https://blogs.nvidia.com/blog/2019/08/19/what-is-conversational-ai/
Понимание естественного языка в реальном времени изменит наше взаимодействие с интеллектуальными машинами и приложениями.
Август 19, 2019 от Sid Sharma

Для качественного разговора между человеком и машиной ответы должны быть быстрыми, разумнымии и естественными.
Но до сих пор разработчики нейронных сетей с языковой обработкой, которые обеспечивают речевые приложения реального времени, столкнулись с неудачным компромиссом: будьте быстры, и вы жертвуете качеством ответа; выработайте разумный ответ, и вы будете слишком медленными.
Это потому, что человеческий разговор невероятно сложен. Каждое утверждение основывается на общем контексте и предыдущих взаимодействиях. От шуток до культурных ссылок и словесных игр люди говорят очень нюансированно, не пропуская ни секунды. Каждый ответ следует за последним, почти мгновенно. Друзья ожидают, что скажет другой, прежде чем слова будут произнесены.
Что такое разговорный искусственный интеллект?
Истинный разговорный искусственный интеллект - это голосовой помощник, который может участвовать в диалоге, похожем на человеческий, захватывать контекст и предоставлять разумные ответы. Такие модели ИИ должны быть массовыми и очень комплексными.
Но чем больше модель, тем дольше задержка между вопросом пользователя и ответом ИИ. Разрывы, превышающие две десятых секунды, могут звучать неестественно.
С помощью графических процессоров NVIDIA и библиотек ИИ CUDA-X можно быстро обучить и оптимизировать массовые современные языковые модели для выполнения вывода всего за пару миллисекунд, тысячных долей секунды, что является важным шагом на пути к прекращению компромисса между моделью ИИ, которая быстрее, чем модель, большая и сложная.
Эти достижения помогают разработчикам создавать и развертывать самые передовые нейронные сети и приближают нас к цели достижения действительно диалогового ИИ.
Оптимизированные для графического процессора модели, способные понимать язык, могут быть интегрированы в приложения искусственного интеллекта для таких отраслей, как здравоохранение, розничная торговля и финансовые услуги, предоставляя мощные цифровые голосовые помощники в интеллектуальных колонках и линиях обслуживания клиентов. Эти высококачественные инструменты ИИ для общения позволяют компаниям из разных секторов предоставлять ранее недостижимый стандарт персонализированного обслуживания при взаимодействии с клиентами.
Насколько Быстрым Должен быть Разговорный Искусственный Интеллект?
Типичный разрыв между ответами в естественном разговоре составляет около 200 миллисекунд. Чтобы ИИ воспроизводил взаимодействие, похожее на человеческое, ему, возможно, придется последовательно запустить дюжину или более нейронных сетей как часть многоуровневой задачи — и все это в течение этих 200 миллисекунд или меньше.
Ответ на вопрос включает в себя несколько этапов: преобразование речи пользователя в текст, понимание значения текста, поиск наилучшего ответа для предоставления в контексте и предоставление этого ответа с помощью инструмента преобразования текста в речь. Каждый из этих шагов требует запуска нескольких моделей искусственного интеллекта — поэтому время, необходимое для выполнения каждой отдельной сети, составляет около 10 миллисекунд или меньше.
Если для выполнения каждой модели требуется больше времени, ответ будет слишком вялым, и разговор станет резким и неестественным.
Работая с таким ограниченным бюджетом, разработчики современных инструментов понимания языка должны найти компромисс. Высококачественная, сложная модель может быть использована в качестве чат-бота, где задержка не так важна, как в голосовом интерфейсе. Или разработчики могут полагаться на менее громоздкую модель обработки языка, которая быстрее дает результаты, но не имеет подробных ответов.
Как Будет Звучать Будущий Разговорный ИИ?
Базовые голосовые интерфейсы, такие как алгоритмы телефонного дерева (с такими подсказками, как “Забронировать новый рейс, скажем ‘бронирование’”) являются транзакционными и требуют набора шагов и ответов, которые перемещают пользователей через предварительно запрограммированную очередь. Иногда только человек-агент в конце телефонного дерева может понять нюанс вопроса и разумно решить проблему звонящего.
Голосовые помощники на рынке сегодня делают гораздо больше, но основаны на языковых моделях, которые не так сложны, как могли бы, с миллионами вместо миллиардов параметров. Эти инструменты ИИ могут зависнуть во время разговора, предоставляя ответ типа “позвольте мне найти это для вас”, прежде чем ответить на поставленный вопрос. Или же они отобразят список результатов веб-поиска, а не ответят на запрос разговорным языком.
По-настоящему разговорный ИИ пошел бы дальше. Идеальная модель - это достаточно сложная модель, чтобы точно понимать запросы человека относительно его выписки из банка или результатов медицинского отчета, и достаточно быстрая, чтобы мгновенно отвечать практически на естественном языке.
