Итак, мы уже изучили историю развития Искусственного Интеллекта, парадигмы и подходы к его построению, мифы и факты о нём и даже немного прикоснулись к философии сознания и нейрофизиологии. Сегодня мы продолжаем и начинаем изучать методы и технологии Искусственного Интеллекта. Это прекрасно.
Наша сегодняшняя тема — обработка естественного языка. Естественный язык, то есть такой, который возник в традиционном человеческом обществе, считается прерогативой человека, и его понимание очень сложно реализовать в рамках алгоритмической вычислительной парадигмы. И поэтому обработка естественного языка — это технология Искусственного Интеллекта. К тому же так завещал и сам Алан Тьюринг.

В общем, обработка естественного языка — это довольно большой раздел Искусственного Интеллекта, лежащий на пересечении интересов математики, лингвистики и прикладных инженерных наук. Основная задача заключается в возможности интеллектуальной системы осуществлять анализ и синтез фраз на естественном языке для общения с человеком.
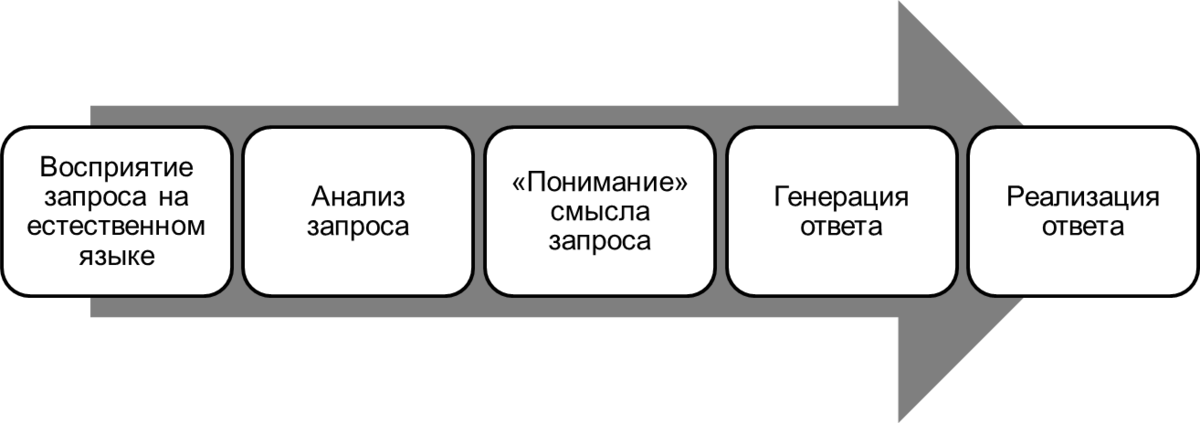
Процесс обработки естественного языка можно представить в виде диаграммы, состоящей из следующих шагов: восприятие запроса на естественном языке, анализ запроса, «понимание» смысла запроса, генерация ответа, реализация ответа.
Интеллектуальная система взаимодействует со своим окружением при помощи естественного языка. Как же происходит коммуникативный акт? Его можно описать следующим образом.
Окружающая среда формирует для интеллектуальной системы сообщение на естественном языке. Это может быть фраза, высказанная голосом и принятая сенсорами системы в виде акустических волн. Это может быть записанная на бумаге письменным курсивом фраза и переданная в систему уже в виде матрицы пикселей. А также это может быть и фраза, напечатанная на клавиатуре, и тогда она непосредственно передаётся в систему.
Любой вариант входной естественно-языковой фразы попадает с сенсора на первичный обработчик, который и осуществляет процесс восприятия запроса на естественном языке. Фактически задачей этого этапа является перевод фразы из входного формата в формальное представление в виде последовательности символов — букв, слов, предложений. И это чисто инженерная задача (хотя, конечно же, она также часто решается методами Искусственного Интеллекта; в частности нейросетевые модели в этой задачи получили самое широкое распространение и применение).
Далее формализованное сообщение попадает в лингвистический процессор, где осуществляется анализ сообщения для выявления его смысла в контексте коммуникативного акта.
Лингвистический процессор сам по себе является довольно сложной системой, состоящей из последовательно соединённых блоков и использующей многостороннюю лингвистическую информацию и информацию об объективной реальности. Лингвистический процессор позволяет на основе входной фразы получить варианты дальнейших действий интеллектуальной системы, в состав которой он входит.
