и масштабируемость, большое количество методов балансировки, поддержка таблиц сессий.
Первая проблема, которую необходимо было решить, — отказоустойчивость самого балансировщика. Просто установка балансировщика тоже создаёт точку отказа: балансировщик ломается — сервис падает. Чтобы так не получалось, мы использовали HAProxy совместно с ExaBGP.
ExaBGP позволяет реализовать механизм проверки состояния сервиса. Мы использовали этот механизм для того, чтобы проверять работоспособность HAProxy и в случае проблем выключать сервис HAProxy из BGP.
Схема ExaBGP+HAProxy:
- Устанавливаем на три сервера необходимый софт, ExaBGP и HAProxy.
- На каждом из серверов создаём loopback-интерфейс.
- На всех трех серверах прописываем на этот интерфейс один и тот же белый IP-адрес.
- Белый IP-адрес анонсируется в интернет через ExaBGP.
Отказоустойчивость достигается путем анонса одного и того же IP-адреса со всех трех серверов. С точки зрения сети один и тот же адрес, доступен с трех различных next хопов. Маршрутизатор видит три одинаковых маршрута, выбирает по собственной метрике наиболее приоритетный из них (это обычно один и тот же вариант), и трафик идёт только на один из серверов.
В случае проблем с работой HAProxy или выхода сервера из строя, ExaBGP перестает анонсировать маршрут, и трафик плавно переключается на другой сервер.
Таким образом мы добились отказоустойчивости балансировщика.
Схема получилась неидеальной: мы научились резервировать HAProxy, но не научились распределять нагрузку внутри сервисов. Поэтому мы эту схему немного расширили: перешли к балансировке между несколькими белыми IP-адресами.
Балансировка на базе DNS плюс BGP
Остался не решен вопрос балансировки нагрузки перед нашими HAProxy. Тем не менее, решить его можно достаточно просто, как мы поступили и у себя.
Для балансировки трех серверов понадобится 3 белых IP-адреса и старый добрый DNS. Каждый из этих адресов определяется на loopback-интерфейс каждого HAProxy и анонсируется в интернет.
В OpenStack для управления ресурсами используется каталог сервисов, в котором задается endpoint API того или иного сервиса. В этом каталоге мы прописываем доменное имя — public.infra.mail.ru, который резолвится через DNS тремя разными IP-адресами. В результате мы получаем распределение нагрузки между тремя адресами посредством DNS.
Но так как при анонсировании белых IP-адресов мы не управляем приоритетами выбора сервера, пока это не балансировка. Как правило, будет выбираться только один сервер по старшинству IP-адреса, а два других будут простаивать, поскольку не указаны никакие метрики в BGP.
Мы начали отдавать маршруты через ExaBGP с разной метрикой. Каждый балансировщик анонсирует все три белых IP-адреса, но один из них, главный для данного балансировщика, анонсируется с минимальной метрикой. Так что пока все три балансировщика в строю, обращения к первому IP-адресу попадают на первый балансировщик, обращения ко второму на второй, к третьему на третий.
Что происходит в тот момент когда один из балансировщиков падает? При отказе любого балансировщика его основой адрес всё ещё анонсируется с двух других, трафик между ними перераспределяется. Таким образом, мы отдаем пользователю через DNS сразу несколько IP-адресов. Путем балансировки по DNS и разной метрики мы получаем равномерное распределение нагрузки на все три балансировщика. И при этом не теряем отказоустойчивость.
Взаимодействие между ExaBGP и HAProxy
Итак, мы реализовали отказоустойчивость на случай ухода сервера, на основе прекращения анонса маршрутов. Но HAProxy может отключиться и по другим причинам, чем выход сервера из строя: ошибки администрирования, сбои внутри сервиса. Мы хотим убирать сломанный балансировщик из под нагрузки и в этих случаях, и нужен другой механизм.
Поэтому, расширяя предыдущую схему, мы реализовали heartbeat между ExaBGP и HAProxy. Это софтовая реализация взаимодействия между ExaBGP и HAProxy, когда ExaBGP использует кастомные скрипты для проверки статуса приложений.
