
Если вы хотите научить нейросеть распознавать объекты на фото, вам понадобятся картинки. Где их взять? Конечно, в Google. Но вам нужно много картинок, так что пока вы будете скачивать их вручную, у вас может пропасть все желание становиться разработчиком. Поэтому лучше автоматизировать процесс, тем более, что для этого в Python есть все возможности.
Как скачать изображения с простой страницы
Сначала рассмотрим самый простой случай, когда вам нужно загрузить картинки с обычной, статичной страницы. Это значит, что на ней нет интерактивных JavaScript-элементов, все данные написаны в коде, как они есть.
Первое, чем вы можете воспользоваться — это родная библиотека Python под названием requests. С ее помощью вы получите весь код страницы, откуда сможете достать нужные элементы. Главный минус — откапывать их придется в куче мусора. Так что лучше воспользоваться дополнительными инструментами:
- Библиотека Beautiful Soup упрощает процесс, позволяя строить чистое парсинговое дерево. Достаточно посмотреть в исходном коде веб-страницы, как называется интересующий вас класс объектов, и прописать его в команде Beautiful Soup. Дальше, листая полученные объекты, вы сможете собрать нужные элементы.
- Библиотека Pandas содержит метод read_html, который тоже поможет в вашей задаче. Чтобы воспользоваться этими инструментами, нужно сначала установить парсер XML и HTML lxml. После этого read_html сможет собирать нужные вам данные в отдельные дата-фреймы, а вы сможете листать их в поисках ценных материалов.
Для наших целей эти средства не подходят, поэтому мы не будем подробно на них останавливаться.
В большинстве случаев сайты требуют от пользователя неких действий, прежде чем предоставят нужный контент. Чтобы загрузить картинки из таких источников, вам нужно такие действия изобразить, и это чуть сложнее, чем просто спарсить статичное содержимое. Все эти возможности объединяет в себе библиотека Selenium.
Ее основное предназначение — это тестирование ПО. Для этой задачи разработчики предусмотрели функции запуска приложений, передвижения курсора и кликов по кнопкам. Как вы понимаете, все это делает Selenium оптимальным инструментом для наших целей.
Перед началом работы вам нужно скачать с сайта разработчиков драйвер для вашего браузера и положить его в какую-нибудь удобную папку. Далее установите пакет Selenium через команду pip install selenium и укажите ему путь к этой директории.
Чтобы запустить эмулированный браузер, используйте следующий код:
import selenium
DRIVER_PATH = <ПУТЬ К ВАШЕЙ ПАПКЕ>
wd = webdriver.Chrome(executable_path=DRIVER_PATH)
Чтобы открыть сайт Google, напишите команду wd.get('https://google.com'). Теперь можно отправлять поисковые запросы. Например, мы хотим собрать изображения собак:
search_box = wd.find_element_by_css_selector('input.gLFyf')
search_box.send_keys('Dogs')
Чтобы получить ссылки на изображения, воспользуйтесь функцией fetch_image_urls. Она принимает следующие параметры:
- query — поисковой запрос (в нашем случае — dogs)
- max_links_to_fetch — максимальное количество ссылок, которые вы хотите собрать
- webdriver — используемый драйвер для браузера
Пример кода:
def fetch_image_urls(query:str, max_links_to_fetch:int, wd:webdriver, sleep_between_interactions:int=1):
def scroll_to_end(wd):
wd.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(sleep_between_interactions)
# составляем поисковой запрос
search_url = "https://www.google.com/search?safe=off&site=&tbm=isch&source=hp&q={q}&oq={q}&gs_l=img"
# загружаем страницу
wd.get(search_url.format(q=query))
image_urls = set()
image_count = 0
results_start = 0
while image_count < max_links_to_fetch:
scroll_to_end(wd)
# собираем все полученные результаты
thumbnail_results = wd.find_elements_by_css_selector("img.rg_ic")
number_results = len(thumbnail_results)
print(f"Found: {number_results} search results. Extracting links from {results_start}:{number_results}")
for img in thumbnail_results[results_start:number_results]:
# кликаем по предпросмотрам для получения полных изображений
try:
img.click()
time.sleep(sleep_between_interactions)
except Exception:
continue
# собираем ссылки на изображения
actual_images = wd.find_elements_by_css_selector('img.irc_mi')
for actual_image in actual_images:
if actual_image.get_attribute('src'):
image_urls.add(actual_image.get_attribute('src'))
image_count = len(image_urls)
if len(image_urls) >= max_links_to_fetch:
print(f"Found: {len(image_urls)} image links, done!")
