В предыдущей статье цикла я обещал подвести некоторый промежуточный итог и показать, как все ранее описанное воплощается в реально существующих линейках микроконтроллеров. Выполняю данное обещание.
Сегодня я расскажу немного подробнее о микроконтроллерах STM8. Точнее, об их процессорах и памяти. При этом я пока не буду затрагивать систему команд (набор инструкций) и имеющиеся там устройства ввода-вывода. Это темы дальнейших статей.
Обращаю ваше внимание, что данная статья носит полностью прикладной характер. Понимание изложенного материала важно для успешного применения микроконтроллеров STM8. В том числе, если вы будете писать программы только на языках высокого уровня.
Все адреса в статье будут шестнадцатиричными, без какого либо дополнительного указания на этот факт.
Единое логическое адресное пространство
Как я уже говорил, микроконтроллеры STM8 построены на основе Гарвардской архитектуры, что подразумевает разные адресные пространства для программ и данных. При этом, адресное пространство ввода-вывода так же отдельное, но вот специфические для него машинные команды IN и OUT отсутствуют.
Однако, в процессорах STM8 все адресные пространства объединены в общее логическое пространство, которое, в некоторой степени, маскирует реальную картину. Я уже приводил упрощенный вид общего адресного пространства. Настало время рассмотреть его более подробно.
Сразу должен заметить, что в документации производителя начало памяти, то есть нулевой адрес (или просто меньший, если речь идет о диапазоне) на иллюстрациях показано сверху, а адреса возрастают сверху вниз. Я же привык к тому, что начало памяти на иллюстрациях внизу, а адреса возрастают снизу вверх. И в своих иллюстрациях я показываю именно так. Учитывайте это, когда будете читать фирменную документацию
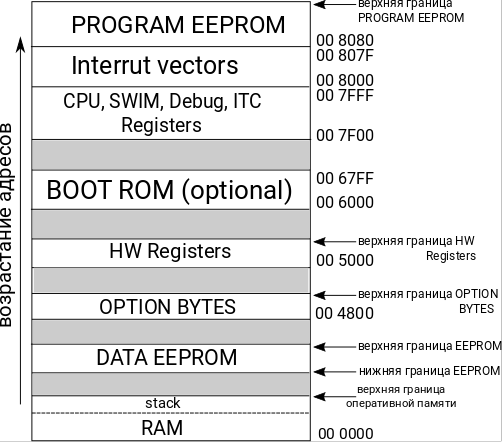
Сначала хочу обратить ваше внимание на указатели "верхняя граница" на иллюстрации. Это действительно не фиксированные адреса, а зависящие от объема имеющейся в микроконтроллере памяти соответствующего типа. Что же касается HW регистров, то здесь все определяется наличием или отсутствием дополнительных устройств и их количеством(например, АЦП или таймеры).
Далее нужно сказать про границы адресов DATA EEPROM. Иногда можно встретить в статьях и книгах утверждение, что EEPROM память для долговременного хранения данных начинается с адреса 00 4000. Однако, это не верно. И сама фирма ST указывает, что диапазон адресов EEPROM данных нужно искать в документации на используемый процессор. Для STM8S нижний адрес EEPROM данных действительно равен 00 4000, а вот для STM8L уже 00 1000.
Более подробно отдельные области памяти я рассмотрю чуть далее, сначала разберемся с адресацией внутри полного адресного пространства.
Адресация в полном адресном пространстве
Как видно, полное адресное пространство составляет 16 Мбайт, а полный адрес занимает 3 байта, или 24 разряда. Полный адрес, в терминах STM8, называется эффективным адресом (EA). В большинстве случаев нет необходимости каждый раз указывать полный адрес. Кроме того, это привело бы излишнему расходу памяти программ. Поэтому в STM8 предусмотрена возможность указывать сокращенный адрес.
Страницы и секции
Полное логическое адресное пространство STM8 разбито на секции длиной по 64 К байт. То есть, для адресации внутри секции нам нужен адрес длиной 16 разрядов (2 байта). На приведенной выше иллюстрации показаны адреса внутри секции 0 (первые две цифры адреса равны 00).