Для этого в конфиге ExaBGP необходимо настроить health checker, который сможет проверять статус HAProxy. В нашем случае мы настроили health backend в HAProxy, а со стороны ExaBGP проверяем простым GET запросом. Если анонс перестает происходить, то HAProxy, скорее всего, не работает, и анонсировать его не надо.
HAProxy Peers: синхронизация сессий
Следующее, что необходимо было сделать, — синхронизировать сессии. При работе через распределенные балансировщики сложно организовать сохранение информации о сессиях клиентов. Но HAProxy — один из немногих балансировщиков, который умеет это за счет функционала Peers — возможности передачи между различными процессами HAProxy таблицы сессий.
Существуют разные методы балансировки: простые, такие как round-robin, и расширенные, когда запоминается сессия клиента, и он каждый раз попадает на тот же сервер, что и раньше. Мы хотели реализовать второй вариант.
В HAProxy для сохранения сессий клиента этого механизма используется stick-tables. Они сохраняют исходный IP-адрес клиента, выбранный таргет-адрес (бэкенд) и некоторую служебную информацию. Обычно stick-таблицы используются для сохранения пары source-IP + destination-IP, что особенно полезно для приложений, которые не могут передавать контекст сессии пользователя при переключении на другой балансировщик, например — в режиме балансировки RoundRobin.
Если stick-таблицу научить перемещаться между разными процессами HAProxy (между которыми происходит балансировка), наши балансировщики смогут работать с одним пулом stick-таблиц. Это даст возможность бесшовного переключения сети клиента при падении одного из балансировщиков, работа с сессиями клиентов продолжится на тех же бэкендах, что были выбраны ранее.
Для правильной работы должна быть решена проблема source IP-адреса балансировщика, с которого установлена сессия. В нашем случае, это динамический адрес на loopback-интерфейсе.
Правильная работа peers достигается лишь в определенных условиях. То есть, TCP-таймауты должны быть достаточно большими или переключение должно быть достаточно быстрое, чтобы TCP-сессия не успела оборваться. Тем не менее это позволяет бесшовно переключаться.
У нас в IaaS есть сервис, построенный по такой же технологии. Это Load Balancer как сервис для OpenStack, который называется Octavia. Он основан на базе двух процессов HAProxy, в нем изначально заложена поддержка peers. В этом сервисе они отлично себя зарекомендовали.
На картинке схематично изображено перемещение peers-таблиц между тремя инстансами HAProxy, предложен конфиг, как это можно настроить:
Если вы будете реализовывать такую же схему, её работу надо внимательно тестировать. Не факт, что это сработает в таком же виде в 100% случаев. Но, по крайней мере, вы не будете терять stick-таблицы, когда нужно помнить source IP клиента.
Ограничение количества одновременных запросов с одного и того же клиента
Любые сервисы находящиеся в открытом доступе, в том числе и наши API, могут быть подвержены лавинам запросов. Причины у них могут быть совершенно разные, от ошибок пользователей, до целенаправленных атак. Нас периодически DDoSят по IP-адресам. Клиенты часто ошибаются в своих скриптах, делают нам мини-DDoSы.
Так или иначе необходимо предусмотреть дополнительную защиту. Очевидным решением становится ограничивать количество запросов к API и не тратить процессорное время на обработку вредоносных запросов.
Для реализации подобных ограничений мы применяем rate limits, организованные на базе HAProxy, с помощью тех же stick-таблиц. Настраиваются лимиты достаточно просто и позволяют ограничить пользователя по количеству запросов к API. Алгоритм запоминает source IP, с которого производят запросы, и ограничивает количество одновременных запросов с одного пользователя. Само собой, мы вычислили средний профиль нагрузки на API у каждого сервиса и установили лимит ≈ в 10 раз больше этого значения. Мы продолжаем до сих пор внимательно наблюдать за ситуацией, держим руку на пульсе.
Как это выглядит на практике? У нас есть клиенты, которые постоянно пользуются нашими API для автомасштабирования. Они создают примерно по двести-триста виртуальных машин ближе к утру и удаляют их ближе к вечеру. Для OpenStack создать виртуальную машину, еще и с PaaS-сервисами, — как минимум 1000 API-запросов, так как взаимодействие между сервисами тоже происходит через API.