break
else:
print("Found:", len(image_urls), "image links, looking for more ...")
time.sleep(1)
load_more_button = wd.find_element_by_css_selector(".ksb")
if load_more_button:
wd.execute_script("document.querySelector('.ksb').click();")
# двигаемся дальше
results_start = len(thumbnail_results)
return image_urls
Чтобы загрузить полученные картинки, нужно установить библиотеку PIL, которая специально предназначена для работы с изображениями. Сделать это можно через команду pip install Pillow.
За скачивание картинок отвечает функция persist_image. Она загрузит нужные объекты в указанную папку, присвоив каждому из них десятизначный идентификатор.
def persist_image(folder_path:str,url:str):
try:
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR — Could not download {url} — {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(folder_path,hashlib.sha1(image_content).hexdigest()[:10] + '.jpg')
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SUCCESS — saved {url} — as {file_path}")
except Exception as e:
print(f"ERROR — Could not save {url} — {e}")
А функция search_and_download объединяет все эти операции и упрощает работу браузерного драйвера (в данном случае ChromeDriver). Поскольку мы используем его в контексте with, в случае неполадок или ошибки программа просто закроется. Кроме того, search_and_download позволяет вам определить нужное количество картинок. По умолчанию оно установлено на 5, вы можете выбрать любое значение.
def search_and_download(search_term:str,driver_path:str,target_path='./images',number_images=5):
target_folder = os.path.join(target_path,'_'.join(search_term.lower().split(' ')))
if not os.path.exists(target_folder):
os.makedirs(target_folder)
with webdriver.Chrome(executable_path=driver_path) as wd:
res = fetch_image_urls(search_term, number_images, wd=wd, sleep_between_interactions=0.5)
for elem in res:
persist_image(target_folder,elem)
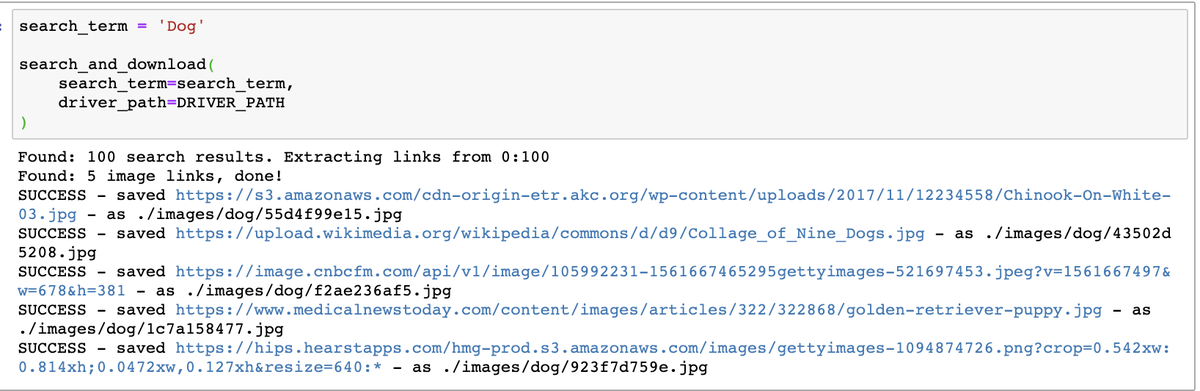
Заработало, мы получили 100 картинок с собаками.
При использовании этого метода помните, что большинство изображений в Интернете защищено авторским правом. Хотя сбор картинок сам по себе не грозит неприятными последствиями, использовать их в коммерческих целях вы не можете.
Этот пример отлично показывает, как легко с помощью Python можно автоматизировать свои задачи и освободить время для более интересных вещей. Освоить этот язык можно всего за несколько недель, так что если вы хотите научиться этому волшебству — приглашаем на курсы по Python для веб-разработки с нуля и анализа данных.