Каждая секция разбита на страницы длиной по 256 байт. То есть, для адресации внутри страницы нам нужен адрес длиной 8 разрядов (1 байт).
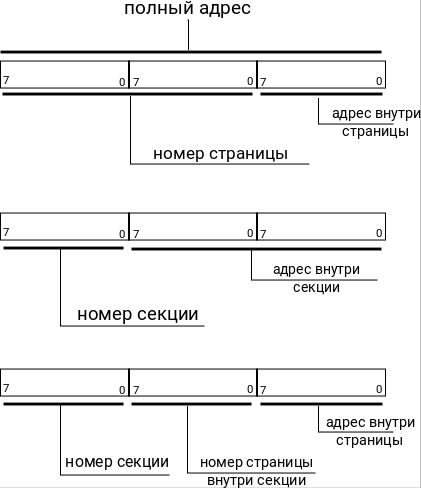
Не пугайтесь, это выглядит страшнее, чем есть на самом деле. И сейчас это станет понятно.
Короткий адрес
Короткий адрес имеет длину 8 бит. В документации производителя и программах на ассемблере, если в этом есть необходимость, такой адрес дополняется окончанием ".b". Например, table.b
Такие адреса могут использоваться в командах перехода по относительному адресу. Или при адресации внутри отдельного блока памяти. Хорошо видно, что короткий адрес это адрес внутри страницы.
Длинный адрес
Длинный адрес имеет длину 16 бит. В документации производителя и программах на ассемблере, если в этом есть необходимость, такой адрес дополняется окончанием ".w". Например, table.w
Наиболее часто используемый в программах для STM8 тип адреса. Хорошо видно, что длинный адрес это адрес внутри секции.
Расширенный (extended) адрес
Расширенный имеет длину 24 бита. В документации производителя и программах на ассемблере, если в этом есть необходимость, такой адрес дополняется окончанием ".e". Например, subr.e
Такие адреса, по другому называемые дальними (far), имеют ограниченное применение. Их можно использовать только в командах CALLF, RETF, JPF, LDF. Как видно, все эти команды имеют дополнительную букву F названии. Хорошо видно, что расширенный адрес является полным адресом, или эффективным адресом (EA).
Регистры процессора
Да, я немного нарушу порядок изложения, но без знания, какие регистры, и для чего, есть в процессоре, будут сложности с пониманием дальнейшего материала. На иллюстрации область адресов регистров процессора показана как "CPU, SWIM, Debug, ITC Registers". При этом я расскажу не про все регистры, а только про те, которые для нас сейчас важны. В частности я не буду рассказывать про регистр CFG_GCR, его использование выходит далеко за пределы темы данной статьи.
Аккумулятор
8-битный регистр общего назначения. В данном случае обозначается просто буквой А. Как я уже не раз показывал, аккумулятор очень часто используется как источник одного из операндов или как приемник результата операции. У STM8 здесь нет каких либо особенностей.
Индексные регистры
Имеется два 16-битных индексных регистра, X и Y. Индексные регистры могут использоваться и как регистры общего назначения. Младший байт индексных регистров имеет отдельное имя XL или YL, а старший XH или YH.
Указатель стека
16-битный регистр, обозначается SP. Содержит адрес следующей свободной ячейки стека. С этим регистром связано несколько особенностей режимов адресации.
Регистр кодов состояния (регистр флагов)
8-битный регистр, обозначается CC. Да, это тот самый регистр, который в большинстве случаев, в других процессорах, называется регистром флагов (FLAGS).
Регистр адреса команды (регистр-счетчик команд)
Содержит адрес следующей команды, которая будет выполняться процессором, обозначается PC. Имеет длину 24 бита. Самый младший байт регистра PC имеет собственное имя PCL, средний байт PCH, самый старший байт PCE.
