Есть такая штука tidy data, а по русски - опрятные данные, это такие рекомендации что делать и что не делать при набивке данных, чтобы потом не было проблем.

Так вот, датасет без ошибок в наборе данных скорее исключение, чем правило (Wickham, 2014).
Для того, чтобы избежать этого правила нужно придерживаться других простых правил:
НЕ обозначать заголовки столбцов значениями, а обозначать именами переменных
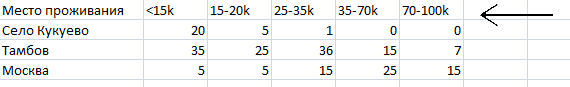
НЕ ставить переменные в строки, а только в столбцы
НЕ создавать объединенные ячейки
НЕ создавать в одном столбце несколько переменных
НЕ забывать одинаково обозначать пропущенные значения. Лучше как все - NA (означает not available или not applicable или no answer - недоступно)
Еще рекомендуется совокупность наблюдений (observation unit) не множить на сущности, и вносить в одну таблицу, соответственно, несколько совокупностей наблюдений вносить в разные таблицы, а не в одну, но это уже по контексту исследования.
Wickham, H. 2014. Tidy data. Journal of Statistical Software, 59 (10), 1-23.
Если понравилась статья - ставьте лайк и подписывайтесь на канал!