Всем доброго времени суток!)
Сегодня, я собираюсь вместе с вами написать парсер. Думаю парсить будем wordpress и его популярные плагины.
Итак, давайте для начала откроем вордпресс и посмотрим html-код.
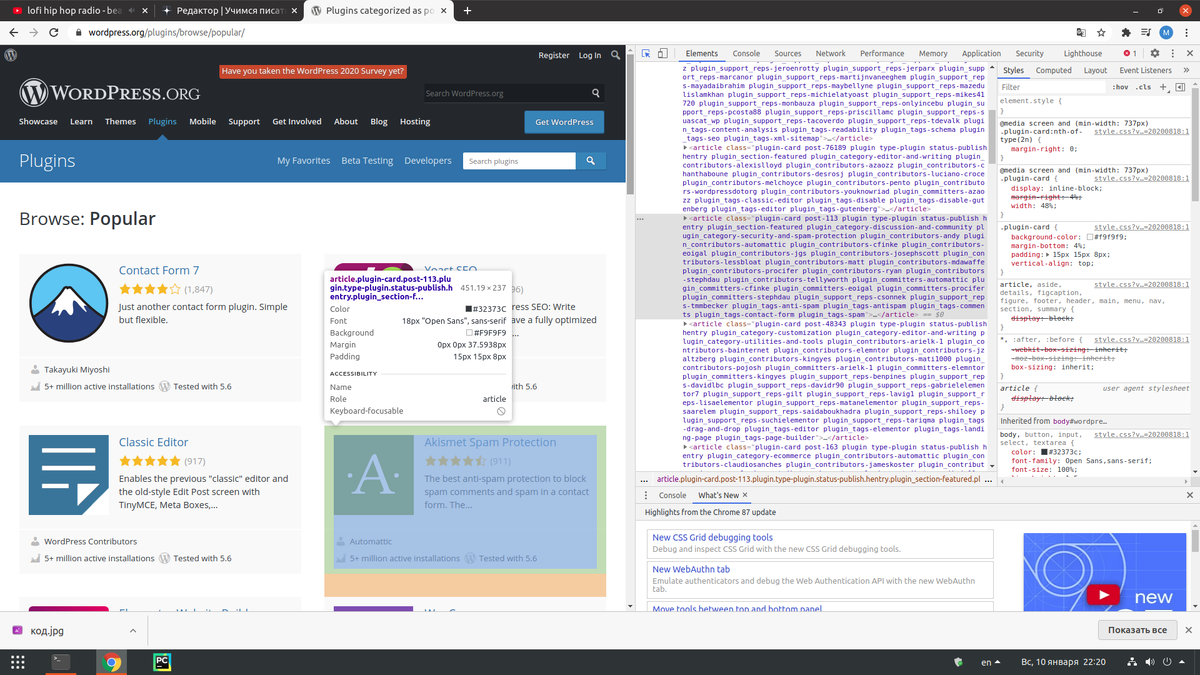
Включаем режим разработчика в браузере и нажимаем Ctrl+Shift+C. После этого наводим наш курсор на плагин. Нам нужна вся карточка этого плагина и как мы видим из html-кода, каждый плагин находится в тегах <article></article>.
Предлагаю написать пару функций с помощью которых мы получим каждый плагин на странице.
Для начала создадим директорию и установим наши библиотеки.
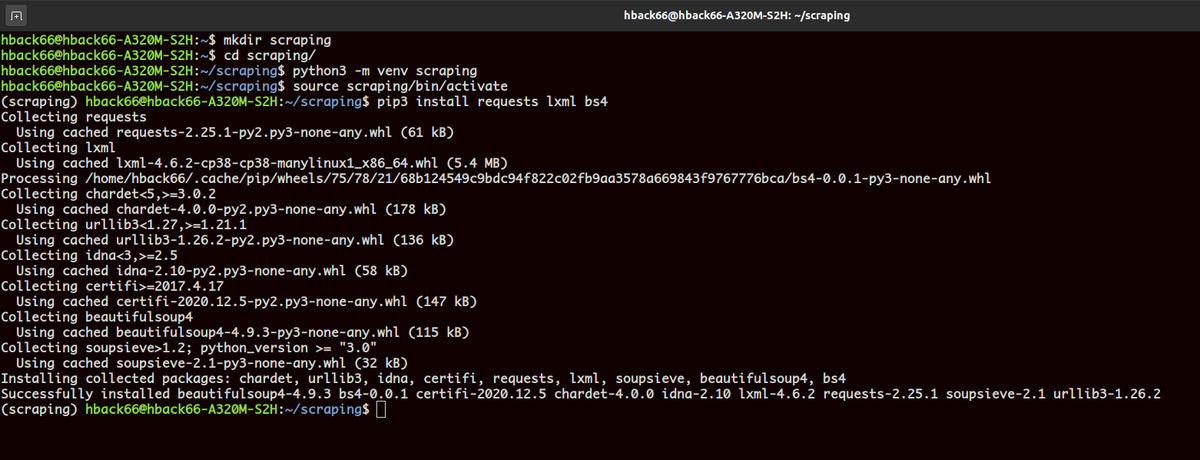
Теперь напишем пару функций.
Функция get_html на вход принимает ссылку нашего сайта, отправляет get запрос на сайт, проверяет есть ли ответ и статус код запроса 200, то мы возвращаем html, если нет принтуем статус код и ссылку.
get_plugins. На вход принимает уже наш html. В функции мы создаем объект супа и с помощью этого объекта мы уже собираем данные с нашего html кода.
Каждый плагин на странице находится в теге <article> и с классом plugin-card.
У нашего объекта супа есть метод find_all, который возвращает список из найденных им элементов, поэтому предлагаю проитерироваться по этому списку и забрать названия плагинов.
Вот такая функция получилась. Забираем название и ссылку. Выполняем скрипт и смотрим на ответ:
Все работает, вам осталось эти данные записать в файл.
Спасибо за внимание!) Не забывайте ставить лайки и подписываться на канал - это очень мотивирует меня писать для вас дальше.