Режимы адресации и их особенности
Теперь мы готовы рассмотреть, какие режимы адресации из рассмотренных в предыдущей статье, и как, реализованы в STM8.
Неявная адресация
Тут все просто. Неявное использование регистров и памяти или отражено в описании инструкции, или указывается в ее мнемонике (название инструкции или форма ее полного написания) дополнительной буквой.
Так команда RET неявно использует регистр указатель стека (SP) и память стека. Команда PUSH помешает в стек содержимое аккумулятора, а PUSHW содержимое индексного регистра X. Команда RLWA выполняет вращение (циклический сдвиг) регистра X через аккумулятор.
Непосредственная адресация
Тут тоже все просто. Непосредственный операнд помещается прямо в коде команды, сразу за кодом операции.
Регистровая адресация
А вот тут все немного хитрее. В процессоре есть не так много регистров. И они указываются в мнемонической форме записи. Например LD XH,A или LD XL,A. Но если посмотреть внимательнее, то станет видно, что это просто разные команды (имеют разные коды операции).
Более того, если указать вместо XH или XL регистры YH или YL, то можно увидеть, что код операции не изменился, но перед ним появился дополнительный байт называемый PRECODE, в данном случае 90. Если проводить аналогию с процессорами 80х86, то можно вспомнить, что там есть префиксы замены сегмента. А в STM8 есть "префиксы" замены регистра.
Прямая адресация
В коде команды размещается адрес операнда. Тут тоже нет больших особенностей. Но вот этот адрес может быть коротким или длинным, для большинства команд. Для некоторых команд, например, LDF, можно указывать и расширенный адрес.
С расширенным адресом все понятно, он является эффективным адресом. А вот не полные адреса просто дополняются слева нулевыми разрядами до длины полного адреса. Например, короткий адрес 3A превратится в полный адрес 00 003A. А длинный адрес F315 превратится в полный адрес 00 F315.
Косвенная адресация
А вот тут уже все гораздо интереснее. Как я говорил в предыдущей статье, косвенная адресация позволяет указать не адрес операнда, а адрес адреса операнда. А адреса у нас могут быть трех типов - короткие, длинные и расширенные. Получается множество вариантов! Но в STM8 на косвенную адресацию наложено несколько ограничений, которые позволяют сдерживать буйство фантазии программиста.
Во первых, расширенные адреса не допустимы при косвенной адресации. Во вторых, адрес ячейки памяти, в которой хранится адрес операнда, и который указывается в коде команды, может быть коротким или длинным. В третьих, адрес собственно операнда может быть только длинным. Причем для некоторых команд допустим только вариант длинного адреса ячейки хранящий длинный адрес операнда.
В данном случае обе команды поместят в аккумулятор содержимое ячейки с адресом 00 2134. Но вот длина адреса ячейки, содержащей адрес операнда, в этих двух командах разная.
Индексная адресация и индексная со смещением
Тоже довольно интересный случай. Понятно, что раз индексная, значит в ней будут участвовать индексные регистры X или Y. Но в STM8 в индексной адресации может участвовать и регистр SP.
Я не буду рассматривать отдельно индексную адресацию без смещения. Этот просто общий случай, когда смещение равно 0. Но вот с терминологией нам надо определиться, так как тут есть некоторая путаница.
Программистам наиболее привычно употребление термина "индекс" в контексте "индекс элемента массива". Фактически это номер элемента массива. А если индексов несколько, например, два, то можно говорить о номере строки и номере столбца элемента. И так далее.
Как из индекса массива получается адрес ячейки памяти я когда то давно описывал в статье "Однородные структуры данных - массивы и матрицы". Очень советую прочитать эту статью, если вы не знаете, как это происходит.
Итак, индекс на самом деле определяет смещение нужной ячейки памяти относительно базового адреса массива. Заметили некоторую, почти казуистическую, запутанность? Индекс определяет смещение... А у нас индексная адресация со смещением...
