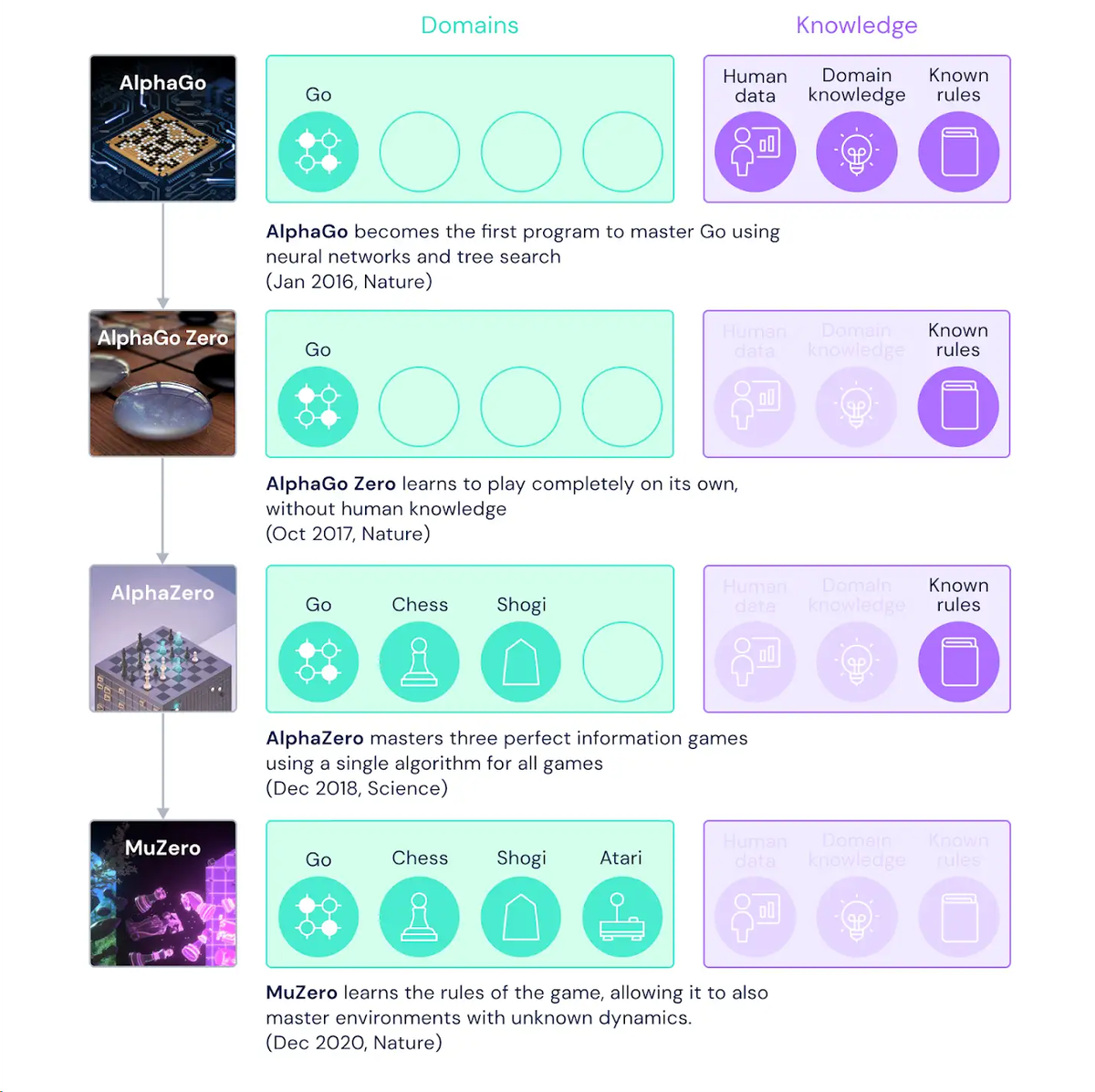
В 2016 году DeepMind представила AlphaGo, первую программу искусственного интеллекта (ИИ) способную одержать победу над человеком в древней игре го. Два года спустя его преемник, AlphaZero, научился с нуля овладевать го, шахматами и сёги (японские шахматы). И вот теперь появился MuZero, который самостоятельно осваивает го, шахматы, сёги и игры Atari благодаря своей способности планировать выигрышные стратегии в неизвестной среде.
Да, ему не надо объяснять правила! В отличие от предшественников, ИИ самостоятельно вырабатывает для себя правила игры. Таким образом, MuZero демонстрирует значительный скачок в возможностях алгоритмов обучения с подкреплением (техники, в которой многоуровневые нейросети позволяют машинам обучаться новым навыкам методом проб и ошибок, получая «вознаграждение» за успех).
