Self-attention в деталях
Для начала следует рассмотреть то, как вычислить self-attention при помощи векторов. После мы перейдём к реализации с применением матриц.
Первым шагом в вычислении self-attention является создание трёх векторов из каждого входного вектора кодера (в этом случае из каждого слова). Поэтому для каждого слова мы создаем вектор запроса, вектор ключа и вектор значения. Эти векторы создаются при помощи умножения вложения на три матрицы, которые были обучены нами.
Стоит обратить внимание на то, что эти новые векторы меньше по размеру, чем вектор вложения. Их размерность достигает 64, в то время как векторы ввода и вывода кодера имеют размерность в 512. Они не должны быть меньше, это выбор архитектуры для того, чтобы сделать вычисление многоголового внимания постоянным.
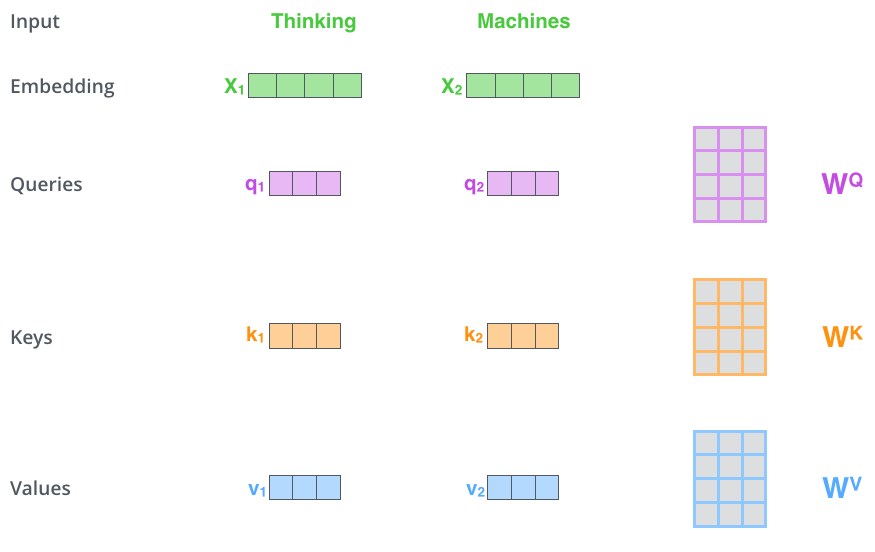
Умножение X1 на весовую матрицу WQ создает Q1, который представляет из себя вектор запроса, связанный с этим словом. В итоге мы создаём «запрос», «ключ» и «значение» проекции каждого слова во входном предложении.
Что такое векторы «запрос», «ключ» и «значение»
По сути, это абстракции, которые полезны для того, чтобы вести расчёты и размышления о самопознании. Как только вы начнете читать, каким образом рассчитывается внимание, вы узнаете почти всё, что вам нужно знать о роли каждого из этих векторов.
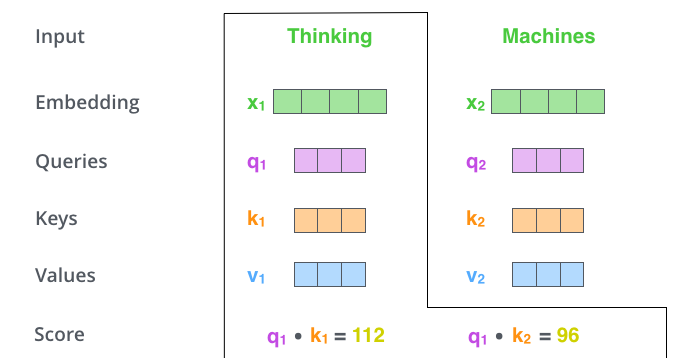
Второй шаг в вычислении self-attention — это подсчёт баллов. Предположим, что мы вычисляем self-attention для первого слова. В текущем примере — это слово «мышление». Нам нужно забить каждое слово входного предложения против этого слова. Оценка определяет, как много внимания следует уделять другим частям входного предложения, когда мы кодируем слово в определённой позиции.
