
Статья подготовлена для студентов курса «Data Engineer» в образовательном проекте OTUS.
Рано или поздно вы столкнётесь с моментом, когда pipeline’ы начнут разваливаться, появятся ужасные bottleneck’и, пользователи начнут жаловаться на медленную работу, а витрины для CEO не будут рассчитаны к 9.00 утра. И лучше быть готовым к этому моменту.
За драгоценные ресурсы в высоконагруженных решениях соревнуются все:
• ETL-процессы;
• BI-инструменты;
• Data scientists;
• бизнес-пользователи.
Приоритетной задачей Инженеров Данных становится организация оптимального хранения, вычислений и поставок данных конечным потребителям.
Предлагаю Mindmap основных факторов, которые нужно принять во внимание для Fine Tuning вашего Хранилища.
Организация мониторинга
Умеем хранить историю запросов и можем понять, какие запросы и участки pipelines работают хуже всего (медленнее, с наибольшим потреблением ресурсов).
Бизнес-смысл
Убеждаемся, что запрос точно выполняет ту логику, для которой он реализован.
План исполнения запроса
Умеем построить Execution Plan и трактовать его. Обращаем внимание на ключевые слова желательного и нежелательного воздействия.
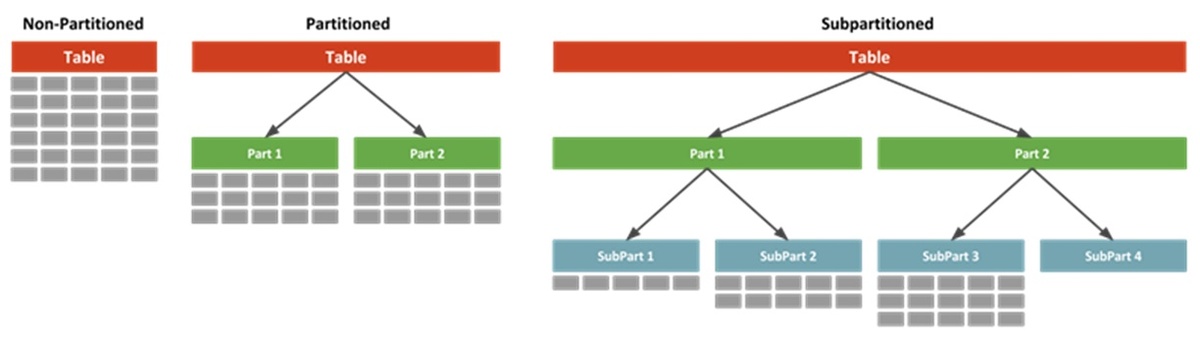
Партиционирование + Сегментирование
Делим большие таблицы на кусочки по горизонтали и вертикали. Читаем только необходимые части данных.
Фильтры
Читаем только нужные нам данные. Используем фильтры в запросе (WHERE) и условиях соединения (JOIN) с целью исключения повторяющихся значений и/или ненужных избыточных объёмов данных. Вы уже можете сказать, что не так с этим запросом:
Статистики
Следим за наличием и актуальностью статистик — важнейших показателей, на основании которых оптимизатор строит план запроса. Включает: количество строк, уникальных значений, селективность, гистограммы распределения.
Оптимизируем код
Используем подходящие алгоритмы для конкретных задач. Переписываем структуру запроса:
• используем CTE, Derived tables;
• JOIN with OR => UNION ALL ;
• DISTINCT <-> GROUP BY;
• IN / NOT IN <-> EXISTS / NOT EXISTS.
Декомпозиция
Разбиваем сложный запрос на несколько мелких и более простых шагов-вычислений.
Песочница для опытов
Используем песочницы и временные таблицы для тестирования производительности и алгоритмов.
Помощь коллег
Последнее по порядку, но не по важности. Советуйтесь с коллегами:
• они могли уже решать подобные задачи;
• в процессе обсуждения рождаются идеи и решения.
В рамках курса «Data Engineer» мы:
• подробно остановимся на каждом из факторов;
• закрепим знания в проектной работе;
• рассмотрим Case Studies: примеры задач, проблем и способы их решения.
Остались вопросы? Пишите их в комментариях!