Американские ученые из Массачусетского технологического института представили нейросеть Speech2Face, которая может воссоздавать по спектрограмме речи человека примерное изображение его лица.

По голосу человека можно с разной точностью определить некоторые его особенности: легко можно определить пол, чуть сложнее (но все равно возможно) — возраст, а наличие акцента дает общее представление о национальности. В результате этого можно примерно представить, как выглядит человек, но это представление не будет достаточно точным.
Нейросеть Speech2Face обучена на нескольких миллионах видео с голосом пользователей. Каждое видео разделено на дорожку аудио и видео. Сам алгоритм разделен на несколько частей: одна из них использует все уникальные особенности лица из видеодорожки для создания снимка лица человека в анфас, другая пытается воссоздать из аудиодорожки ролика спектрограмму речи и смотрит, как выглядит анфас человека, который говорит на оригинальном видео.
В методологии нейросети изображение человека и голос делятся на три демографических показателя — пол, возраст и расу. Во время тестирования ученым пока не до конца удалось научить нейросеть восстановить внешность человека на основе голоса. Искусственный интеллект всегда может определить пол, а также чаще всего угадывает людей с азиатской и европеоидной внешностью. Однако пока Speech2Face не может точно определить возраст даже с разницей в десять лет.
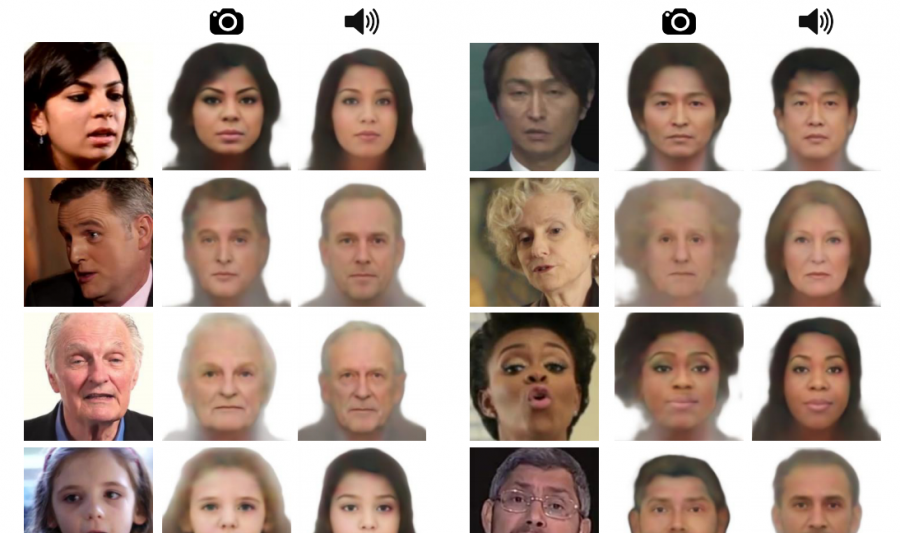
Исследователи отметили, что целью их работы не было точное восстановление внешности человека по его голосу; сосредоточились они именно на выделении и точности некоторых важных параметров: пола, возраста и этнической принадлежности. Именно поэтому точно показать по голосу, как выглядит человек, пока что нельзя: при этом определенных параметров хватит для того, чтобы создавать, к примеру, анимационные аватары человека по его голосу. Также ученые отмечают, что их работа носит также исследовательскую пользу: генерация целых лиц на основе голоса поможет лучше изучить корреляцию с внешностью.