Почему это важно
Способность планировать — важная способность человеческого интеллекта, позволяющая решать проблемы и принимать решения о будущем. Например, если мы видим, как собираются тучиа, мы можем предсказать, что пойдет дождь, и решим взять с собой зонтик, прежде чем отправиться в путь. Люди быстро осваивают эту способность и могут использовать её для новых сценариев — способность, которую разработчики хотели перенести в компьютерные алгоритмы.
Исследователи пытались решить эту серьезную проблему, используя два основных подхода: опережающий поиск или планирование на основе моделей. Системы, использующие опережающий поиск, такие как AlphaZero, достигли успеха в классических играх, таких как шашки, шахматы и покер. Но они полагаются на полученную информацию о динамике среды, то есть правила игры или точную симуляцию. Это затрудняет их применение в условиях реального мира, которые трудно свести к простым правилам.
Как работают алгоритмы
Системы, основанные на моделях, стремятся решить эту проблему, изучая точную модель динамики окружающей среды, а затем используя её для планирования. Однако сложность моделирования каждого аспекта среды означает, что эти алгоритмы не могут конкурировать в визуально насыщенных областях, например, играх Atari. До сих пор лучшие результаты на Atari были у систем без моделей, таких как DQN , R2D2 и Agent57. Как следует из названия, безмодельные алгоритмы не используют изученную модель и вместо этого оценивают, какое действие лучше всего предпринять дальше.
MuZero использует другой подход для преодоления ограничений предыдущих подходов. Вместо того, чтобы пытаться смоделировать всю среду, MuZero просто моделирует аспекты, которые важны для процесса принятия решений агентом. В конце концов, знание того, что зонт оставит вас сухим, гораздо полезнее, чем создание модели узора дождевых капель в воздухе.
MuZero моделирует три элемента среды, которые имеют решающее значение для планирования:
- Значение: насколько хорошо текущая позиция?
- Политика: какие действия лучше предпринять?
- Награда: как хорошо было последнее действие?

Все элементы и модели изучаются с помощью нейронной сети, высокую производительность которой обеспечивают облачные технологии с GPU, и это всё, что нужно MuZero, чтобы понимать, что происходит, когда он предпринимает определенные действия, и соответствующим образом планировать их.

Тестирование ИИ
У этого подхода есть еще одно важное преимущество: MuZero может многократно использовать изученную модель для улучшения планирования, а не для сбора новых данных из среды. Например, в тестах игр Atari модель MuZero Reanalyze использовала изученную модель в 90% случаев, чтобы перепланировать то, что должно было быть сделано в прошлых эпизодах для достижения желаемого результата.
Оказалось, что MuZero немного лучше AlphaZero в игре Go, несмотря на то, что за каждый ход выполнялось меньше вычислений. Бот также превзошел R2D2 — ведущий игровой алгоритм Atari — в 42 из 57 игр, протестированных на старой консоли. Более того, он сделал это после того, как выполнил только половину тренировочных шагов.
Чтобы проверить, приносит ли планирование пользу на протяжении всего обучения, разработчики провели серию экспериментов в игре Atari PacMan, используя отдельные обученные экземпляры MuZero. Каждому было разрешено рассмотреть разное количество симуляций планирования на ход, от пяти до 50. Результаты подтвердили, что увеличение объёма планирования для каждого хода позволяет MuZero как учиться быстрее, так и достигать лучших конечных результатов.
Интересно, что когда MuZero было разрешено рассматривать только шесть или семь симуляций за ход (а это число слишком мало, чтобы охватить все доступные действия в PacMan), он всё равно достиг хорошей производительности. Это говорит о том, что MuZero может делать обобщения между действиями и ситуациями, и ему не нужно исчерпывающе перебирать все возможности для эффективного обучения.
Что дальше
Получается, что MuZero способен более эффективно извлекать больше информации из меньшего количества данных. Теперь в DeepMind задумались о практическом применении MuZero. Его предшественник, AlphaZero, уже применялся для решения ряда сложных проблем в химии, квантовой физике и других областях. Сейчас идеи, лежащие в основе мощных алгоритмов обучения и планирования MuZero, могут проложить путь к решению новых задач в робототехнике, также искусственный интеллект можно использовать для разработки виртуальных помощников нового поколения, медицинских и поисково-спасательных технологий.
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
Понравилась статья? Ставьте ЛАЙК 👍, делитесь в социальных сетях и подписывайтесь на канал, чтобы не пропускать новые выпуски! Если у вас есть желание оценить преимущества облачной платформы Cloud4Y, оформите заявку на бесплатный тестовый доступ или позвоните нам +7 (495) 268-04-12.