Не пугайтесь, сейчас я вас распутаю. В нашем случае вся память представляет из себя массив байт. Поэтому и индекс является номером нужного нам байта, то есть, именно индексом. А базовый адрес массива, по своей сути, является смещением начала массива относительно начала памяти. Кстати, аналогично и для процессоров оперирующих не только байтами.
Теперь стало понятнее? В нашей индексной адресации смещение это и есть базовый адрес массива. А индекс это номер элемента массива. Если смещение не задано (отсутствует, равно 0), то индекс это номер ячейки памяти относительно ее начала. И именно так надо рассматривать индексную адресацию.
А вот теперь можно увидеть, что смещение, то есть базовый адрес массива, адрес начала блока памяти, у нас может быть коротким, длинным, и расширенным. А все индексные регистры (X, Y, SP) 16 разрядные.
Здесь я показал две команды с индексной адресацией. Они обе загружают в аккумулятор содержимое ячейки с адресом 00 0161. При этом в команде
LDA A,(X)
смещение отсутствует. А значит, регистр X содержит номер байта (индекс байта) относительно начала памяти. Перед выполнением данной команды мы должны загрузить в X длинный адрес нужной ячейки памяти, который и будет номером байта (индексом) относительно начала памяти. В команде
LD A,(table,Y)
у нас есть смещение. Это адрес начала массива table в памяти (смещение начала массива относительно начала памяти). А регистр Y, в данном случае, содержит индекс нужного нам элемента массива table. Нам нужен 11 (17, десятичное) элемент массива. Команда вычислит эффективный (полный) адрес памяти сложив адрес начала массива (00 0150) и содержимое регистра Y (0011). Причем сложение будет беззнаковое.
В данном примере у нас адрес начала массива table получился длинным, но он может быть и коротким, и расширенным. Правда при расширенном адресе начала массива нам потребуется использовать команду LDF, но все остальное будет точно таким же.
Косвенная индексная адресация
А если мы будем задавать смещение (адрес начала массива в памяти) не прямо в команде, а в отдельной ячейке памяти? Мы получим косвенную индексную адресацию. В предыдущей статье я приводил в пример массив строк из языков высокого уровня. Например, список параметров переданных через командную строку или список переменных окружения.
Давайте вспомним, что у нас есть дв способа указать адрес ячейки хранящей адрес операнда короткий и длинный адрес. Учтем, что у нас теперь нет возможности задать смещение напрямую в команде, оно хранится в ячейке памяти. Но это смещение может быть либо длинным, либо расширенным адресом, и никак иначе.
То есть, с точки зрения косвенной составляющей адресации тут все без изменений. А из индексной составляющей исключена возможность указать короткое смещение (короткий адрес начала массива).
Здесь я показал массив строк strtbl и две строки, адреса которых хранятся в strtbl. Я немного отошел от строгого синтаксиса указания длины адреса для strtbl+2. Во первых, что бы не загромождать пример. Во вторых, ассемблер сможет сам определить этот размер исходя из расположения strtbl в памяти. А длину адреса, который хранится в strtbl мы укажем либо сами (dc.w), либо предоставим ассемблеру разбираться самому исходя из адресов строк. Так что ассемблер может сформировать правильный двоичный код.
На этой иллюстрации хорошо видно, что нам не хватает возможности указать смещение для косвенной индексной адресации, что бы упростить работу с strtbl. Но увы, такова реальность. Поэтому адрес strtbl[1], который хранит адрес нужной нам строки string2, приходится вычислять такой вот конструкцией на этапе компиляции. При статическом размещении ничего страшного нет. А при динамическом мы просто добавим предварительный шаг с индексной адресацией со смещением.
В данном примере нам нужен второй символ строки, то есть, элемент string2[1]. Именно он и будет загружен в аккумулятор. Другими словами, мы можем условно описать выполняемую этой командой операцию как
strtbl[1][1] -> A
Если у нас strtbl будет хранить расширенные адреса (то есть, полные) строк, то каждый его элемент будет занимать три байта. При этом мы должны будем вместо LD использовать LDF. И тогда мы сможем получить доступ за пределы нулевой секции (за пределы 64 К байт).
