
Автоматически или вручную?
Раньше, когда у меня возникало желание поупражняться в создании веб-сайтов, я просто заходил на веб-страницу, открывал консоль и пытался извлечь нужный мне контент – я поступал так в течение довольно длительного времени только для того, чтобы избежать набора условного, обычно бессмысленного текст-заполнителя, вставляемого в макет вэб-страницы.
Несколько месяцев назад я услышал о веб-скрэпинге – как говорится, лучше поздно, чем никогда, правда же? Оказалось, что эта штука делает ровно то, что я пытался сделать вручную.
Теперь я попытаюсь объяснить Вам как веб-скрэпить с помощью Node.js.
Подготовка
Мы будем использовать три пакета.
- Axios «обеспечивает основу HTTP клиента для браузера и node.js» и мы воспользуется им, чтобы получить html-код из любого выбранного нами вэб-сайта.
- Cheerio похож на jQuery, но предназначен для сервера. Мы будем его использовать для извлечения контента из html-кода, полученного с помощью Axios.
- fs – модуль узла, который мы будем использовать для записи извлеченного контента в JSON-файл.
Давайте настроим проект. Сначала создадим папку (директорию, каталог), затем войдем в нее с помощью команды терминала cd.
Для инициализации проекта просто запустите npm init и следуйте шагам (вы можете просто нажимать enter на каждом шаге). Когда установка инициализации завершится, вы получите файл package.json.
Теперь нам нужно установить два пакета, упомянутых выше.
npm install --save axios cheerio
(Помните, fs уже есть часть узла, нам ничего не нужно устанавливать)
Вы увидите, что упомянутые выше пакеты установлены в директории node_modules, они также находятся в списке файла package.json.
Получение контента из dev.to
Ваш dev.to профиль находится на https://dev.to/<username>. Наша цель – получить записанные там посты и сохранить их в файл json, следующим образом:
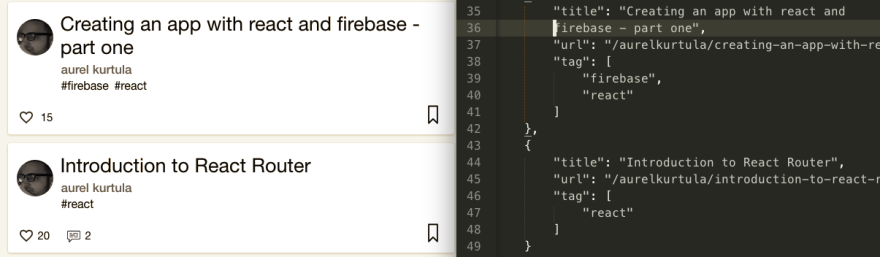
Создайте файл JavaScript в вашей директории проекта, назовите его devtoList.js.
Требуемые пакеты установлены.
Теперь давайте извлечем контент из dev.to.
В первой строке находится определенные URL. Как уже упоминалось, axios надежная основа, затем (then) мы проверим корректность отклика, и получим данные.
Если вы просмотрите с помощью консоли лог-файл response.data, то увидите, что html-разметку по этому адресу. Когда мы загрузим этот html в cheerio (jQuery сделает это за нас в фоновом режиме). Для пущей наглядности давайте заменим response.data на жестко закодированный html:
const html = '<h3 class="title">I have a bunch of questions on how to behave when contributing to open source</h3>'
Этот код вернет строку без тэга h3.
Отбор контента
На данном этапе вы можете зайти через консоль на вэб-сайт, с которого вы хотите найти и извлечь нужный контент. Это будет выглядеть так:
Исходя из вышеизложенного вы уже знаете, что каждая статья относится к классу single-article. Заголовок форматирован тэгом h3 и тегами внутри класса tags.
Приведенный выше код очень легко прочесть, особенно, если вернуться к приведенному выше скриншоту. Мы проходимся по каждому узлу классом .single-article. Затем находим только h3, получаем из него текст и просто обрезаем trim() избыточное пустое пространство. Затем также просто получаем URL-адрес, просто получая href из соответствующего тега привязки.
Получение тегов действительно просто. Сначала получаем их всех как строку (#tag1 #tag2), затем разбиваем эту строку (в местах, где встречается символ (#) и формируем из ее частей массив. Наконец, мы просматриваем каждое значение в массиве, чтобы обрезать trim() пустое пространство, и наконец, отфильтровываем все пустые значения (которые образовались из-за проводимого ранее тримминга (обрезки)).
Объявление пустого массива (let devtoList = []) вне цикла позволяет нам заполнять его изнутри.
Это то, что надо. Объект массива devtoList содержит данные, которые мы извлекли из веб-сайта. Теперь нужно просто сохранить эти данные в файле JSON, чтобы позднее воспользоваться контентом.
Исходный объект массива devtoList может иметь пустые значения, поэтому мы просто обрезаем их, а затем используем модуль fs для записи в файл (выше, я назвал его devtoList.json, содержание которого в виде объекта массив преобразовано в JSON.
И это все, что нужно!
Весь приведенный код можно найти в github.
Наряду с извлечением информации с помощью dev.to и приведенного выше кода, я также извлекал книги из goodreads, фильмы из IMDB – использованный для этих целей код вы также найдете в репозитории.
Читайте нас в телеграмме, vk
Перевод статьи aurel kurtula: Introduction to web scraping with Node.js