В мире машинного обучения имеются определенные правила проверки качества моделей, которые нужно знать и применять в зависимости от конкретной ситуации. В этой статье я сосредоточусь на описании наиболее распространенных способов.
Их выбор зависит от количества вычислительных ресурсов, времени и объема данных. Фундаментальным принципом всех является разнос сведений, на которых модель обучается и тестируется. Это делается, чтобы не допустить подстройку к данным (переобучение), характеризующим эффективность, которая в этом случае не будет достоверна.
Однократное разделение на обучающую и тестовую выборки
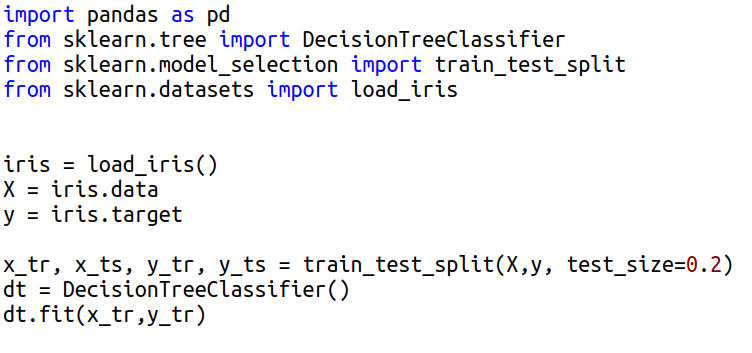
Осуществляется с помощью функции train_test_split из библиотеки scikit-learn, которая получает наблюдения X, предсказываемые метки y и возвращает список, содержащий их разделения на обучающую и тестовую выборки. Также ей можно указать процент данных, который следует сохранить для тестового набора в параметре test_size. Рассмотрим ее работу на примере скрипта, обучающего модель дерева решений (подробнее принцип работы описывал здесь) для предсказания классов цветов ириса по ряду признаков:
Для интереса выведем точность классификатора на тестовой и обучающей выборке:
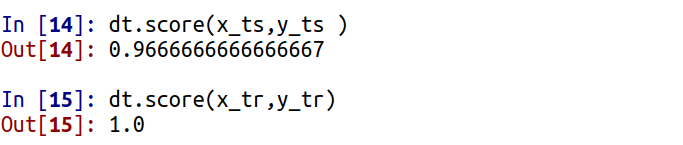
Можно отметить, что ввиду того, что модель знакома с обучающей выборкой, она дает на ней точность 100%, что не отражает реальность и подтверждается иным значением точности на тестовой выборке - почти 97%.
k - кратная перекрестная проверка
Это более затратный и долгий способ тестирования модели, но результаты получаются достовернее, чем в предыдущем. По данному алгоритму набор разбивается на k групп (folds), где (k-1) из них используется для обучения, а k-ая для проверки. И так до тех пор пока каждая группа не побывает тестовой. Отслеживаемая метрика подсчитывается как среднее арифметическое метрик на каждом из k шагов.
Данный способ реализуется разными классами. Базовым является KFold из библиотеки scikit-learn. При k = 4 наши группы формировались бы в соответствии с рисунком:
В качестве входа KFold может принимать количество групп n_splits, а также shuffle, определяющий нужно ли перемешивать данные до разбиения.
Изменим этап тренировки, чтобы использовать данный класс:
вывод следующий:
Обратите внимание на неутешительные результаты. Они обусловлены тем, что данные в выборке сгруппированы так, что всего у нас 3 класса цветков ириса и каждый представлен по 50 раз последовательно (первый от 0 до 49, второй 50-99, третий 100-149). При этом мы разбиваем данные на три группы по 50 в каждой, соответственно, модель обучается предсказывать только 2 класса и не видит ни одного экземпляра из оставшегося. В то же время мы ее тестируем на данных, которых она никогда не видела!
Чтобы исправить ситуацию, достаточно перед разбиением перемешать данные, используя параметр shuffle, который по умолчанию равен False:
Здесь 1, 2 и 0 - первые индексы тестового набора на каждом шаге (ранее были 0,50,100).
Leave One Out
Этот способ аналогичен предыдущему, только в каждом из тестовых наборов участвует только одно наблюдение (к=количеству_наблюдений). Соответственно, он еще более затратный и долгий по времени. Однако при обучении данные практически не теряются (ведь в предыдущем примере убрав 50 наблюдений у нас модель лишилась описания целого класса!).
Реализуется в классе LeaveOneOut:
Leave P Out
Данный способ похож на предыдущий за исключением того, что на каждом шаге в качестве тестового выбирается новый набор из p элементов, а остальные используются для обучения. Соответственно, элементы в тестовых наборах на каждом шаге могут частично повторяться (при p>1):
а вывод:
Стратифицированная перекрестная проверка
Аналогична обычной перекрестной проверке, однако старается поддерживать одинаковое представительство наблюдений из разных классов при разбиениях (чтобы модель видела разные данные и не произошла ситуация, описанная в разделе о KFold). Реализуется классом StratifiedKFold.
а вот вывод сценария:
Многократное разделение на обучающую и тестовую выборки
Аналог обычного разделения на обучающую и тестовую выборки с большим числом таких случайных разбиений. Реализуется классом ShuffleSplit:
вывод получен следующий:
Как можно заметить, в отличие от перекрестной проверки, где тестовые наборы не пересекаются, здесь уже в двух наборах как минимум первый элемент совпал.