Недавно Гугл представил новый фреймворк Lingvo:
https://medium.com/tensorflow/lingvo-a-tensorflow-framework-for-sequence-modeling-8b1d6ffba5bb
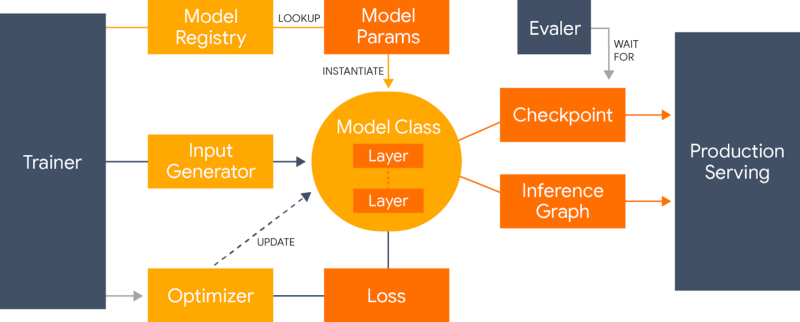
Как следует из названия, в основном фреймворк предназначен для использования в NLP-задачах. Lingvo помогает стандартизовать исследования в этой области: создавать переиспользуемые компоненты, делать результаты исследований воспроизводимыми. Такой докер для NLP.
В рамках фреймворка так же зарелизили GPipe - библиотеку для распределенного обучения огромных моделей на нескольких GPU/TPU:
https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html
Приводят результаты тестирования библиотеки для обучения своей Амебы - монстроподобной SOTA-модели на задаче ImageNet.
То есть, Lingvo может подойти и не только NLP задач.