Привет! Сегодня ко мне пришла интересная задача, решением которой я хочу поделиться с вами.
Суть: Русскоязычный сайт должен стать мультиязычным, и поэтому, в исходниках (CSS, JS, PHP, HTML) нужно найти все русские слова и собрать всю информацию, для дальнейшей обработки, в таблицу, в формате "название документа->номер строки->слово (предложение) на русском языке. Вот как эти слова выглядят в файлах:
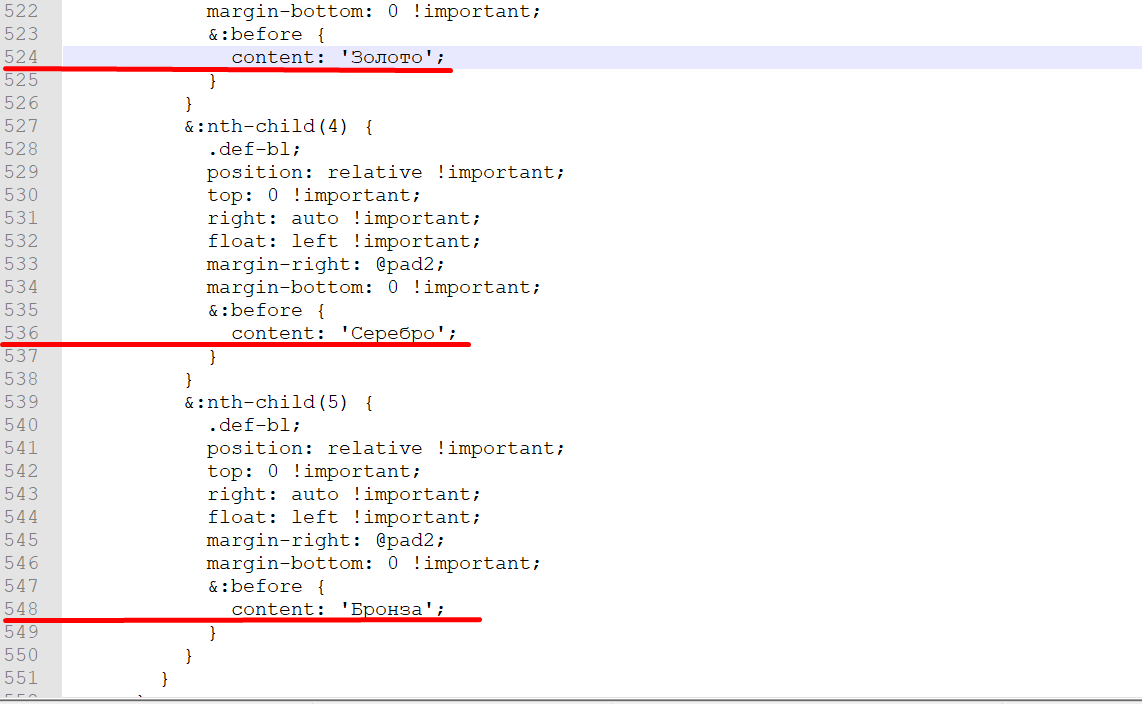
На помощь в решении задачи пришел старый-добрый Notepadd++. В этой программе есть замечательная возможность поиска по файлам, которой я и воспользовался.
Открываем диалоговое окно поиска, выбираем поиск по файлам и отмечаем в "Режиме поиска" регулярные выражения.
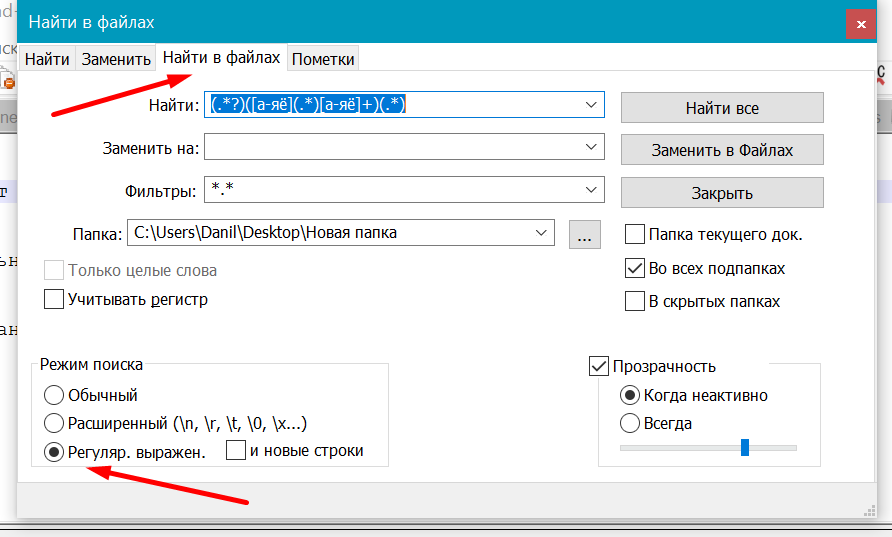
В поле найти вводим такую конструкцию: ([а-яё](.*)[а-яё]+) и выбираем папку, в которой находятся файлы для обработки. Жмем найти все. После завершения поиска получаем все строки с русскими словами во всех файлах.
Выделяем полученный результат и копируем его в новое окно Notepad++. Первый этап завершен, но пока полученные результаты далеки от совершенства.
В первую очередь очистим информацию от знаков табуляции, чтобы они нам не помешали, когда мы будем использовать полученную информацию в таблице.
После удаление знаков табуляции, опять откроем диалоговое окно поиска Notepa++ и перейдем во вкладку "Заменить". В поле поиска используем конструкцию "Line (.*?):", а в поле "Заменить на" "Строка $1 " (кавычки в конструкциях не используем). Жмем заменить все.
Результат:
Выделяем все, копируем и вставляем в новую электронную таблицу. В таблице выделяем столбец со словами, копируем и вставляем информацию в чистое окно Notepad++. Выделяем код в Notepad++, зажимаем на клавиатуре кнопку Shift и нажимаем кнопку Tab несколько раз пока не избавимся вот от таких пробелов.
В моем случае нужно было оставить в документе только те строки, которые относились непосредственно к выводу информации в пользовательскую часть сайта, поэтому мне пришлось избавиться от строк-комментариев необходимых для разработчика. Если перед вами такой задачи не стоит, то после удаления лишних пробелов в начале строки останется произвести замену по регулярному выражению конструкции "(.*?)([а-яё](.*)[а-яё]+)(.*)" на "$2", чтобы получить русские слова без лишних знаков, которые его окружали.