1 часть, 2 часть, 3 часть, 4 часть , 5 часть...
Предисловие
Перейдём к работе с реальными данными и наконец зайдёмся машинным обучением. В качестве 1 набора данных я выбрал довольно классический "Титаник". В планах рассмотреть на нём как можно больше алгоритмов(пока что исключим из списка алгоритмов нейросети из-за того, что кол-во данных слишком мало и на +-1300 примерах мы не получим внятный результат) и по возможности проанализировать почему некоторые работают хуже, а некоторые лучше.
Анализ данных
Прежде чем работать с данными нам надо посмотреть какие данные мы получили, проанализировать их и по возможности предъобработать.
Импортируем необходимую для прочтения данных библиотеку
import pandas as pd
Посмотрим что в данных для обучения(забыл сказать, что тут у нас все данные уже разделены на тренировочные и тестовые с соответствующим их разделением на "для предсказания" и "для проверки ответа")
titanic_data = pd.read_csv('train.csv')
titanic_data.head(15)
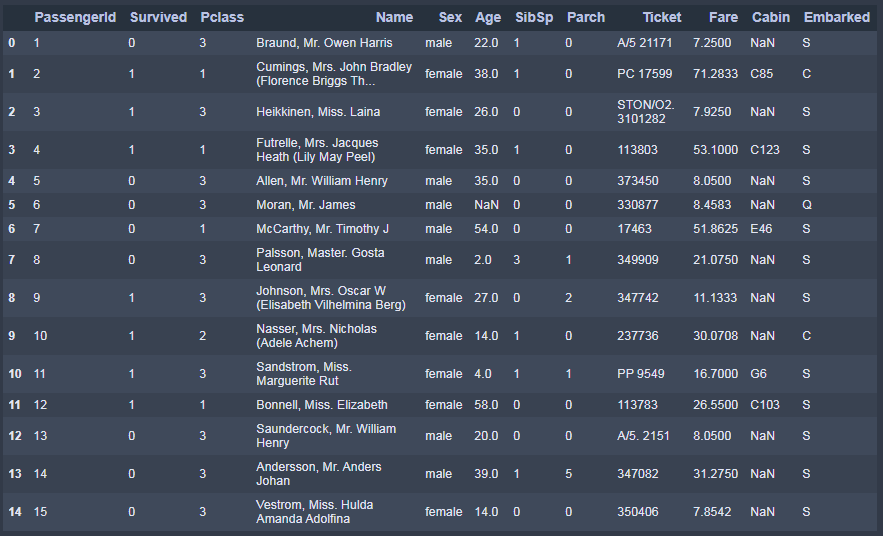
Как мы видим по столбцу "Cabin"(и скорее всего есть и в других, это мы проверим чуть позже) у нас есть пустые значения которые надо будет обработать иначе они будут работе алгоритмов.
Посмотрим данные для проверки и набор ответов.
test = pd.read_csv('test.csv')
test.head(15)
gender_submission = pd.read_csv('gender_submission.csv')
gender_submission.head(15)
Для примера посмотрим что у нас по пустым значениям в titanic_data (тренировочных данных).
titanic_data.isnull().sum()
Как мы в видим пропущенных строк довольно не мало учитывая, что всего в этой таблице 891 строка, но что делать с пустыми значениями мы подумаем позже.
Ну и под конец ради интереса посмотрим как распределился возраст плывущих на Титанике и цена билета.
titanic_data.Age.hist()
titanic_data.Fare.hist()
Как оказывается на подавляющее большинство людей на Титанике были младше 40 лет, при этом они брали своих детей, иначе я объяснить такое обилие детей не могу. Однако на столь прогрессивном на то время корабле было несколько людей преклонного возраста.
И не смотря на мои ожидания, что цена на него будет бешеная оказалось, что подавляющему большинству поездка досталась довольно дёшево(не будем рассматривать изменение курса, оставим эту работу экономистам), хотя нашлись и те/тот/та кому она досталась под 500$ и судя по цене остальных билетов это было целое состояние.
Ну а в дальнейших статьях мы обработаем данные под классификаторы(для начала дерева и леса, а потом посмотрим)).