Что в выбросах тебе моих?
Уважаемые коллеги,
в данном случае речь идет не о выбросах в окружающую среду от стационарных или передвижных антропогенных источников, а о так называемых необычных наблюдениях (Р.И. Кабаков, 2016), с коими имеет все шансы столкнуться не только начинающий исследователь, но и опытный ученый и даже (пожалуйста, не удивляйтесь!) практикующий работник здравоохранения или тем более организатор любого уровня упомянутой системы. Небольшая ремарка: выбросы могут возникнуть в данных не только вследствие человеческого фактора (ошибки при сборе информации, формировании баз данных, нарушение методологии инструментальных способов оценки, «нерепрезентативность» выборки и т.д.), но и действительно отражать особенности изучаемого явления (т.е. удалив их исследователь может сам того не ведая лишить свою работу, вероятно неочевидных, но весьма интересных выводов и следствий) – однако обо всем этом чуть позже… Давайте же разбираться с чем мы имеем дело. По мнению Вашего покорного слуги, именно они – эти коварные выбросы, и, являются наиболее часто встречающимися в повседневной жизни разжигателями бесконечных войн между сторонниками и ярыми противниками ценности исследований с учетом больших (и малых) объемов данных, статистического анализа в целом («статистика – продажная девка, но не под каждого она ляжет…» Вождь народов). Достаточно вспомнить еще одну крылатую фразу для того, чтобы оценить масштабы трагедии: «среднее по больнице». Однако, приведу один единственный и вполне достаточный довод в защиту (как-то это нелепо звучит в век цифровых технологий – ну да ладно) пользы и необходимости более серьёзного отношения к информации и статистическому анализу данных – в постиндустриальных странах уже с середины прошлого века (а может быть и задолго до этого?) информация возведена в статус ресурса, который может и должен быть тщательно и скрупулёзно собран, отобран, сохранен, при необходимости оценен, дополнен, доработан, проанализирован и, в конечном итоге, конвертирован в широкий диапазон реальных продуктов для общества, что дает право оценивать этот ресурс в эквивалентном количестве билетов банка любой страны. Возвращаемся обратно к выбросам. Действительно, менее обоснованно и репрезентативно использовать параметрические («среднее±стандартное отклонение или ст.ошибка», хотя для целей описания «нормально распределенного» признака более предпочтительна следующая «пачка»: среднее±95%-ый доверительный интервал) методы описательной статистики вместо непараметрических (первый, второй и третий квартили или иными словами 25%, 50% и 75% квантили) для характеристики явлений, имеющих большую дисперсию или имеющих явно выраженные выбросы, иными словами при наличии наблюдений, заметных невооруженным глазом на графике рассеивания (scatterplot), что довольно часто сопровождается ненормальностью распределения признака. Применение подобных расчету квартилей (квантилей) робастных (устойчивые к негомогенности дисперсии, выбросам отдельных наблюдений признака) методов стат. обработки может полностью удовлетворить любознательность исследователя, если анализ данных завершается на этапе описательных методов статистики либо проводятся более углубленные методы (т.е. дальнейший анализ) при определенно достаточном количестве наблюдений (выбросы могут быть «безболезненно» удалены). Однако, в последнем случае исследователю лучше на всякий случай еще раз убедиться в репрезентативности своей выборки, а также более внимательно оценить и попытаться выявить возможную причину появления необычных наблюдений. Дьявол, как говорится, кроется в деталях. Репрезентативность – степень соответствия количественных значений и/или качественных характеристик (показателей) выборки генеральной совокупности. Таким образом, выводы, закономерности, полученные в результате проведения исследования с использованием репрезентативной выборки в определенной степени допустимо экстраполировать на всю генеральную совокупность. Не буду останавливаться на принципах и способах проверки имеющегося набора данных на репрезентативность. На мой взгляд они заслуживают как минимум отдельного поста. Позволю себе лишь одно незначительное замечание по этому поводу: нет необходимости в проведении проверки на репрезентативность при оценке показателей на всей генеральной совокупности, например, общая смертность ВСЕГО населения РФ (или региона РФ) в пожилом возрасте.
В каких случаях мы имеем дело с выбросами?
А) Осознанно выявляем их, при проведении стандартных методов описательной статистики, т.е. мы задаемся вопросом: «все ли в порядке с моей базой данных?», проверяем наши данные на нормальность распределения, оцениваем дисперсию признаков, достаточность наблюдений (мощность) для достижения поставленной цели исследования, репрезентативность признаков (помимо количества наблюдений, следует учесть такие не менее важные аспекты, как дизайн исследования, качество и точность сбора исходных данных и т.д.).
