
Каждый SEO-специалист знает, что успешное продвижение сайта в поиске невозможно без качественного семантического ядра, включающего в себя по возможности все поисковые запросы (или ключевые слова, маркерные запросы) в нужной ему тематике. Правильно составленное семантическое ядро онлайн – это зеркало спроса на предлагаемые товары и услуги, и фундамент для дальнейшего продвижения. Именно правильная работа над семантикой даёт наибольший эффект при продвижении.
Но что мы понимаем под «качественным семантическим ядром»? Больше ключевых слов – значит лучше? Далеко не всегда. Например, информационные запросы скорее всего бесполезны для интернет-магазина. Оставить только самые частотные запросы – тоже неправильно, т.к. продвинуться по таким запросам сложнее всего. Каково же тогда определение качественной семантики? Т.к. каждый случай продвижения сайта уникален, то будем считать, что качественная семантика для сайта – та, которая на момент её сбора содержит все полезные (и только полезные) для этого сайта запросы.
Давайте остановимся на бесполезных запросах, и на том, как их вычислить. Некоторые из них вполне безобидны, например, для магазина это будут информационные и просто нецелевые запросы, которые легко отфильтровать по стоп-словам (отзывы, скачать, бесплатно, и т.д.).
Читайте также: Семантическая структура сайта
Мусорные запросы
Но есть совсем другой класс бесполезных запросов, который уже представляет реальную опасность – это мусорные запросы. Такие ключевые слова бесполезны вне зависимости от тематики сайта. Что это за запросы?
- Искусственно сгенерированные (иногда руками самих оптимизаторов :) )
- Опечатки и другие ошибки, которые исправляет Поисковая Система
- Ошибочная транслитерация
- Запросы, не допечатанные до конца
- Запросы с нулевой частотностью, вводившиеся всего 1 раз за всю историю Интернета :)
- «Морально устаревшие» запросы, например, «туры в Турцию 2012»
У всех этих запросов есть одна общая черта – их частотность всегда равна нулю, и они никогда не принесут вам трафик! Продвигая такие запросы, вы просто теряете время.
Читайте также: Советы по SEO на Wordpress.
Источники семантики
И от чего же зависит количество полезных и мусорных ключевых слов в семантике? В первую очередь, от источника этой семантики. Сегодня существует множество различных источников семантики, вот самые популярные из них:
- Поисковые Подсказки, также получаемые от самих поисковых систем
- Счётчики Посещаемости
- Базы ключевых слов
- Сервисы анализа конкурентов
Читайте также: Проверка позиций сайтов конкурентов
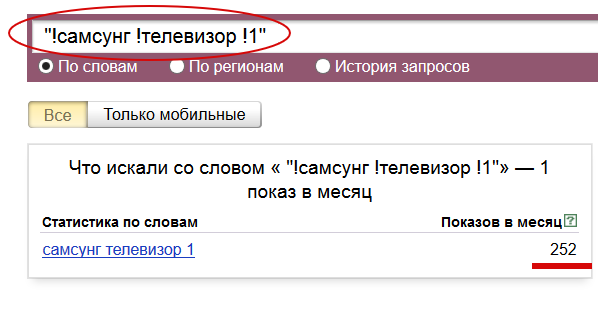
И практически все из них содержат мусорные запросы! «Как же так, даже Вордстат?» – спросите вы. Да, даже собственные сервисы поисковиков, такие как Вордстат, и Подсказки, если «не уметь их готовить», могут отдать вам мусор. Не говоря уже о других источниках. Не верите? Попробуйте ввести в Вордстат: "!самсунг !телевизор !1" – этот запрос есть в левой колонке, и имеет ненулевую частотность. И что же это за телевизор такой? :) А на самом деле, это недопечатанный запрос, скорее всего человек искал телевизор 19 дюймов.
Преимущества семантики в Rush analytics
А теперь сюрприз: Семантика, получаемая при помощи Rush Analytics, мусорных запросов не содержит! Мы «умеем готовить» наши источники семантики, поэтому все мусорные запросы в нашем сервисе заранее отфильтрованы. Но что делать, если у вас уже есть свои ключевики, которые вы получили не из Rush Analytics? Как проверять эти ключевые слова на «мусорность»? Да, можно снять частотность тем же Вордстатом, но у него есть существенные ограничения: высокая стоимость, не учитывается порядок слов в запросе, зависимость от сезона. Например, множество полезных запросов в тематике «туризм» отдаёт частотность 0, если проверять эту частотность в период низкого сезона.
Но выход есть: новый инструмент «Проверка ключевых слов» в Rush Analytics!
Его преимущества:
- Очень строгая проверка (только точный порядок слов и словоформа)
- Высокая скорость (сотни тысяч ключевиков в час)
- Низкая стоимость (всего 1 копейка за ключевик)
Детали алгоритма проверки мы не раскрываем, но можете быть уверены, что наши данные всегда актуальны, т.к. мы используем только динамические данные (в отличие от баз), в том числе и верификацию через Поисковые Системы, например, отлавливаем опечатки и исправления запроса.
Вы просто загружаете в этот инструмент свои ключевые слова, и он в простом и понятном виде рассортирует их по 2 вкладкам: «Хорошие» и «Плохие». Но хватит теории. Давайте уже перейдём к практической аналитике :)
Читайте также: A/B тест рассылки
Тест-драйв в боевых условиях!
Вернёмся к источникам семантики. Сегодня, всё большую популярность получают так называемые «Базы ключевых слов», создатели которых громко заявляют о содержащихся в них миллиардах ключевиков! Немало, не правда ли? Но, как я уже писал выше, любой источник семантики может содержать мусорные запросы. Сразу возникает подозрение: если в этих базах ТАК МНОГО ключей, то не попадает ли туда всякий мусор? Или устаревшие запросы? Будут ли владельцы баз спустя пару лет удалять запросы с 2014 годом, или оставят их, дописав красивую цифру в количестве ключей, которые содержит их база?
Ответы на все эти вопросы способен дать только эксперимент. Мы решили проверить наш новый инструмент в боевых условиях, чтобы узнать, сколько же мусорных (по мнению редакции :) ) запросов содержится в популярных базах ключевиков?
Мы взяли 3 популярные тематики, затем сделали выгрузки по ним из самых популярных баз, и проверили нашим новым инструментом.
Читать статью полностью: Аналитика источников семантики