Адресация с автоинкрементом и автодекрементом
В явном виде не реализована. Но команды PUSH и POP (всех разновидностей) реализуют индексную адресацию с автоинкрементом и автодекрементом с использованием SP в качестве индексного регистра. Только делают это неявно.
Относительная адресация
Используется в командах перехода и вызова подпрограммы. По своей сути это непосредственная адресация, но с немного измененными правилами. Байт со знаком (это важно!) складывается с содержимым PC для получения эффективного адреса, на который и будет передано управление.
Битовая адресация и битовая с относительной адресация
При битовой адресации вы указываете адрес байта с помощью прямой адресации с длинным форматом адреса и номер бита, с помощью прямой адресации.
Битовая с относительной адресация просто является объединением битовой, для указания номера бита и адреса байта, и относительной, для вычисления адреса перехода. Так что это нельзя назвать отдельным способом адресации. Просто некоторые операции, например, BTJT, требуют указания адреса байта, номера бита, и относительного адреса перехода. Фирма ST почему то решила, что это отдельный вид адресации...
RAM (ОЗУ), или память данных, и стек
Но хватит про адресацию. Пора переходить к рассмотрению особенностей отдельных областей памяти.
Память данных это просто адресуемый массив ячеек памяти размером в 1 байт. И за одну операцию чтения/записи доступ возможен лишь к одному байту. То есть, операции выполняются побайтно.
Стек располагается в области памяти данных, обычно в ее верхней части. И адресуется 16-разрядным регистром SP. Стек растет от больших адресов памяти к меньшим. То есть, у нас память данных заполняется с двух сторон. Собственно данные в начале памяти и в сторону увеличения адресов. Стек, в конце памяти и в сторону уменьшения адресов.
Однако, никто не запрещает вам записать в SP адрес ячейки, скажем, где то в середине памяти данных. И получить таким образом две области памяти данных (логических!) и стек между ними.
Однако нужно помнить, что в некоторых микроконтроллерах существует еще и граница для нижнего предела адреса в стеке. При достижении этой границы (при помещении элемента в стек) в SP автоматически загружается адрес конца памяти данных. Такого "заворачивания" адресов не происходит при использовании SP как индексного регистра.
Но если вы запишете в SP адрес ячейки ниже нижнего предела, то автоматического перехода к концу памяти данных происходить не будет. И контроль за состоянием стека нужно будет делать вручную.
EEPROM данных и OPTION BYTES
Про долговременную память данных я уже кратко упоминал, с точки зрения ее расположения. Более подробно работа с такой памятью будет рассмотрена отдельно, вне рамок данной статьи.
OPTION BYTES это область которая хранит конфигурацию микроконтроллера и позволяет ей управлять. Данные вопросы лежат за рамками данной статьи и будут рассматриваться отдельно.
HW Registers
Это область размещения регистров оборудования, то есть, устройств ввода-вывода микроконтроллера. По сути, это область соответствует адресному пространству ввода-вывода, хоть в контексте STM8 об этом и не говорится.
Работу с регистрами оборудования я буду рассматривать, когда мы доберемся до изучения этих устройств.
BOOT ROM
Область памяти программы-загрузчика (bootloader). Основное ее назначение это позволить пользователю конечного устройства (хотя и не обязательно ему) загружать в память программ данные (обновления прошивки, например) не через интерфейсы программирования (не написания программы, а ее записи в микроконтроллер, прошивки), вроде SWIM, а через, например, UART. То есть, не требуется наличия аппаратного программатора.
Данную область можно еще назвать системным загрузчиком.
Эта область памяти есть не во всех микроконтроллерах. Соответственно, и возможность использования загрузчика есть не всегда. Но никто не мешает реализовать некоторые возможности в коже основной программы. Правда при этом снижается надежность (термин "окирпичивание" наверняка знаком многим). И область для пользовательского загрузчика действительно существует.
Работу с загрузчиком я так же буду рассматривать отдельно, вне рамок данной статьи.