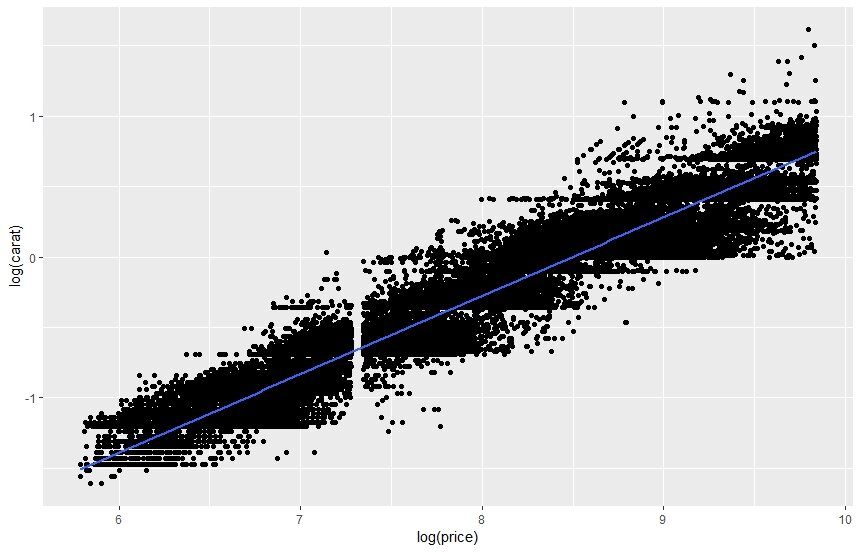
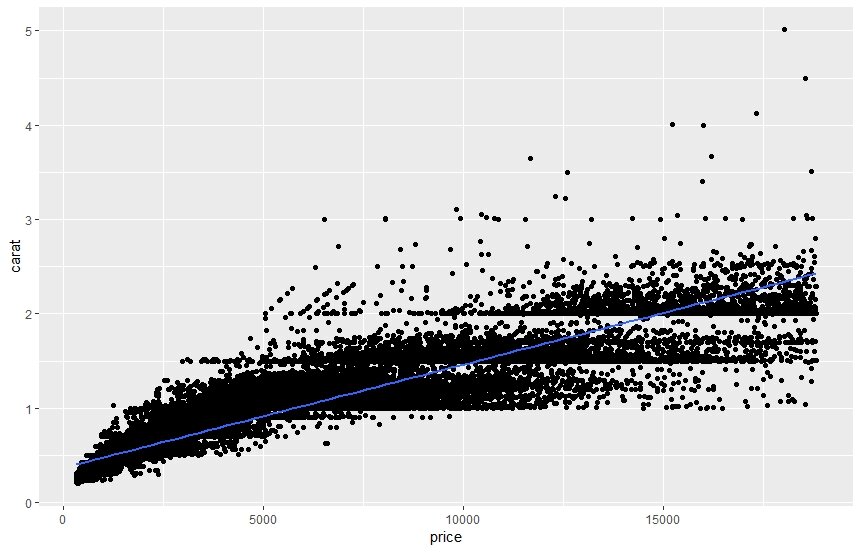
Б) Случайно сталкиваемся с ними, в ходе проведения методов машинного обучения с учителем (не Марь Иванна или географ Служкин, а воображаемый контроллер, регулирующий выбор наиболее оптимальной модели предсказания одной переменной по значениям математически/логически преобразованных других переменных). В данном случае регрессионный линейный анализ служит отличным примером, т.к. его результат его проведения представляет собой ни что иное, как «математическую модель определения интересующего нас зависимого показателя посредством математических преобразований значений предикторов (независимых показателей) вкупе с линейной аппроксимацией методом наименьших квадратов», иными словами модель рассчитывает математическую формулу, которую в случае однофакторной регрессии (с одним предиктором) можно представить в виде двумерного графика с двумя переменными по осям X и Y, на котором изображена прямая, максимально точно отражающая тенденцию по изменению зависимой переменной (ось Y) при изменении на определенное количество единиц предиктора (ось X) с учетом того, что наклон нарисованной прямой характеризуется наименьшим количественным значением остатков (разница между наблюдаемыми и ожидаемыми значениями зависимой переменной). Так вот, допустим, вы провели однофакторный линейный регрессионный анализ по выявлению зависимости индекса массы тела (ИМТ) от возраста пациента, допустим, получили значимую модель, т.е. указанный предиктор (возраст) с определенной степенью вероятности способен объяснять зависимую переменную (ИМТ). Однако, при построении графика рассеивания для этих двух переменных сталкиваетесь с досадной проблемой - указанные характеристики некоторых пациентов выходят за границу 95% доверительного интервала (следовательно, в данных наблюдениях мы имеем большие значения остатков между спрогнозированными и реальными уровнями ИМТ) полученной модели. Небольшое примечание по этому пункту. Помимо стандартных методов выявления выбросов на глаз (построение графиков рассеивания – ScatterPlots, ящиков с усами – Box-and_whiskers plots) мы можем воспользоваться специализированными функциями, реализованными в ПО, применяющимся для стат. обработки данных. Например, в R (R Studio) есть замечательная функция «outlierTest», содержащаяся в пакете «car». Она позволяет нам без труда выявить необычные наблюдения (с p-уровнем значимости <0,05), плохо поддающиеся интерпретации в построенной регрессионной модели.
