Источник: https://shalaginov.com/2019/10/27/6551/
Термин «нейросети» (Neural networks) был очень популярен в конце 1980-х – начале 1990-х годов. Затем его цитируемость стала снижалась, поскольку их потенциал так и не удалось реализовать имеющимися в начале 2000-х годов средствами.
Нейросети состоят из слоёв т.н. “нейронов”. Эти сети могут передавать информацию только в одном направлении и обучаются на примерах (для классификации или регрессии).
Мозг приматов работает примерно также, поэтому была надежда на то, что, использовав больше слоёв в нейросети, можно будет получить более совершенные модели объектов.
Однако, впоследствии выяснилось, что обучающие модели с большим количеством слоёв хорошо не работают. Поэтому, исследователи пришли к выводу, что только «тонкие» (Shallow) модели в 1-2 слоя могут хорошо обучаться. Стандартная нейросеть имеет только один или два слоя представления данных (Shallow neural network, на рисунке, буквально: «мелкая нейросеть»).
Глубокие нейросети (deep neural network) с более, чем 1-2 слоями, ранее казалась любо нереализуемыми, либо непрактичными. До 2006 года, внешние слои нейросети были неспособны к извлечению характерных черт, т.н. “фич” (features), входных изображений, поскольку алгоритмы обучения нейросетей оставались несовершенными.
Однако, использование инновационных технологий, таких как анализ больших данных (Big Data) и развитие систем виртуализации в дата-центрах обеспечили возможность создания более мощных нейросетей. Например, использование простых средств оптимизации, таких как стохастический градиентный спуск (stochastic gradient descent), а также использование «неуправляемых» (unsupervised) данных в качестве предварительных (pre-train) обучающих моделей для автоматического извлечения характерных «фич». Также обучаемость сети повышает использование графических процессоров GPU.
Это сделало возможным использование «многослойных» глубоких нейросетей для обработки изображений в системах CV.
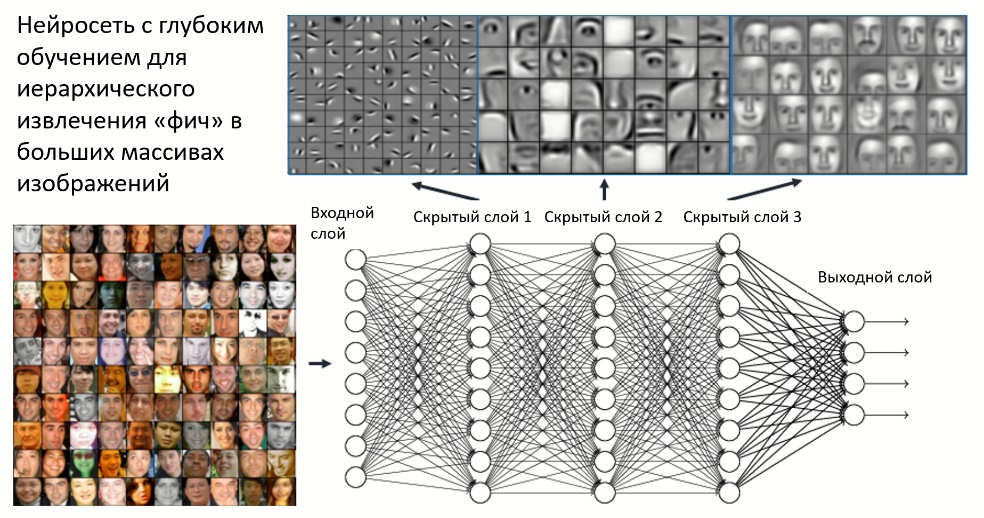
Рис. 1. Многослойная нейросеть с глубоким обучением для обработки изображений в системах CV (источник: RSIP Vision).
Свёрточные нейронные сети CNN (Convolutional Neural Networks) — это один из вариантов нейросетей с глубоким обучением, появились благодаря нейробиологическим исследованиям нервных клеток в коре головного мозга, ответственных за обработку изображений, получаемых от зрительных нервов.
CNN могут извлекать топологические особенности изображения, а также распознавать визуальные формы непосредственно из пиксельного изображения, практически без предварительной обработки, и с высокой вариабельностью, например, они могут различать рукописный текст и изображения натуральных предметов.
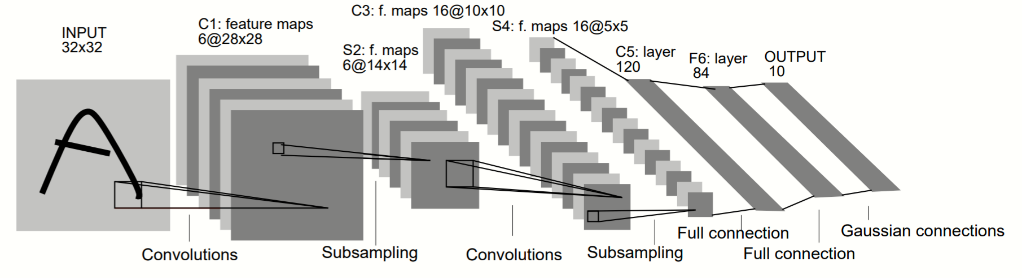
Рис. 2. CNN Le-NET5, способная распознавать рукописный текст (источник: IEEE, 1998).
CNN обычно состоит из слоёв свёртки (Сonvolutions), слоёв предварительного выделения образов (Subsampling), полностью подключённых слоёв (Full Connection) и слоёв распределения Гаусса (Gaussian Connections).
Принцип работы CNN и различие между machine learning и deep learning показаны на рисунке ниже.
Рис. 3. Принцип работы CNN (источник: MathWorks).