Сегодня мы рассмотрим модель Трансформатора, которая использует внимание для повышения скорости, применяемой для обучения моделей. Трансформаторы превосходят модель нейронного машинного перевода Google в решении конкретных задач. Это, на самом деле, рекомендация Google Cloud в качестве эталонной модели для их приложения TPU. Итак, давайте рассмотрим то, как функционирует эта модель.
Впервые Трансформатор был предложен в статье «Attention is All You Need». Его реализация на TensorFlow доступна как часть пакета Tensor2Tensor. Гарвардская группа обработки естественного языка разработала руководство, которое аннотирует реализацию на PyTorch. В этой статье мы упростим вещи и последовательно представим концепции, чтобы облегчить понимание людям, которые не имеют особых технических знаний.
Взгляд высокого уровня
Рассмотрим модель как единый чёрный ящик. Приложение машинного перевода будет принимать предложение на одном языке и выводить его вариацию на другом языке.

Вот, взгляните на изображение. На нём видно компонент кодирования, декодирования и связи между ними.
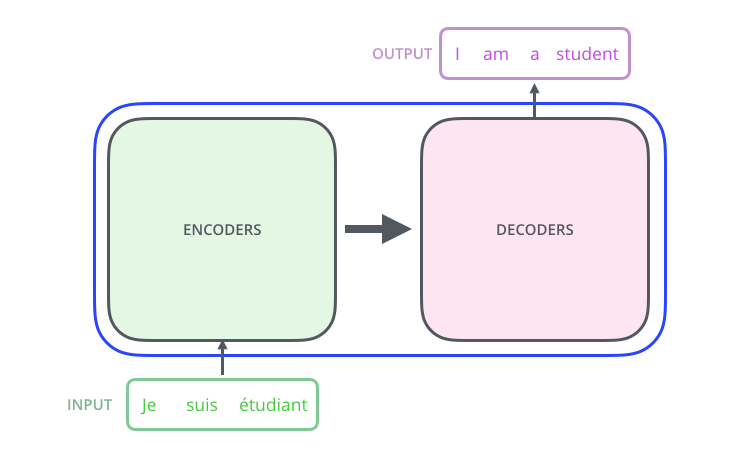
Компонент кодирования — это набор кодеров (на картинке шесть из них расположены друг над другом). Компонент декодирования — это стек декодеров с одинаковым номером.
Все кодировщики абсолютно идентичны по структуре (но у них нет общего веса).
Каждый из кодировщиков разбит на два подслоя:
Для начала входные данные кодировщика проходят через слой self-attention — уровень, где кодировщик может просмотреть другие слова во входном предложении при кодировании конкретного слова. Позже мы также рассмотрим и этот уровень.
Выходные данные со слоя self-attention поступают в нейронную сеть прямого распространения. Точно такая же прямая сеть независимо используется в отношении каждой из позиций.
У декодера тоже есть оба этих слоя. Но между ними находится слой Encoder-Decoder Attention, который позволяет декодеру сконцентрироваться на соответствующих частях входного предложения (аналогично тому, что внимание делает в моделях seq2seq).
Ввод тензоров в изображение
Теперь, когда мы ознакомились с основными компонентами модели, давайте начнём рассматривать различные векторы и тензоры, их перемещение между компонентами, и превратим входные данные в обученной модели в выходные.
Как и в случае с НЛМ, следует начинать с преобразования каждого входного слова в вектор с применением алгоритма встраивания.
Встраивание происходит только в самом нижнем кодере. Абстракция, являющаяся общей для всех кодировщиков, заключается в том, что они получают список векторов, которые обладают размером 512. В нижнем кодировщике это будет ввод слов, но в других — это вывод кодера, который находится непосредственно ниже. Размер этого списка представляет из себя гиперпараметр, который можно установить. В основном значением этого гиперпараметра является длина самого длинного предложения в обучающем наборе данных.
После встраивания слов во входную последовательность, каждое из них проходит через каждый из двух уровней кодировщика.
Тут мы начинаем наблюдать ключевое свойство Трансформатора, заключающееся в том, что слово в каждом из путей течёт через собственный путь в кодере. Между этими путями в слое self-attention наблюдается зависимость. Слой прямого распространения, однако, не обладает такими зависимостями, и, таким образом, различные пути могут выполняться параллельно, проходя через слой прямого распространения.
Сейчас мы переключим пример на более короткое предложение и взглянем, что будет происходить на каждом из подуровней кодера.
Теперь мы кодируем!
Как мы уже упоминали — кодер получает список всех векторов в качестве входных данных. Он обрабатывает этот список, после чего передаёт их на уровень self-attention, затем в нейронную сеть прямого распространения, после чего выходные данные отправляются навверх следующему кодеру.
Слой Self-Attention на высоком уровне
Не ведитесь на то, что я бросаюсь здесь словом «self-attention» так, будто это концепция, с которой каждый должен быть знаком. Я лично никогда с ней сталкивался, пока не ознакомился с упомянутой работой «Attention is All You Need». Итак, давайте разбираться, каким образом это работает.
Допустим, что следующее предложение является входными данными:
Животное не переходило улицу, потому что оно слишком устало.
Что означает «оно» (в оригинале: «it» — может относиться как к животному, так и к улице) в этом предложении? Это местоимение использовано в отношении к улице или к животному? Это довольно простой вопрос для человека, но не совсем простой для машины.
Когда модель обрабатывает слово «оно», слой self-attention позволяет ей ассоциировать слово «оно» со словом «животное».
По мере того как модель обрабатывает слова (каждую позицию во входной последовательности), слой sefl-attention позволяет ей просматривать другие позиции во входной последовательности для получения подсказок, которые могут привести к лучшей кодировке этого слова.
При условии, что вы знакомы с рекуррентными нейронными сетями, задумайтесь о том, как поддержание их скрытого состояния позволяет им включать в своё представление предыдущие слова (векторы), которые она обработала, с теми, что уже были обработаны ещё ранее. Слой Self-Attention — это метод, который трансформатор использует, чтобы применить понимание других соответствующих слов, при обработке текущего.
Посмотрите Tensor2Tensor notebook, там вы сможете загрузить модель трансформатора и изучить её в визуализированном виде.