Приложения для этой технологии могут включать голосового помощника в кабинете врача, который помогает пациенту записаться на прием и последующие анализы крови, или голосового ИИ для розничной торговли, который объясняет разочарованному абоненту, почему отгрузка посылки задерживается, и предлагает кредит магазина.
Спрос на такие передовые инструменты для искусственного интеллекта растет: к 2020 году около 50 процентов поисковых запросов будут проводиться с использованием голоса, а к 2023 году будет использоваться 8 миллиардов цифровых голосовых помощников.
Что Такое BERT?
BERT (Bidirectional Encoder Representations from Transformers) - это большая, требующая большого объема вычислений модель, которая задает современный уровень понимания естественного языка, когда она была выпущена в прошлом году. При тонкой настройке его можно применять к широкому кругу языковых задач, таких как понимание прочитанного, анализ настроений или вопросов и ответов.
Обученный в огромном корпусе из 3,3 миллиарда слов английского текста, BERT работает исключительно хорошо — в некоторых случаях лучше, чем средний человек — для понимания языка. Его сильная сторона заключается в способности обучаться на немаркированных наборах данных и, с минимальными изменениями, распространяться на широкий спектр применений.
Один и тот же BERT может использоваться для понимания нескольких языков и для точной настройки для выполнения определенных задач, таких как перевод, автозаполнение или ранжирование результатов поиска. Эта универсальность делает его популярным выбором для развития сложного понимания естественного языка.
В основе BERT лежит слой Transformer, альтернатива рекуррентным нейронным сетям, в котором применяется метод внимания — разбор предложения путем сосредоточения внимания на наиболее релевантных словах, которые встречаются до и после него.
Например, выражение “За окном есть кран” может описывать птицу или строительную площадку, в зависимости от того, заканчивается ли предложение словами “из каюты на берегу озера” или “из моего кабинета”. Используя метод, известный как двунаправленное или ненаправленное кодирование, языковые модели, такие как BERT, могут использовать контекстные подсказки, чтобы лучше понять, какое значение применимо в каждом случае.
На сегодняшний день ведущие модели языковой обработки в разных доменах основаны на BERT, включая BioBERT (для биомедицинских документов) и SciBERT (для научных публикаций).
Как Технология NVIDIA Оптимизирует Модели на Базе Трансформаторов?
Возможности параллельной обработки и архитектура Tensor Core графических процессоров NVIDIA обеспечивают более высокую пропускную способность и масштабируемость при работе со сложными языковыми моделями — обеспечивая производительность установки записей как для обучения, так и для вывода из BERT.
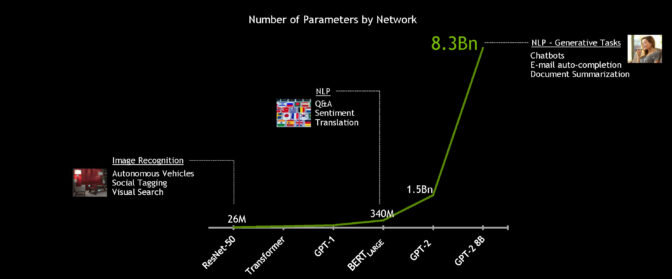
Используя мощную систему NVIDIA DGX SuperPOD, модель BERT-Large с 340-миллионным параметром может быть обучена менее чем за час, по сравнению с обычным временем обучения в несколько дней. Но для разговорного ИИ в режиме реального времени существенное ускорение - вывод.
Разработчики NVIDIA оптимизировали модель BERT-Base с 110 миллионами параметров для вывода с использованием программного обеспечения TensorRT. Работая на графических процессорах NVIDIA T4, модель смогла вычислить ответы всего за 2,2 миллисекунды при тестировании в Наборе Вопросов и Ответов Стэнфорда. Набор данных, известный как SQuAD, является популярным эталоном для оценки способности модели понимать контекст.
Порог задержки для многих приложений реального времени составляет 10 миллисекунд. Даже высоко оптимизированный код процессора приводит к увеличению времени обработки более 40 миллисекунд.
Сокращая время вывода до пары миллисекунд, впервые практично внедрить BERT в производство. И это не останавливается на BERT — те же методы можно использовать для ускорения других больших моделей на естественном языке на основе Transformer, таких как GPT-2, XLNet и RoBERTa.
Чтобы достичь цели действительно разговорного ИИ, языковые модели со временем расширяются. Будущие модели будут во много раз больше, чем используемые сегодня, поэтому NVIDIA создала и открыла для себя крупнейший ИИ на базе трансформаторов: GPT-2 8B, модель обработки языка с 8,3 млрд. Параметров, которая в 24 раза больше, чем BERT-Large.
Дополнительную информацию об обучении BERT на графических процессорах, оптимизации BERT для вывода и других проектах по обработке естественного языка можно найти в блоге разработчиков NVIDIA.