CPU, SWIM, Debug, ITC Registers
Регистры процессора я уже описывал. А остальные регистры это тема отдельных статей.
Interrupt vectors и PROGRAM EEPROM
Это последние области памяти, которые есть в микроконтроллере (из мной рассматриваемых). И я не зря объединил эти области. Дело в том, что область векторов прерывания это часть памяти программ.
Кроме того, область памяти программ поделена не только как уже описанная часть общего адресного пространства, но и по своему. Причем даже в зависимости от "плотности" (density) устройства. Я приведу деление для линейки STM8S (обратите внимание на букву S, которую я впервые добавил). И только для примера, что бы вы имели представление. Для наших целей, в данный момент, это не очень важно.
- Low density. Имеют 8 кБ памяти программ состоящей из 128 страниц (блоков) по 64 байта каждый. Память программ разделена на две области - область пользовательского загрузчика (UBC), размер которой можно задать с помощью байта конфигурации, и области основной программы.
- Medium density. Имеют от 16 до 32 кБ памяти программ состоящей из до 64 страниц, каждая их которых состоит из 4 блоков, каждый из которых состоит 128 байт. Память программ разделена на две области, точно так же, как и для low density микроконтроллеров
- High density. Имеют от 32 до 128 кБ памяти программ состоящей из до 256 страниц, каждая из которых состоит из 4 блоков, каждый из которых состоит из 128 байт.
Первые 128 байт памяти программ и занимаю векторы прерываний. Память программ можно перезаписывать, но по специальным, и довольно строгим, правилам. Рассматривать векторы я буду во время рассказа о собственно прерываниях ( и немного во время рассказа о работе микроконтроллера после сброса). Запись в память данных это тоже тема отдельных статей.
В отличии от памяти данных из памяти программ считывание идет не побайтно, а сразу по 4 байта (32 разряда). Это связано, в том числе, с тем, что Flash память, которая и используется для хранения программ, медленнее оперативной памяти.
Нарушение границ памяти Гарвардской архитектуры
Да, в STM8 такое возможно! Возможно копировать программный код в ОЗУ и выполнять его там. То есть, выполнять программу в памяти данных! Возможно и чтение (но не запись!) памяти программ как памяти данных. Посмотрите на интерфейс памяти, который фирма ST приводит в документации по STM8
Здесь видно два блока выборки данных из памяти. Первый блок работает с память программ и обозначен как "LDF" INSTRUCTION. Второй блок работает с памятью данных и обозначен как RAM FETCH INSTRUCTION. При этом оба блока работают с внутренней шиной @DATABUS, которая и поставляет данные и коды команд оборудованию процессора.
Именно благодаря такой схемотехнике и появляется возможность нарушения, до некоторой степени, границ областей памяти, которые должны быть изолированы, если строго следовать требованиям архитектуры.
Кстати, из этой же иллюстрации хорошо видно не только то, что с памятью данных идет работа по одному байту (DATABUS показана 8 разрядной), а с памятью программ по 4 байта (DATABUS(FETCH) 32-х разрядная), но и то, что адрес памяти данных 16 разрядный, а адрес памяти программ 24-разрядный.
Заключение
Пожалуй, на сегодня достаточно. Статья получилась очень большой, но не слишком трудной для понимания, если вы внимательно читали все предыдущие статьи.
Я уделил основное внимание прикладной части архитектуры памяти STM8. Это нам понадобится, что бы начать писать программы для этих микроконтроллеров. Многие аспекты я лишь упомянул, а то и вовсе обошел стороной. Но на данный момент у нас есть вся нужная информация. Многие из оставшихся областей памяти я рассмотрю в дальнейшем.
Но часть оставлю за рамками статей цикла. Вы сможете изучить их самостоятельно, когда (и если :) освоите все, что я еще буду рассказывать. В конечном итоге это не цикл статей по углубленному изучению STM8, а цикл статей о микроконтроллерах для начинающих.
До новых встреч!