Гипотетически можно представить наиболее часто встречающихся причины наличия необычных наблюдений при проведении линейной регрессии с последующей визуализацией на графике рассеивания:
1) Показатели связаны не линейно между собой, т.е. линейная аппроксимация (усреднение, приближение) не способна «поймать» реальный характер связи между ними. Вероятно, в подобном случае, имеет смысл применить нелинейную (экспоненциальную, логарифмическую и т.д.) функцию для построения математической формулы определения Y от X.
2) гетероскедастичность (цитата из Википедии) «- понятие, используемое в прикладной статистике (чаще всего — в эконометрике), означающее неоднородность наблюдений, выражающуюся в неодинаковой (непостоянной) дисперсии случайной ошибки регрессионной (эконометрической) модели. Гетероскедастичность противоположна гомоскедастичности, означающей однородность наблюдений, то есть постоянство дисперсии случайных ошибок модели.
Наличие гетероскедастичности случайных ошибок приводит к неэффективности оценок, полученных с помощью метода наименьших квадратов. Кроме того, в этом случае оказывается смещённой и несостоятельной классическая оценка ковариационной матрицы МНК-оценок параметров. Следовательно, статистические выводы о качестве полученных оценок могут быть неадекватными. В связи с этим тестирование моделей на гетероскедастичность является одной из необходимых процедур при построении регрессионных моделей.»
https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D1%82%D0%B5%D1%80%D0%BE%D1%81%D0%BA%D0%B5%D0%B4%D0%B0%D1%81%D1%82%D0%B8%D1%87%D0%BD%D0%BE%D1%81%D1%82%D1%8C
Наиболее действенный способ борьбы с гетероскедастичностью – преобразование (степенное, логарифмическое, экспоненциальное и т.д.) как самих предикторов, так и зависимых показателей, и даже – и предикторов и зависимых переменных одновременно. Однако стоит отметить один интересный момент. В том случае, если исследователя интересует лишь прогнозирование, определение количественного значения одной или нескольких переменных с помощью одного/нескольких предикторов, то применение всевозможных видов преобразований может быть вполне обоснованно и оправданно. Однако, в биомедицинских исследованиях в подавляющем числе случаев необходимо попытаться не только выявить взаимосвязи, построить математические, логические модели по прогнозирования/определения, но и попытаться объяснить, проинтерпретировать характер выявленных связей/взаимосвязей. Как мы с вами, к примеру, проинтерпретируем зависимость концентрации триглицеридов в плазме крови от выраженности (количественная переменная) экспрессии гена NNX (в степени X)? К счастью есть «удобоинтерпретируемый» способ преобразования наших с вами данных, который, кстати говоря, еще и способен разрешать проблему гетероскедастичности – преобразование по натуральному логарифму. Данное преобразование довольно часто встречается в публикациях зарубежных авторов. Однако, подробное описание данного вида преобразования и детали его интерпретации (основной принцип который заключается в прогнозировании искомой переменной по изменению не самого численного значения предикторов, а изменения их доли, выраженной в процентах или как Вам удобно), я, пожалуй, отражать сейчас не стану дабы не перегружать итак чересчур перегруженный текст.
Подведем итоги
Необычныеные наблюдения, удостоенные пристального внимания искушенного и внимательного исследователя могут на поверку оказаться как банальными выбросами, возникшими в результате недостаточного объема, а следовательно, нерепрезентативности выборки, либо различного рода ошибок и неточностей, допущенных на любом из этапов исследования (человеческий фактор еще никто не отменял), так и заслуживающими внимания, информативными наблюдениями. В последнем случае следует попытаться на глаз посредством графических способов отображения (графика рассеивания зачастую вполне достаточно) характер взаимосвязи (линейная-нелинейная). При обнаружении гетероскедостичности (веерообразный характер рассеивания точек на графике) – применить один из видов преобразований переменных. При этом, наиболее предпочтительным и рационально интерпретируемым видом преобразования является преобразование по натуральному логарифму.
Репрезентативных Вам выборок!