Такие перекидывания задач вызывают достаточно большую нагрузку. Мы эту нагрузку оценили, собрали дневные пики, увеличили их в десять раз, и это стало нашим rate-лимитом. Мы держим руку на пульсе. Часто видим ботов, сканеров, которые на нас пытаются посмотреть, есть ли у нас какие-нибудь CGA-скрипты, которые можно запустить, мы их активно режем.
Как обновлять кодовую базу незаметно для пользователей
Мы реализуем отказоустойчивость также и на уровне процессов деплоя кода. При выкатках бывают сбои, но их влияние на доступность сервисов можно минимизировать.
Мы постоянно обновляем свои сервисы и должны обеспечивать процесс обновления кодовой базы без эффекта для пользователей. Решить эту задачу удалось, используя возможности управления HAProxy и реализации Graceful Shutdown в наших сервисах.
Для решения этой задачи нужны было обеспечить управление балансировщиком и «правильное» выключение сервисов:
- В случае с HAProxy управление производится через stats-файл, который по сути является сокетом и определяется в конфиге HAProxy. Передавать ему команды можно через stdio. Но основным нашим инструментом контроля конфигураций является ansible, поэтому в нём есть встроенный модуль для управления HAProxy. Который мы активно используем.
- Большая часть наших сервисов API и Engine поддерживают технологии graceful shutdown: при выключении они дожидаются полного завершения текущей задачи, будь это http-запрос или какая-нибудь служебная задача. То же самое происходит с worker’ом. Он знает все задачи, который делает, и завершается, когда все успешно доделал.
Благодаря этим двум моментам, безопасный алгоритм нашего деплоя выглядит следующим образом.
- Разработчик собирает новый пакет кода (у нас это RPM), тестирует в dev-среде, тестирует в stage, и оставляет в stage-репозитории.
- Разработчик ставит задачу на деплой с максимально подробным описанием «артефактов»: версия нового пакета, описание нового функционала и другие подробности о деплое в случае необходимости
- Системный администратор начинает обновление. Запускает плейбук Ansible.
В свою очередь Ansible делает следующее:
- Берет пакет из stage-репозитория, по нему обновляет версию пакета в продуктовом репозитории.
- Составляет список бэкендов обновляемого сервиса.
- Выключает первый обновляемый сервис в HAProxy и дожидается окончания работы его процессов. Благодаря graceful shutdown мы уверены, что все текущие запросы клиентов завершатся успешно.
- После полной остановки API, worker’ов, выключения HAProxy Происходит обновление кода.
- Ansible запускает сервисы.
- Для каждого сервиса дергает определенные «ручки», которые делают unit-тестирование по ряду заранее определённых ключевых тестов. Происходит базовая проверка нового кода.
- Если на предыдущем шаге не было обнаружено ошибок, то бэкенд активируется.
- Переходим к следующему бэкенду.
После обновления всех бэкендов, запускаются функциональные тесты. Если их не хватает, то разработчик смотрит любую новую функциональность, которую он делал. На этом деплой завершен.
Эта схема не была бы рабочей, если бы у нас не было одного правила. Мы поддерживаем на бою одновременно старую и новую версии. Заранее, на этапе разработки софта, закладывается, что даже если будут изменения в базе данных сервиса, они не будут ломать предыдущий код. В результате происходит постепенное обновление кодовой базы.
Как реализовать отказоустойчивую архитектуру в облаке
Делясь собственными мыслями по поводу отказоустойчивой WEB-архитектуры, хочу еще раз отметить ее ключевые моменты:
- физическая отказоустойчивость;
- сетевая отказоустойчивость (балансировщики, BGP);
- отказоустойчивость используемого и разрабатываемого софта.
Всем стабильного uptime!
Что еще почитать:
Путь к Kubernetes и его преимущества для разработки.
Disaster Recovery: облака и аварийное восстановление IT-инфраструктуры.
Организация бэкапа PostgreSQL из Kubernetes в S3-хранилище.
Автор: Артем Карамышев, руководитель команды системного администрирования, Mail.Ru Cloud Solutions