Задачами лингвистического процессора являются: выявление и исправление ошибок во входной фразе, её токенизация, морфологический анализ каждого токена, синтаксический и семантический анализ всего сообщения. Предназначением же лингвистического процессора в рамках использующей его интеллектуальной системы является преобразование формализованной входной фразы в некоторый внутренний язык представления смысла, который система может перевести в последовательность своих поведенческих актов.
Проблема заключается в том, что естественный язык и общение на нём использует очень много неопределённостей, неоднозначностей, умолчаний и других подобных факторов. Даже человеческий естественный интеллект не всегда может правильно распознать смысл обращённой к нему фразы. Человеку в этом отношении помогают контекст беседы и общие знаний об окружающей реальности.
То же самое должна иметь и интеллектуальная система — в её базе знаний должно быть достаточно информации о том, как устроен окружающий мир (как минимум, в части той проблемной области, в которой ведётся разговор), и при этом система должна владеть контекстом беседы. Более того, интеллектуальная система также должна производить и так называемый прагматический анализ, то есть изучать взаимоотношение и взаимодействие входной коммуникационной информации по отношению к самой себе и своему состоянию.
Все это позволяет выбрать из полученных на выходе лингвистического процессора вариантов смысла один — именно тот, который подразумевался визави. На основании выбранного варианта смысла входной фразы интеллектуальная система осуществляет поведенческий акт, который на выходе из подсистемы «понимания» смысла запроса имеет вид формального описания того, что необходимо выполнить.
Следующий шаг заключается в генерации ответа на естественном языке. Этот шаг не является необходимым для интеллектуальных систем, от которых не ожидается ответа на запросы, но такие классы систем как вопрос-ответные системы, чат-боты или иные системы с использованием общения с пользователем на естественном языке должны осуществлять этот этап работы. В любом случае в состав методов обработки естественного языка входят алгоритмы синтеза текста, но они намного проще, чем алгоритмы анализа. Перевод поведенческого акта системы с внутреннего языка представления смысла на естественный может осуществляться по шаблонам или по достаточно простым правилам генерации.
Наконец, последним шагом опять осуществляется в целом инженерная задача по переводу полученного естественно-языкового ответа в ту форму представления, которая доступна визави. Например, если общение осуществляется посредством голоса, то интеллектуальная система должна сгенерировать звуковое соответствие своего ответа, то есть как бы прочитать то, что написано. Ответ может передаваться в виде радиоволн или ещё как-то. Чаще всего сгенерированный ответ в виде строки непосредственно передаётся в канал, при помощи которого происходит общение.
В целом так выглядит схема универсального алгоритма обработки естественного языка. К сожалению, сегодня пока ещё нет полноценных реализаций этой схемы, так как общая сложность естественного языка всё ещё недоступна для охвата программными средствами.
Тем не менее, разработки и дальнейшие исследования ведутся в следующих направлениях: символьная обработка на основе формальных грамматик, статистическая обработка, нейросетевая обработка с поиском и сопоставлением в пространствах подобия.
Во всех этих направлениях достигнуты определённые успехи, особенно в части анализа ограниченного подмножества языка с облегчённой грамматикой и ограниченным лексическим составом (так называемая «деловая проза»). Тем не менее, остаётся много открытых вопросов и белых пятен. В частности, несмотря на то, что теория формальных грамматик для полноценного символьного описания языка проработана очень детально, сами формальные грамматики для естественных языков не построены в полном объёме.
Статистическая обработка больших корпусов текстов не может считаться полноценным методом обработки естественного языка, так как в расчёт не принимается семантическая сторона высказываний, хотя с семантикой отдельных слов иногда получается справляться. Вместе с тем результаты статистической обработки полезны как при построении формальных грамматик, так и при использовании искусственных нейронных сетей. Последние получили серьёзное применение в распознавании естественно-языковых запросов и генерации таких же ответов. Сегодня это одна из самых развивающихся областей Искусственного Интеллекта.
Обработка естественного языка традиционно используется для осуществления машинного перевода, для использования неформальных запросов к банкам данных и поиску в них, а также для организации простых интерфейсов между человеком и интеллектуальными системами. Последнее направление используется как для электронных помощников, так и в более узконаправленных решениях — экспертных системах и системах поддержки принятия решений.
Что ж, мы изучили основы обработки естественного языка, рассмотрев общий цикл работы процедуры. На следующем занятии мы продолжим эту тему. Ну а теперь всё.