Чтобы рассчитать оценку нужно взять точечное произведение вектора запроса с ключевым вектором соответствующего слова, которое мы забиваем. Итак, если мы обрабатываем self-attention для слова из позиции № 1, то первичная оценка — это точечное произведение q1 и k1. Вторым же результатом будет скалярное произведение q1 и k2.
Третий и четвёртый шаг — это деление баллов на 8 (квадратный корень из размерности ключевых векторов). Таким образом будут достигнуты более стабильные градиенты. Там можно обнаружить другие значения, а затем передать результат через операцию softmax. Именно он нормализует баллы, поэтому они все положительные и складываются в 1.
Оценка softmax определяет то, как будет выражено каждое слово из текущей позиции. Очевидно, что слово на этой позиции получит самый высокий балл в softmax, но иногда следует обратить внимание на другое слово, которое относится к текущему слову.
Теперь нужно умножить каждый вектор значений на оценку softmax (при подготовке к их суммированию). Логика здесь состоит в том, чтобы сохранить нетронутыми значения слов, на которых мы должны сосредоточиться и заглушить слова, которые никак не относятся к делу. Их можно умножать на малые числа.
Шестой шаг — это суммирование векторов взвешенных значений. Это производит выход слоя self-attention в этой позиции.
На этом расчёт self-attention завершается. Результирующий вектор — это тот, который мы можем отправить в нейронную сеть. Но в реальной реализации этот расчет выполняется в матричной форме для более быстрой обработки. Итак, давайте взглянем на это снова, когда мы увидели интуицию расчета на уровне слова.
Расчёт матрицы self-attention
Первый шаг — это вычисление матриц запроса, ключа и значения. Мы делаем это пакуя наши входные данные в матрицу X и умножаем её на матрицу веса, которую мы обучили (WQ, WK и WV).
Каждая строка в матрице X соответствует слову во входном предложении. Мы снова видим разницу в размере вектора вложения (512 или 4 контейнера на рисунке) и векторов q/k/v (64 или 3 контейнера на рисунке).
Наконец, так как мы имеем дело с матрицами, мы можем сконденсировать шаги 2-6 в одной формуле, чтобы вычислить выходы слоя self-attention.
Монстр с кучей голов
В документе дополнительно уточняется уровень self-attention при помощи добавления механизма, который называется многоголовым вниманием. Это значительно улучшает производительность слоя внимания двумя способами:
- Расширение возможности модели фокусирования на разных позициях.
- Это даёт слою внимания несколько подпространств представления. Как мы увидим далее, с многоголовым вниманием у нас есть не только один, но и несколько наборов матриц веса запроса, ключа, значения. Трансформатор применяет 8 голов внимания, поэтому мы получаем 8 наборов для каждого кодера, декодера. Каждый из этих наборов инициализируется совершенно случайно. Затем, после обучения, каждый набор используется для проецирования входных вложений (или векторов из нижних кодеров/декодеров) в другое подпространство представления.
Многоголовое внимание поддерживает отдельные матрицы веса Q/K/V для каждой головы, что приводит к различным матрицам Q/K/V. Как и раньше, мы умножаем X на матрицы WQ/WK/WV для того, чтобы получить матрицы Q/K/V.
Если мы произведем тот же расчёт self-attention, который описан выше, всего восемь раз с разными весовыми матрицами, то мы сможем получить восемь различных матриц Z.
Таким образом мы получаем небольшой вызов. Слой прямой передачи не ожидает восемь матриц, он ожидает одну матрицу. Поэтому нам нужен способ, который позволит сжать эти восемь матриц в единую матрицу.
Для этого нужно объединить матрицы и умножить их на матрицу WO.
Взгляните на все матрицы в одном визуальном образе.
Теперь давайте вернемся к нашему примеру, где разные головы внимания фокусируются, когда мы кодируем слово «оно» в нашем примере.
Когда мы кодируем слово «оно», одна голова внимания больше всего фокусируется на слове «животное», а другая на «усталости» — в некотором смысле, представление модели слова «оно» в некоторых представлениях относится, как к «животное», так и к «усталости».
Но если добавить все головы внимания к общей картине, то интерпретировать станет ещё сложнее.