
Все, кто собирает семантику, сталкивается с проблемой – не целевые (мусорные) слова, которые очень муторно вычищать, чтобы получить финальный список ключевых слов, пригодный для работы.
Мы так же сталкиваемся с этим каждый день и надо сказать, что нам это порядком надоело. Мы решили на корню решить эту проблему раз и навсегда.
Мы автоматизировали этот процесс.
Сегодня мы расскажем о нашей новой разработке, которая с прошлой недели вошла в состав Rush Analytics.
Как обычно чистят семантическое ядро от мусора?
На практике обычно это происходит так: оптимизатор/специалист по контекстной рекламе идет в MS Excel, делает фильтр в столбце с ключевыми словами и поочередно вбивает туда стоп-слова: «бесплатно», «ВК», «вконтакте», «онлайн», «реферат» и прочие. Много стоп слов. И так по кругу долгие часы.
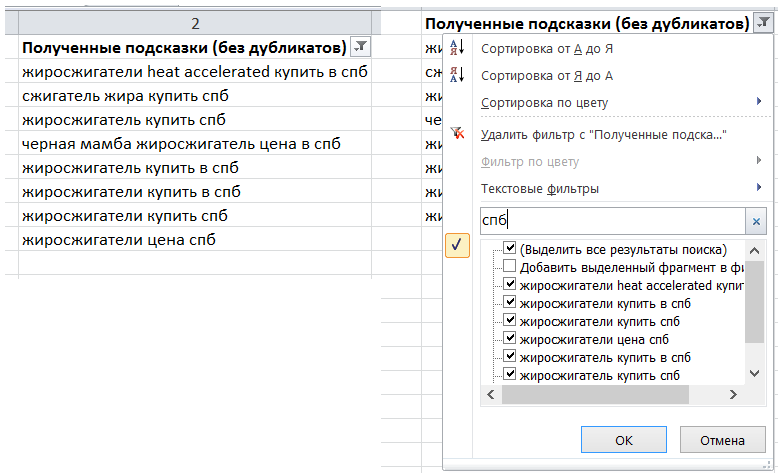
Почему же это такой муторный процесс?
Читайте также: Что такое маркерный запрос
Гео-запросы - главная головная боль любого SEO-специалиста
Да-да у многих сейчас, наверное, вспотели ладошки т.к. вы вспомнили долгие часы очистки запросов вида «…спб», «…екб», «… в казани», «…самара». И когда вроде уже все готово – находятся все новые и новые городки, о которых даже не подозреваешь :)
Мы нашли решение – сделали готовые списки стоп-слов по гео-запросам.
Как это работает? Вам достаточно выбрать свой целевой город и все запросы, в которых содержится гео-указания (названия городов) отличные от целевого города будут автоматически удалены в отдельный список.
Выглядит это так:
Просто выберите свой целевой город.
Важный нюанс: мы заранее добавили в базу все устоявшиеся сокращения городов вида «екб», «спб», «Питер» и т.д. Все словоформы (склонения) городов так же учитываются автоматически.
Все самые популярные стоп-слова всегда под рукой - в 1 клик
Мы так же составили обширные списки популярных мусорных слов по различным тематикам – практически на все случаи жизни – теперь можно в один клик отсеять, например, все ключевые слова с интентом «бесплатно» или «отзывы» или «фотографии и изображения».
Выглядит это так:
Читайте также: Собираем поисковые подсказки Youtube
Полный список тематик и направлений, стоп-слова по которым мы подготовили:
- Халява
Все, что связано со словом "Бесплатно" - Визуализация
Все, что связано с изображениям, видео, фотографии и рисованием - Социальные сети
Список названий популярных соц. сетей - Ремонт
Ремонт, инструменты, поломки, запчасти - Софт
Компьютерные игры, софт, драйвера, ключи - БУ
Все связанное с «бу», старым, бывшим - Самодеятельность
Работа на дому, "своими руками", - некоммерческий мусор - Счет-калькуляция
Стоп-слова по расчетам, калькуляторам, коэффициентам - Юмор-приколы
Юмор, приколы, анекдоты - Порно
Русские и английские стоп-слова по теме эротика, порно, секс - Лечение
Стоп-слова по лечению и самолечению, методологиям и болезням - Транзакции
Стоп-слова по продажам, покупкам, бронированию, заказам - Оптовые
Стоп-слова по опту, рознице, закупкам - Отзывы и смежное
Стоп-слова по отзывам, жалобам, мнениям - Вопросы и инфо запросы
Стоп-слова по вопросам: что, кто, какой, где - Аренда
Стоп-слова по аренде, посуточной аренде, прокату - Крупные интернет магазины
Названия интернет магазинов - Авто (Beta)
Названия марок и моделей автомобилей - Животные (Beta)
Список животных - Женские имена
Большой список женских имен - Районы Москвы
Стоп-слова по районам Москвы - Рецепты еды
Стоп-слова по названиям блюд и рецептам - Цвета
Большой список названий цветов - Материалы (ткань)
Названия тканей - Характеристики
Характеристики предметов (размер, вес, большой, длина…)
Читать статью полностью: Чистим семантическое ядро от мусора в два клика